-
[논문리뷰]28. BATCH PROMPT: ACCOMPLISH MORE WITH LESS논문 2024. 8. 31. 12:04
INTRODUCTION
LLM의 발전은 수만 개의 토큰으로 이루어진 긴 텍스트를 처리할 수 있게 하였으며, 이는 수많은 전통적인 NLP작업에 적용하기에 충분
많은 LLM은 Instruction-Based Prompts를 사용하여 zero-shot/few-shot inference을 수행하도록 훈련/미세 조정
LLM을 위한 프롬프트를 작성하려면 일반적으로 사용자가 세부적인 작업 설명, 맥락과 완성 예, 추론을 위한 단일 맥락 예를 제공해야 함
이 규칙적인 프롬프트 기준은 이 논문에서 "SinglePrompt"라고 함
각 추론 데이터 포인트가 반드시 길지 않은 NLP 작업의 경우, 프롬프트에서 명령과 소수샷 예의 토큰 수가 데이터 포인트보다 훨씬 더 많아질 수 있으며, 이는 미세 조정된 BERT와 같은 인코더 기반 모델에 비해 토큰 자원의 활용도를 낮추게 됨
이러한 비용 효율성 문제는 추론 속도와 계산 예산에 영향을 미치며, LLM이 제공할 수 있는 많은 이점을 상쇄시킴
"데이터 포인트"는 LLM이 처리해야 할 개별적인 데이터 사례를 의미
예를 들어, 논문에서 언급된 BoolQ, QQP, RTE와 같은 데이터셋에서는 각각의 질문-답변 쌍(Q&A pair)이나, 텍스트의 전제와 가설(Premise and Hypothesis) 쌍이 하나의 "데이터 포인트"가 됨
각 "데이터 포인트"는 LLM이 예측을 해야 하는 단위로, 하나의 입력으로 들어가는 각각의 사례를 의미
논문에서는 이 데이터 포인트를 여러 개 모아 배치(batch)로 처리하는 "BatchPrompt"라는 기법을 제안
"데이터 포인트"는 LLM이 한 번에 여러 개의 사례를 처리할 수 있도록 배치 내에 포함된 각각의 개별 데이터를 가리키는 용어가정해보면, 어떤 NLP 작업에서 텍스트 분류를 수행해야 한다고 합시다. 모델은 "긍정" 또는 "부정"으로 문장을 분류해야 합니다.
1. 입력 데이터 포인트
- 입력 문장: "This movie was great."
- 토큰 수: 5 (영어 기준으로 각 단어가 하나의 토큰으로 간주됨)
2. 프롬프트와 소수샷 예시 (Few-Shot Example)
프롬프트는 모델에게 어떻게 작업을 수행해야 하는지 알려주기 위해 제공되는 명령어 및 예시입니다. 예를 들어, GPT-3과 같은 모델에서는 다음과 같은 프롬프트를 사용할 수 있습니다:
Classify the sentiment of the following sentences as positive or negative.
Example 1: "I love this place." -> Positive
Example 2: "The food was terrible." -> Negative
Example 3: "This movie was great." ->
- 명령어 및 예시: 위의 프롬프트
- 토큰 수: 약 23 (각 단어와 기호가 토큰으로 간주됨)
결과
- 입력 데이터 포인트: "This movie was great." (5 토큰)
- 프롬프트와 예시: 약 23 토큰
이 상황에서 입력 데이터보다 프롬프트와 예시가 차지하는 토큰 수가 훨씬 많다는 것을 알 수 있음
입력 데이터보다 프롬프트의 비중이 더 커져, 모델이 실제 입력을 처리하는 데 사용하는 토큰 자원이 비효율적으로 사용된다는 의미
반면에, BERT와 같은 인코더 기반 모델은 입력 문장만을 인코딩하고, 프롬프트가 필요 없기 때문에 주어진 입력에만 집중할 수 있음이렇게 하면 모델이 사용 가능한 토큰 자원을 보다 효율적으로 활용할 수 있음
논문에서 주로 이야기하는 부분은 여러 데이터 포인트를 하나의 프롬프트로 일괄 처리(batch)하여 앞서 언급한 문제를 완화하려고 함
이러한 프롬프트 전략을 "BatchPrompt"라고 지칭
이 전략은 데이터 포인트의 "밀도"를 증가시켜 토큰 활용도를 개선하는 것이 목적
즉, 프롬프트에 포함된 개별 데이터 포인트(예: 질문이나 문장 쌍 등)의 양을 늘리는 것을 의미
여러 개의 데이터 포인트를 한 번에 모델에 입력하여 처리하면 프롬프트 내에 더 많은 데이터가 포함되므로 "밀도"가 증가그러나 BatchPrompt를 단순히 적용하면 성능이 크게 저하되는 것이 실험에서 관찰
프롬프트 내에서 다른 위치에 있는 동일한 데이터 포인트에 대해 다양한 추론 결과가 나타나는 것을 확인
"What is the capital of France?"라는 질문을 예로 설명
첫 번째 프롬프트:프롬프트: "What is the capital of France?" (첫 번째 위치)
모델의 답변: "Paris"
두 번째 프롬프트:프롬프트: "Who wrote '1984'?" + "What is the capital of France?" (중간 위치)
모델의 답변: "Paris"
세 번째 프롬프트:프롬프트: "Who wrote '1984'?" + "What is the largest planet?" + "What is the capital of France?" (마지막 위치)
모델의 답변: "London"높은 토큰 자원 활용도를 유지하면서 품질 문제를 해결하기 위해, 우리는 BatchPrompt를 위한 Batch Permutation and Ensembling(BPE)을 도입해, 배치 내 다양한 위치에 배치된 데이터 포인트에서 다수결을 통해 라벨링 품질을 회복하는 간단한 방법을 제안
투표 과정에서 추가적인 토큰 사용이 발생하는 것을 균형 있게 조정하기 위해, 우리는 LLM이 자신 있게 처리하는 데이터 포인트에 대해 투표 과정을 조기에 종료할 수 있는 Self-reflection-guided Early Stopping(SEAS)을 제안
포괄적인 실험적 평가 결과는, BPE + SEAS가 BatchPrompt의 성능을 크게 향상시킬 수 있으며, 이는 질문 응답(Boolq), 텍스트 함의(RTE), 중복 질문 식별(QQP)과 같은 인기 있는 NLP 작업에서 SinglePrompt와 비교해도 경쟁력 있으며, BatchPrompt는 훨씬 적은 LLM 호출과 입력 토큰을 필요로 한다는 것을 증명
(SinglePrompt 대 BatchPrompt+BPE +SEAS, 배치 크기 32, Boolq 정확도 90.6% → 90.9%, 27.4% 토큰 사용, QQP 정확도 87.2% → 88.4%, 18.6% 토큰 사용, RTE 정확도 91.5% → 91.1%, 30.8% 토큰 사용).
