-
25. Chain of Table논문 2024. 8. 14. 11:39
테이블에 관하여 COT를 적용한 논문이 있어 정리하고자 작성~~
표 데이터를 위한 LLM은 Table QA 작업을 해결하는 유망한 방향
자유 형식의 질문과 반구조화된 표 데이터에서 기본적인 의미를 추출하는 것을 요구Chain-of-Thought 접근법은 텍스트 컨텍스트의 형태로 추론 체인을 통합하지만, 표 데이터를 Chain을 통해 효과적으로 활용하는 방법은 아직 명확하지 않았음
Chain of Thought와 비슷한 방법론을 표를 중간 단계에 사용하는 Chain-of-Table 프레임워크를 제안
구체적으로, LLM을 사용하여 In-Context Learning을 통해 반복적으로 연산을 생성하고 표를 업데이트하여 표 기반 추론 체인을 의미
LLM은 이전 연산의 결과를 기반으로 다음 연산을 동적으로 계획할 수 있음
표에 관한 Chain 형성해서 주어진 표 문제에 대한 추론 과정을 보여줌
Chain 중간 결과의 구조화된 정보를 전달하여 더 정확하고 신뢰할 수 있는 예측을 가능하게 함
In-Context Learning
모델이 훈련되지 않은 새로운 작업을 수행할 때, 기존에 학습한 내용을 활용하여 적절한 출력을 생성하는 능력
쉽게 말해, 별도의 재학습이나 fine-tuning 없이 모델이 제공된 입력(컨텍스트)에 따라 즉석에서 학습하여 작업을 수행하는 것
In-Context Learning의 작동 방식
사전 학습(pre-training) 과정에서 방대한 양의 데이터를 사용하여 다양한 패턴과 지식을 학습
모델이 특정 작업에 대해 명시적으로 훈련되지 않았더라도, 해당 작업과 유사한 예시를 모델에게 제공하면, 모델이 그 예시를 기반으로 새로운 입력에 대해 적절한 출력을 생성할 수 있음
다음과 같은 단계
1) 컨텍스트 제공 : 모델에게 몇 가지 예시를 제공, 이 예시는 작업의 입력과 출력 쌍으로 구성
2) 새로운 입력 제시 : 모델에게 새로운 입력을 제시, 이 입력은 앞서 제공된 컨텍스트와 동일한 유형의 작업에 속함
3) 출력 생성 : 모델은 제공된 컨텍스트를 기반으로 새로운 입력에 대해 적절한 출력을 생성
In-Context Learning 예시
예를 들어, 모델에게 영어 문장을 한국어로 번역하는 작업을 시키고자 한다고 가정, 다음과 같은 컨텍스트를 모델에게 제공
Input: I love you. -> Output: 나는 너를 사랑해.
Input: Thank you. -> Output: 고마워.
Input: How are you? -> Output: 잘 지내?
이제 모델에게 새로운 입력을 제시
Input: Good morning.
모델은 이전에 제공된 컨텍스트를 기반으로 새로운 입력에 대한 출력을 생성
Output: 좋은 아침.
이처럼, 모델은 별도의 번역 작업에 대해 명시적으로 훈련되지 않았더라도, 제공된 예시를 기반으로 번역 작업을 수행할 수 있음
In-Context Learning (ICL)과 Chain of Thought (CoT)의 관계
ICL은 모델이 제공된 컨텍스트(즉, 예시)를 기반으로 학습하여 새로운 입력에 대해 적절한 출력을 생성하는 방식
CoT는 이러한 ICL의 한 형태로 간주될 수 있음
CoT는 ICL을 활용하여 단계별로 추론을 학습하는 데 사용될 수 있음
예를 들어, 이전에 제공된 예시에서 단계별로 문제를 해결하는 과정을 보여준다면, 모델은 새로운 문제에 대해서도 비슷한 방식으로 접근CHAIN-OF-TABLE은 여러 LLM 선택에서 WikiTQ, FeTaQA 및 TabFact 벤치마크에서 새로운 최첨단 성능을 달성
언어 모델을 사용하여 표 데이터를 이해하면 표 기반 사실 확인 및 표 기반 질문 응답과 같은 다양한 다운스트림 작업에 도움
순수 텍스트와는 달리 표는 행과 열 간의 상호작용을 통해 풍부한 정보를 전달하여 데이터 용량을 향상시키지만, 언어 모델이 이를 이해하기 어려움
최근 몇 년간 언어 모델을 훈련시켜 표 이해 문제를 해결하기 위한 여러 접근법이 제안되었음
1. 언어 모델에 특수한 임베딩 레이어나 self-attention을 추가하고, 표 셀이나 세그먼트를 복원하여 모델을 사전 훈련.