해당 논문이 나온 이유...?
과거 LLM은 입력된 데이터의 위치에 따라 결과가 달라짐
이는 모델이 입력된 프롬프트의 특정 위치에 더 많은 중요성을 부여하고, 뒤쪽의 입력은 상대적으로 덜 중요하게 취급하는 경향으로 인해서...
예를 들어, 프롬프트의 앞부분에 있는 데이터 포인트는 더 정확하게 처리되지만, 중간이나 끝부분에 있는 데이터는 덜 정확하게 처리
LLM을 다양한 실용적인 응용 프로그램에 적용하는 경향, 응용 프로그램에는 대화형 인터페이스, 질문 응답, 문맥 요약 등이 포함
작업은 주로 프롬프트를 통해 수행
작업 명세와 데이터가 언어 모델에 대한 입력 컨텍스트로 결합되어, 완성된 텍스트를 생성
이 입력의 길이는 수백에서 수천 개의 토큰에 이를 수 있음
이러한 경향은 단일 데이터 샘플만을 입력으로 포함하는 것이 프롬프트 설정에서 효율적인지에 대해 생각하게 함
긴 컨텍스트 입력을 처리하는 것은 Transformer로 구현된 대규모 언어 모델에게 쉽지 않은 일
Transformer는 긴 시퀀스에 대해 성능이 저하되며, 이는 언어 모델의 성능 저하로 이어짐
그 이유는 Transformer의 Self-Attention 모듈의 복잡도가 입력 길이에 따라 제곱적으로 증가하기 때문
일괄 처리된 데이터를 사용한 프롬프트는 필연적으로 입력 길이를 늘리게 되며, 이는 성능 저하로 이어질 수 있으므로, 데이터를 단순히 일괄 처리하는 대신 더 나은 배치 프롬프트 전략을 찾는 것이 필요
실험을 통해 데이터가 다른 위치와 순서에 있을 때 LLM의 성능이 크게 달라진다는 것을 관찰
Fig. 1에서 데이터 인덱스를 오름차순으로 표시한 것처럼 나타남
성능 변화는 LLM 디코더의 autoregressive 특성 때문일 수 있으며, 이는 이전 출력에 따라 각 출력 토큰을 예측
각 답변이 서로 다른 컨텍스트에서 생성되며, 원래 작업 명세와 데이터까지의 토큰 거리가 다르다는 것을 의미
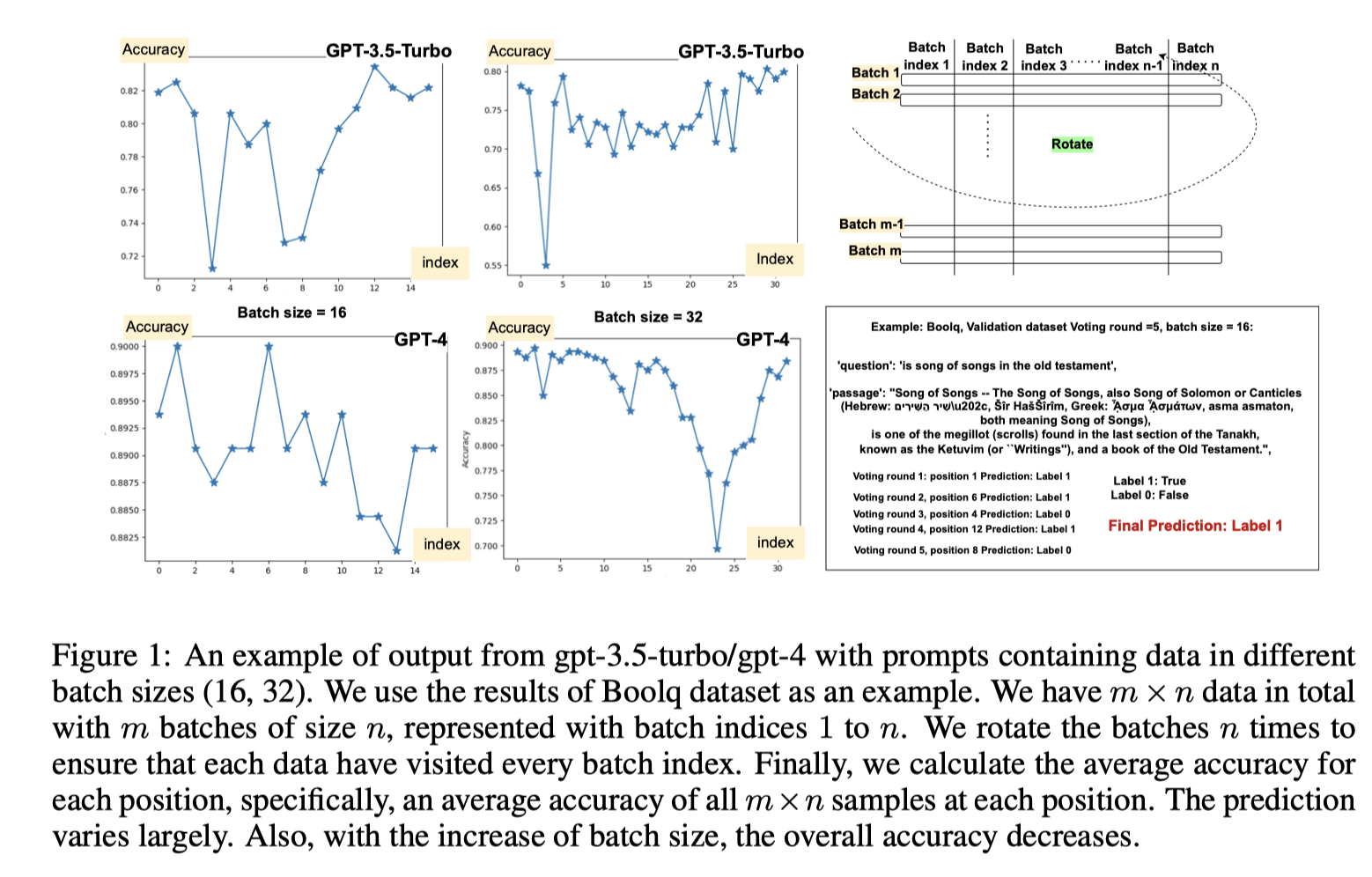
LLM이 데이터 포인트의 위치에 따라 성능이 어떻게 달라지는지, 그리고 이를 보완하기 위해 Batch Permutation과 같은 전략이 어떻게 사용될 수 있는지를 시각적으로 설명
특히, Batch size가 커질수록 이 문제는 더 심각해지므로, Batch Permutation과 다수결을 통한 최종 결과 도출이 매우 중요한 역할을 함이러한 관찰을 바탕으로, BatchPrompt의 성능을 향상시키기 위해 Batch Permutation and Ensembling(BPE)을 제안
이 방법은 동일한 데이터를 다양한 순서로 조합하여 여러 배치에 대해 일관된 LLM 출력을 생성하는 것이 더 유망하다는 직관을 활용
구체적으로, 데이터 시퀀스를 원래 순서대로 샘플링하는 대신, 각 배치에서 데이터를 변형(순열)
서로 다른 순서로 배치된 배치의 LLM 출력은 다르며, 앙상블은 다수결 투표를 통해 이루어집니다.
기존에 데이터에 주석을 달고 추가 모델을 훈련시키는 방법과 비교하여, BPE는 훨씬 간단하며 사전 훈련된 LLM과 함께 바로 사용할 수 있음
또한, 앙상블 학습과는 달리, BPE는 단일 언어 모델 위에서 작동하는 "자체 앙상블링"으로 볼 수 있습니다.