이렇게 하면 사전 훈련된 모델이 표 구조를 인식
이 접근법은 표 구조를 이해할 수 있는 특수한 모델을 설계하는 것
이를 위해 표의 셀(cell)이나 세그먼트(segment)를 모델이 인식할 수 있도록 임베딩 레이어나 self-attention 메커니즘을 추가
이렇게 하면 모델은 단순히 텍스트를 처리하는 것뿐만 아니라, 표의 구조와 관계도 이해함
- 문제 상황:
모델이 주어진 표에서 특정 정보를 추출하거나 이해해야 하는 상황을 가정
예를 들어, 주어진 표에서 "2023년 매출이 가장 높은 제품"을 찾는 문제 - 표:
제품 이름 2021 매출 2022 매출 2023 매출 제품 A 5000 7000 9000 제품 B 4500 7500 8500 제품 C 6000 8000 9500 - 모델 작동 방식: 특수한 임베딩 레이어를 통해 모델이 각 셀의 위치와 그 의미(예: "제품 이름", "2023 매출" 등)를 인식
self-attention 메커니즘은 표의 각 요소 간의 관계를 학습하여, "2023년 매출이 가장 높은 제품"이라는 질문에 대해 올바르게 답할 수 있도록 함 - 결과: 모델은 표 구조를 인식하고, "2023년 매출" 열에서 가장 높은 값을 찾고, 그 결과, "제품 C"가 답으로 도출
2. SQL 쿼리-응답 쌍을 합성하여 인코더-디코더 모델을 신경 SQL 실행기로 사전 훈련하는 것
이 접근법은 언어 모델을 SQL 쿼리를 작성하고 실행할 수 있는 방식으로 사전 훈련시키는 것
모델이 데이터베이스의 쿼리를 생성하고 그 쿼리를 실행하여 올바른 답을 얻도록 학습예시:
- 문제 상황:
모델이 자연어로 된 질문을 SQL 쿼리로 변환하여 데이터베이스에서 올바른 정보를 가져와야 하는 상황
예를 들어, "2023년에 가장 높은 매출을 기록한 제품은 무엇인가?"라는 질문을 처리하는 문제 - SQL 데이터베이스:
-
CREATE TABLE 매출 ( 제품_이름 TEXT, 매출_년도 INT, 매출액 INT );
INSERT INTO 매출 VALUES ('제품 A', 2023, 9000);
INSERT INTO 매출 VALUES ('제품 B', 2023, 8500);
INSERT INTO 매출 VALUES ('제품 C', 2023, 9500); - 모델 작동 방식:
모델은 자연어 질문을 받아들인 후, 그 질문을 SQL 쿼리로 변환
예를 들어, 질문 "2023년에 가장 높은 매출을 기록한 제품은 무엇인가?"에 대해 모델은 다음과 같은 SQL 쿼리를 생성 -
SELECT 제품_이름 FROM 매출 WHERE 매출_년도 = 2023 ORDER BY 매출액 DESC LIMIT 1;
- 결과: 이 쿼리를 실행하면 모델은 "제품 C"라는 답을 반환
일련의 프롬프트 기술 연구는 Chain-of-Thought, Program-of-Thought 및 Tree-of-Thought와 같은 추론 체인을 설계하여 LLM의 신뢰성을 더욱 향상시켰음
다양한 연구에서는 LLM을 사용하여 표 기반 문제를 해결할 가능성도 탐구
그러나 이러한 접근법은 종종 자유 형식의 텍스트나 코드로 추론 단계를 나타내는데, 이는 복잡한 표를 다루는 시나리오에 적합하지 않음
반면, 표에 대한 추론은 일반적으로 일련의 중간 추론 단계를 포함하며, 각각은 특정 표 작업과 일치
CHAIN-OF-TABLE을 제안하여, 단계별 표 작업으로 표 체인을 형성하며 단계별 추론을 수행
CHAIN OF TABLE는 표 작업에 의해 변환된 표로, 중간 추론 결과를 나타냄
이 절차는 Chain-of-Thought의 추론 방식을 닮음