1. 데이터 시퀀스의 순열(Sampling and Permutation)
데이터 시퀀스를 순열한다는 것은, 데이터를 원래의 순서대로 모델에 입력하는 대신, 그 순서를 바꾸어서 여러 번 모델에 입력한다는 것을 의미
예를 들어, 만약 3개의 데이터 포인트(A, B, C)가 있다면, 이를 모델에 입력할 때 원래 순서대로 입력하면 "A → B → C"가 되겠지만, 이를 순열하면 "B → A → C" 또는 "C → B → A"와 같은 다른 순서로도 입력
2. 다른 순서로 배치된 배치의 출력 차이
모델은 입력된 데이터의 순서에 따라 다르게 반응
예를 들어, A가 첫 번째 위치에 있을 때와, 두 번째 또는 세 번째 위치에 있을 때 모델이 생성하는 출력이 달라질 수 있음
BPE에서는 이러한 서로 다른 순서로 데이터를 배치하여 여러 번 모델을 실행한 후, 각 실행에서 얻은 출력을 비교
3. 앙상블과 다수결 투표
앙상블(Ensemble)은 여러 모델의 출력을 결합하여 최종 출력을 만드는 방법
예를 들어, 여러 모델이 각각의 예측을 하고, 이 예측들 중에서 가장 많이 나온 답변을 최종 답변으로 선택하는 방식
이는 모델의 예측 정확도를 높이기 위한 일반적인 방법
BPE에서는 여러 번의 순열된 입력에 대해 모델의 출력을 얻은 후, 이들 출력을 비교하고 다수결 투표를 통해 최종 출력을 결정
즉, 각 순서에서 모델이 예측한 결과 중 가장 많이 나온 결과를 최종 답변으로 선택하는 것입니다.BatchPrompt의 궁극적인 목표는 더 적은 토큰과 LLM 호출로 더 많은 데이터 처리를 달성하는 것
효율성의 관점에서, LLM 호출 수가 크게 감소하며, 총 토큰 수의 감소는 작업 명세와 데이터의 토큰 비율, 그리고 투표 라운드 수에 따라 달라진다는 것을 발견
일반적으로, BPE에서 Voting Round 수가 10보다 적고 배치 크기가 64보다 클 때 사용된 토큰 수가 현저히 감소하는 것을 발견
더 큰 배치 크기와 적은 투표 라운드는 절약성을 높일 것
성능 측면에서, BatchPrompt의 정확도는 투표 라운드 수가 5 이상일 때 단일 데이터 프롬프트와도 경쟁력
여러 투표 라운드를 사용하면서도 절약성을 더욱 높이기 위해, Self-reflection-guided Early Stopping(SEAS) 방법을 제안
LLM에게 Prediction과 함께 Confidence Label을 제공하도록 유도하여 가능한 경우 더 짧은 투표 라운드를 권장
특정 데이터에 대해 연속적으로 "자신감 있음" 평가가 반환되면, 해당 데이터에 대한 추가 투표가 불필요할 수 있으며, 예측을 조기에 중단
이로 인해 약 80%의 데이터가 두 번의 투표 라운드 내에 응답될 수 있으며, 사용된 총 토큰 수를 낮게 유지할 수 있음
SEAS의 부가적인 이점으로 예측 정확도의 향상도 실험에서 입증
다양한 작업에 대해 BatchPrompt와 BPE 및 SEAS의 효과를 철저히 입증하였으며, 이 작업들은 Glue와 Super Glue 벤치마크(Boolq, QQP, RTE) 데이터셋을 사용, GSM8K에도 BatchPrompt를 확장하여 작은 부수 실험을 진행
제안된 방법의 효과를 보여주는 구체적인 예로는, Batch Size 32와 5번의 Voting Round에서 Boolq, QQP, RTE의 총 사용된 토큰 수가 각각 72.6%, 81.4%, 69.2% 감소했으며(여기서 토큰은 모두 입력 토큰을 의미하며, LLM이 생성한 출력 토큰은 통제할 수 없으므로 포함되지 않음), LLM 호출 수는 각각 84.4%, 90.6%, 84.4% 감소
그리고 정확도는 SinglePrompt(단일 데이터 프롬프트)와 경쟁할 수 있는 수준으로, 각각 90.6% → 90.9%, 87.2% → 88.4%, 91.5% → 91.1%로 나타남
BatchPrompt
일반적인 프롬프트는 Task Specification와 Processed or Label Data를 포함데이터를 하나씩 처리하는 것은 비효율적이며, 배치를 사용하는 것이 더 효율적
그러나 프롬프트의 길이가 증가하면 성능이 그에 따라 감소하는 것을 발견
이 한계를 극복하기 위해, Batch Permutation and Ensembling (BPE) 방법을 제안
이 방법은 각 배치에 대해 데이터를 다른 순서로 사용하여 여러 번의 Voting Round를 반복
LLM이 다양한 순서로 배치된 데이터를 처리할 수 있다고 가정하는 것이 자연스럽고, 이 다양성을 순열을 통해 유도
모델이 특정 투표 라운드의 특정 위치에 있는 일부 데이터에 대해 실수를 할 수 있지만, 이러한 잘못된 답변이 동일할 가능성은 적음
반면, 다양한 투표 라운드에서 다른 위치에 있는 특정 데이터에 대해 생성된 올바른 답변은 잘못된 답변보다 더 큰 일치를 보이는 경향
개념적으로 생각해보면, 사람들이 서로 다른 정보에 대해 우선순위를 매기고 서로 다른 주의를 기울일 때, 각 정보는 다른 정보에 독특한 영향동일한 것이 LLM이 데이터를 배치로 처리할 때에도 적용될 수 있음
문제를 다음과 같이 공식화
현재 배치의 데이터 크기가 \(N\)일 때, 데이터를 \(D = \{d_1, d_2, \dots, d_N\}\)이라 하고, 각 데이터에 대한 답변을 \(A = \{a_1, a_2, \dots, a_N\}\)이라 하며, \(K\)개의 순열에서의 순서를 \(S = \{s_1, s_2, \dots, s_K\}\)
\[
\text{argmax}_a \sum_{k=1}^{K} \mathbb{1}(a_n^k = a), \quad \forall n \in \{1, 2, \dots, N\}
\]
그러나, 다른 순열에서는 데이터 \(d_n\)에 대한 답변 \(a_n\)이 작업 명세뿐만 아니라 \(\{a_1, a_2, \dots, a_{n-1}\}\)에 의해서도 조건이 결정되며, 이는 \(a_n\)의 문맥으로 볼 수 있습니다. 따라서, 우리는 다수결 투표를 다음과 같이 더 공식화
\[
\text{argmax}_a \sum_{k=1}^{K} \mathbb{1}(a_n^k = a \mid \text{prompt}, a_1^k, a_2^k, \dots, a_{n-1}^k), \quad \forall n \in \{0, 1, 2, \dots, N\}
\]
이 방정식에서 알 수 있듯이, 데이터 \(d_n\)에 대한 출력 답변 \(a_n\)은 문맥의 변화로 인해 다른 순열에서 달라질 수 있음BPE를 사용한 BatchPrompt가 SinglePrompt보다 더 나은 성능을 발휘할 수 있는 이유를 설명
추가로 LLM 자체에서 가중치를 생성하여 추가적인 훈련을 피하는 가중치가 부여된 다수결 투표 방법을 연구이 과정을 'self-weighted majority voting (sw-mv)'라고 부르며, Fig. 2에서 예시를 제공
Shinn 등(2023)의 Reflexion 아이디어에서 영감을 받아, Task Specification에 다음과 같은 텍스트를 추가
"출력 클래스에 자신이 있다면 라벨 끝에 'confident'를 붙이세요; 그렇지 않으면 'not confident'를 붙이세요."
이것은 LLM이 자동으로 이진 가중치를 생성하도록 함
생성된 답변이 "confident"일 경우 가중치를 \(w = 1\)로 설정하고, "not confident"일 경우 \(w = \alpha\)로 설정하며, 여기서 \(\alpha \in [0, 1]\)입니다. 실험에서 \(\alpha\)를 0.2로 설정
self-weighted majority voting을 다음과 같이 공식화할 수 있음
\[
\text{argmax}_a \sum_{k=1}^{K} w_n \cdot \mathbb{1}(a_n^k = a \mid \text{prompt}, a_1^k, a_2^k, \dots, a_{n-1}^k), \quad \forall n \in \{0, 1, 2, \dots, N\}
\]
더 많은, 더 정교한 투표 전략을 구상하고 있지만, 이번 작업에서는 일반적인 다수결 투표(mv)와 self-weighted majority voting(sw-mv)에 초점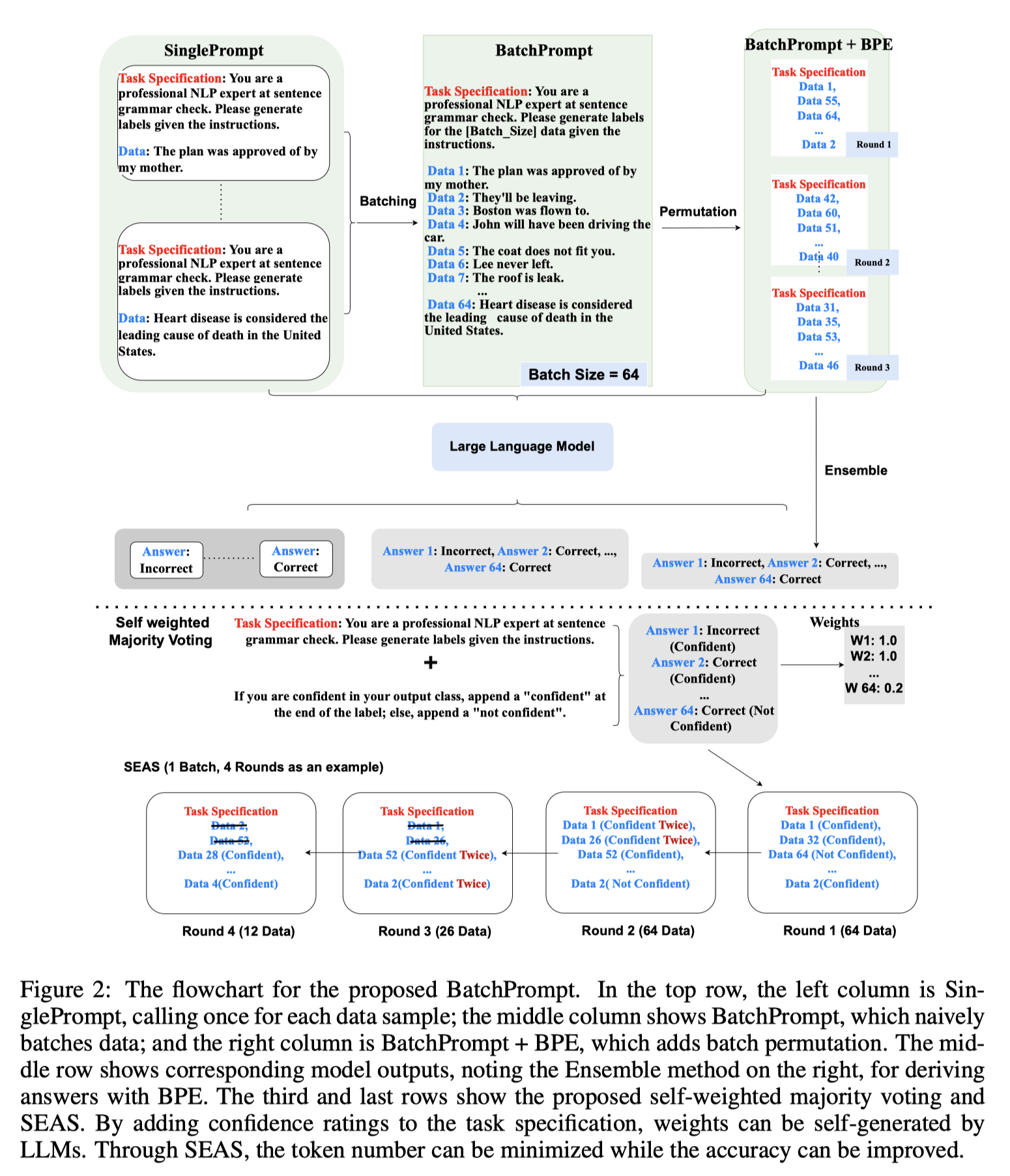
SEAS
제안된 self-weighted majority voting(sw-mv)에 대한 깊은 고찰은 'Self-reflection-guided EArly Stopping(SEAS)'이라고 부르는 더욱 공격적인 효율성 전략을 가능하게 함
배치에 쉬운 데이터 샘플이 포함되어 있을 때, 여러 번 투표를 계속하기보다는 반복되는 "confident" 라벨을 활용하여 해당 샘플에 대한 절차를 조기에 종료
그 결과, 실질적인 배치 크기가 줄어들고, 최대 투표 라운드 수보다 더 짧아지면서도 높은 정확도를 유지
이 방법은 알고리즘 1에서 pseudo-code로 설명
Pseudo-code(또는 의사 코드)는 알고리즘이나 프로그램의 로직을 표현하는 방법 중 하나
이것은 실제 프로그래밍 언어의 문법을 사용하지 않고, 사람에게 읽기 쉽게 작성된 코드와 같은 형식의 설명
즉, 의사 코드는 특정 프로그래밍 언어에 의존하지 않으며, 알고리즘의 핵심 아이디어와 흐름을 설명하기 위해 사용SEAS 방법은 토큰 수를 효과적으로 줄일 뿐만 아니라 정확도를 향상시킬 수도 있음
Voting Round가 계속될수록, 쉬운 샘플이 더 빨리 제거되며, 이후 라운드에는 더 적고 어려운 샘플이 남게 됨
어려운 샘플들은 나중 라운드에서 배치 크기가 더 작아지면서 예측이 더 쉬워질 수 있음
예를 들어, 첫 번째 투표 라운드에서 배치 크기는 32
그러나 다섯 번째 투표 라운드에 이르면 일관된 "confident" 예측이 없는 2개의 어려운 샘플만 남아 있을 수 있음
LLM은 이제 이 2개의 샘플에 대한 라벨/답변을 예측해야 하며, 이는 32개의 샘플이 일괄 처리된 예측보다 더 정확할 수 있음
한 가지 대안은 쉬운 샘플이 완료될 때마다 각 배치를 전체 배치 크기로 채우는 것이지만, 이는 작은 배치로 어려운 샘플을 예측하는 부가적인 이점을 포기하는 것이며, SEAS에서는 선택되지 않았습니다.

4. EXPERIMENTS
실험 4.1 실험 설정
작업과 데이터셋:
여러 NLP 작업에 대해 실험을 수행했으며, 여기에는 질문 응답(Boolq), 중복 텍스트 식별(QQP), 텍스트 함의(RTE)가 포함
- Boolq: Boolean Questions (Boolq)은 예/아니요 질문에 대한 질문 응답 데이터셋으로, 15,942개의 예시를 포함하고 있습니다(훈련용 9,427개, 검증용 3,270개, 테스트용 3,245개). 각 예시는 (질문, 본문, 답변)의 삼중항으로 구성됩니다. 질문과 본문이 입력 프롬프트로 사용되며, 답변을 생성합니다.
- QQP: Quora Question Pairs (QQP) 데이터셋(Wang et al., 2017)은 400,000개 이상의 질문 쌍으로 구성되며, 각 질문 쌍은 두 질문이 서로 패러프레이즈(의미가 동일한 문장)인지 여부를 나타내는 이진 값으로 주석이 달려 있습니다. 질문 쌍이 입력 프롬프트로 사용되며, 레이블이 생성됩니다.
- RTE: Recognizing Textual Entailment (RTE) 데이터셋(Poliak, 2020)은 일련의 텍스트 함의 챌린지에서 가져온 것입니다. RTE1, RTE2, RTE3, RTE5의 데이터를 결합한 이 데이터셋은 훈련용 2,490개, 검증용 277개, 테스트용 3,000개의 샘플을 포함하고 있습니다. 각 데이터는 전제(premise)와 가설(hypothesis)로 구성된 입력 프롬프트와 생성된 출력 레이블을 포함합니다. 이 레이블은 전제가 가설을 함의하는지를 나타냅니다.
1. gpt-3.5-turbo(ChatGPT)/GPT-4를 사용하여 민감한/유해한 콘텐츠를 필터링
2. LLM 호출에 대한 제한된 할당량 때문에, 각 데이터셋에서 무작위로 검증 세트에서 320개의 데이터를 선택하여 실험을 수행(RTE의 경우 총 277개의 검증 샘플만 있기 때문에 277개를 선택). BoolQ, QQP, RTE의 테스트 세트는 주석이 공개되지 않았기 때문에 사용하지 않음
언어 모델 및 프롬프트: BatchPrompt와 BPE를 두 가지 서로 다른 규모의 Transformer 기반 언어 모델(gpt-3.5-turbo(ChatGPT)와 GPT-4)에서 평가
파라미터: 우리는 모든 실험을 훈련이나 미세 조정 없이 몇 샷(few-shot) 설정으로 수행
RTE, QQP, BoolQ에 대해 각각 2, 4, 4개의 few-shot 예시를 사용하며, 이는 모두 주어진 라벨이 있는 훈련 세트에서 선택
Zhao et al.(2021)이 언급했듯이, few-shot 예시의 순열을 변경하면 GPT-3의 정확도가 낮은 수준에서 최첨단 수준에 이를 수 있음
또한, 예시의 라벨에 "confident" 또는 "not confident"을 수동으로 할당
일관된 결과를 얻기 위해 Temperature는 항상 0으로 설정, 비교를 위해, 우리는 다양한 데이터셋에 대해 유사한 프롬프트를 사용
RTE, QQP, BoolQ에 대해 GPT-4의 최대 입력 토큰 수가 32k인 경우 배치 크기는 16/32/64/160을 사용하며, gpt-3.5-turbo의 최대 입력 토큰 수가 8k인 경우 16/32를 사용
선택한 투표 라운드 수는 1, 3, 5, 7, 9이며, 이는 모두 동점 투표 상황을 피하기 위해 홀수
4.2 BatchPrompt + BPE의 결과
복잡성 비교: 우리는 토큰 수와 LLM 호출 수를 사용하여 복잡성을 비교
Fig. 3에서 알 수 있듯이, 9번의 투표 라운드에서도 LLM 호출 수가 크게 감소
SEAS를 적용한 BatchPrompt도 마찬가지입니다.
SEAS가 없는 경우, 토큰 수는 투표 라운드 증가에 따라 선형적으로 증가
모든 세 가지 작업에서, BatchPrompt의 토큰 수는 투표 라운드가 1일 때 SinglePrompt의 1/5에 불과하지만, 9번 이상의 투표 라운드를 사용하면 그 토큰 수가 SinglePrompt를 초과할 수 있음
이는 토큰 절약의 관점에서 SEAS의 중요성을 강조
그러나 SEAS 없이 BatchPrompt가 항상 SEAS가 적용된 BatchPrompt보다 더 나은 정확도를 생성하지는 않는다는 것을 주목해야 함
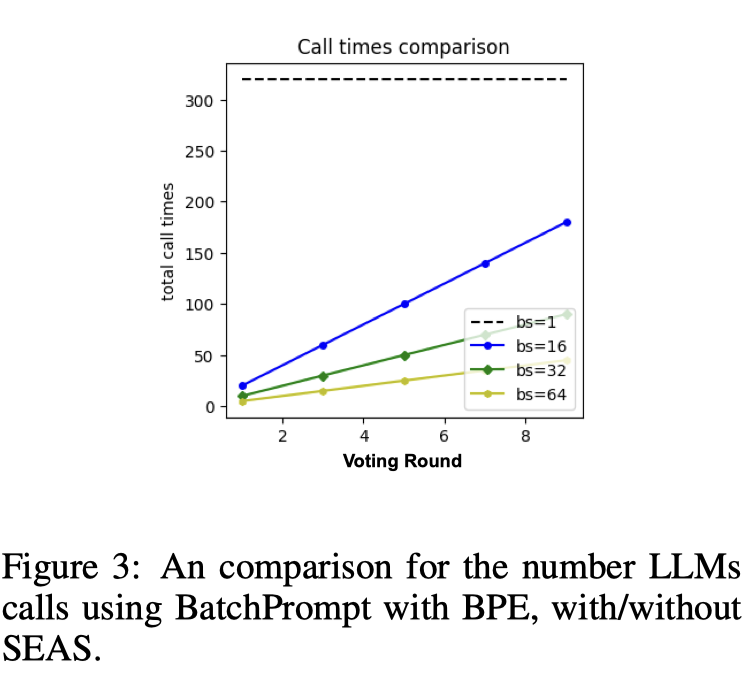

정확도 비교: 결과는 표 1, 2, 3에 제시
1. 더 큰 배치 크기를 사용한 프롬프트는 일반적으로 더 나쁜 결과
배치 크기가 64일 때, 모든 데이터셋에서 한 번의 투표 라운드로는 정확도가 크게 감소하지만, 5번 이상의 투표 라운드에서 SinglePrompt와 유사한 수준으로 증가
2. 투표 라운드가 많아지더라도 정확도가 항상 일관되게 증가하지는 않음
이는 어려운 샘플에서 잘못된 라벨이 누적되기 때문, 그러나 SEAS를 도입하면 이러한 현상이 완화되며, 다음 섹션에서 볼 수 있듯이 투표 라운드가 많아질수록 정확도가 일관되게 상승
3. BatchPrompt는 gpt-3.5-turbo보다 GPT-4에서 더 잘 작동
이는 다수결 투표의 고유한 한계 때문
만약 gpt-3.5-turbo에서처럼 정확도가 충분히 높지 않다면, 잘못된 예측이 더 많은 투표 라운드에서 누적될 것
따라서 BPE가 충분히 효과적일 수 없음, 이로 인해, 작업의 전반적인 정확도가 매우 낮다면(30% 이하), BatchPrompt가 적용되지 않을 수 있음을 알 수 있음
4. BatchPrompt와 SEAS를 비교한 결과, SEAS 없이 BatchPrompt가 더 높은 토큰 수에도 불구하고 더 나은 정확도를 얻을 수 있음
예를 들어, RTE의 경우 최고 정확도는 92.9%였으며, SEAS가 추가되었을 때는 91.7%에 불과
이는 SEAS가 쉬운 샘플에 대해 투표 라운드 수를 줄이기 때문이며, 이러한 샘플이 두세 번의 투표 라운드에만 포함될 수 있기 때문입니다. 이러한 쉬운 샘플에 대해 예측된 라벨/답변이 잘못될 수 있음
배치 크기가 64 미만일 때: 표 1-3에서 알 수 있듯이, BatchPrompt는 투표 라운드가 하나만 있더라도 SinglePrompt에 비해 좋은 정확도를 보여줍니다. 더 많은 투표 라운드는 토큰 수를 증가시키지만, 정확도는 비례적으로 향상되지 않습니다. 따라서 이 경우 연구자가 효율성을 더 중시한다면, BPE 없이 BatchPrompt를 사용하는 것을 권장합니다. 그러나 정확도가 가장 중요하다면, 우리는 여전히 더 많은 투표 라운드를 권장합니다. 낮은 배치 크기의 BatchPrompt + BPE는 SinglePrompt보다 더 나은 성능을 발휘할 수 있습니다(Boolq: 90.6%-90.9%, RTE: 91.45%-92.9%, QQP: 87.2%-87.8%).
배치 크기가 64 이상일 때: 최신 LLM의 경우 토큰 제한이 크게 증가하며, 이는 당연한 추세입니다. 결과에서 볼 수 있듯이, 배치 크기가 64 이상일 때, BatchPrompt는 BPE 없이는 제대로 작동하지 않으며, 대부분의 경우 정확도가 SinglePrompt보다 훨씬 낮습니다. 예를 들어, Boolq에서의 정확도는 72.8%에 불과한 반면, SinglePrompt의 정확도는 90.6%입니다. 그러나 더 많은 투표 라운드를 통해 BatchPrompt의 정확도는 86.3%까지 원활하게 증가할 수 있으며, 이는 SinglePrompt와 경쟁력이 있습니다.
부정적(few-shot) 예시: 표에서 우리는 부정적(few-shot) 예시가 포함된 self-weighted majority voting(sw-mv-neg)의 결과도 보여줍니다. 올바른 답변이 있는 few-shot 예시가 모두 "confident" 라벨을 가지고 있다면, LLM은 "not confident" 사례가 없어지며 약 90%의 "confident" 평가를 제공한다는 것을 알 수 있습니다. 따라서 실험의 완전성을 위해 각 실험에 두 개의 부정적 few-shot 예시를 추가합니다. 구체적으로, 부정적 few-shot 예시의 라벨/답변은 잘못된 것으로, 뒤따라 "not confident"가 붙습니다. 결과 표에서 "sw-mv-neg"가 "sw-mv"보다 더 나쁜 결과를 얻는다는 것을 확인할 수 있습니다. 우리의 결론은 "not confident" 사례가 주어진다고 해도, 부정적 few-shot 예시의 존재는 LLM이 라벨/답변에 대해 잘못된 가이드를 제공하며, 이는 LLM의 판단에 더 큰 영향을 미친다는 것입니다. 부정적 few-shot 예시의 더 나은 선택이 향후 연구에서 도움이 될 수 있습니다.
4.3 RESULTS FOR BATCH PROMPT + BPE + SEAS

일반 결과: Fig. 4에서 BatchPrompt + BPE + SEAS의 결과를 보여줌. 마지막 두 열에서 볼 수 있듯이, LLM 호출 수와 토큰 수는 SinglePrompt(검은 선)보다 훨씬 낮음.
훨씬 적은 토큰을 사용하면서도 BatchPrompt + BPE + SEAS의 전체 정확도는 SinglePrompt와 경쟁력이 있음.
BatchPrompt + BPE + SEAS가 최적의 프롬프트 전략을 제공한다고 믿음.
또한, SEAS가 적용되었을 때, 토큰 수는 투표 라운드 3 이후에 서서히 증가하는 것을 알 수 있음.
이는 대부분의 쉬운 데이터에서 두 번 연속으로 일관된 답변 요구사항이 이미 초기 단계에서 충족되었음을 의미합니다. 이것이 SEAS가 효과적으로 토큰을 절약할 수 있는 이유
차이점 연구(Ablation Study): SEAS와 마찬가지로, 라운드 3부터 각 라운드는 배치 크기의 감소를 가져오며, 이는 예측 정확도의 증가를 동반할 수 있습니다. 자기 성찰의 효과를 입증하기 위해, BatchPrompt + BPE + SEAS(노란 선)와 BatchPrompt + BPE + 랜덤 드롭(green line)의 결과를 비교합니다. 정확도를 비교한 결과는 Fig. 5에 나와 있습니다. 또한, BatchPrompt + BPE의 결과도 비교를 위해 포함합니다.
'논문' 카테고리의 다른 글
[논문리뷰]30. CHAIN-OF-NOTE (2) 2024.09.11 [논문리뷰]29. Mixture-of-Agents Enhances Large Language Model Capabilities (4) 2024.09.08 [논문리뷰]27. SELF-RAG: LEARNING TO RETRIEVE, GENERATE, AND CRITIQUE THROUGH SELF-REFLECTION (0) 2024.08.24 26. Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks (0) 2024.08.24 25. Chain of Table (0) 2024.08.14