1. SQL 및 데이터프레임 개발에서 일반적으로 사용되는 열 추가, 행 선택, 그룹화 등의 표 작업 세트를 정의 2. 그런 다음 LLM을 사용하여 단계별 추론을 수행하도록 프롬프트 3. 각 단계에서 LLM은 다음 단계로서 연산과 필요한 인수를 동적으로 생성하고, 우리는 표에 연산을 프로그래밍 방식으로 실행 4. 이 연산은 세부 중간 결과를 추가하여 표를 풍부하게 하거나 관련 없는 정보를 제거하여 표를 간소화할 수 있음 5. 직관적으로, 중간 결과를 시각화하는 것은 정확한 예측에 필수적 6. 변환된 표를 다음 단계에 다시 사용 7. 이 반복 과정은 종료 상태에 도달할 때까지 계속 8. 추론 단계에서 얻어진 표가 자유 형식의 텍스트보다 중간 사고의 구조화된 표현 9. CHAIN-OF-TABLE 추론 결과는 LLM이 질문에 대한 최종 답변을 도출하기 더 쉬운 표로 나타남WikiTQ, TabFact 및 FeTaQA의 세 가지 표 벤치마크로 CHAIN-OF-TABLE을 검증하여 표 기반 추론을 평가
PaLM 2와 GPT-3.5, 오픈 소스 LLaMA 2를 사용하여 우리의 제안 방법인 CHAIN-OF-TABLE이 다양한 LLM 옵션에 일반화될 수 있음을 입증
- Chain-of-Thought 개념을 표 설정으로 확장하여 입력 표를 변환하여 중간 결과를 저장
이 다단계 표 추론 접근법은 표의 진화를 통해 더 정확한 표 이해 - 표 기반 사실 확인 및 질문 응답에 대한 광범위한 실험을 통해 CHAIN-OF-TABLE이 WikiTQ, TabFact 및 FeTaQA 데이터셋에서 SOTA 달성

이 그림은 (a) 일반 추론, (b) 프로그램 지원 추론, 그리고 (c) 제안된 CHAIN-OF-TABLE을 비교
a) 일반 추론
- 입력 프롬프트
- 원본 표:
Rank | Cyclist1 | Alejandro (ESP)2 | Davide (ITA)3 | Paolo (ITA)4 | Haimar (ESP)
- 원본 표:
- 질문: "Which country had the most cyclists finish within the top 3?"
- LLM 출력: "There are 2 cyclists from Spain. They are Alejandro and Haimar. The answer is Spain."
- 문제점: 일반 추론의 여러 단계는 복잡한 표를 해결하지 못합니다. 질문은 상위 3명의 사이클리스트에 대해 묻지만 Haimar는 상위 3명에 속하지 않음
(b) 프로그램 지원 추론
- SQL 쿼리:
SELECT Country FROM table WHERE Rank<=3 GROUP BY Country ORDER BY COUNT(*) DESC LIMIT 1
- 문제점: 생성된 프로그램(SQL 쿼리)은 복잡한 표를 해결하지 못합니다. "Country"가 "Name"과 동일한 셀에 있으므로 SQL은 쿼리를 실행할 수 없음
(c) CHAIN-OF-TABLE (제안된 방법)
단계 1: 표, 질문, 연산 이력을 기반으로 다음 연산을 샘플링
단계 2: 샘플링된 연산에 대한 인수를 생성
단계 3: 표를 변환하여 표 기반 추론 과정을 저장
세부 과정:
- 입력 프롬프트 (다음 반복):
[Intermediate Table] Rank | Cyclist | Country1 | Alej. | ESP[Operation History] [f_add_col][Question] Which country ... in the top 3?
연산 역사:
- Iter 1: f_add_col(Country)
- Iter 2: f_select_row(1,2,3)
- Iter 3: f_group_by(Country)
- Iter 4: f_sort_by(Count)
최종 쿼리 프롬프트:
[Q] Which country had the most cyclists finish within the top 3?결과:
Country | CountITA | 2ESP | 1최종 답변: "Italy"
요약
- 일반 추론: 여러 추론 단계가 복잡한 표를 해결하지 못함.
- 프로그램 지원 추론: 생성된 프로그램이 표의 이름과 국적을 정확하게 파싱하지 못함.
- CHAIN-OF-TABLE: 복잡한 표를 문제에 맞게 변환하는 연산 체인을 반복적으로 샘플링하여 LLM이 올바른 답변을 도출할 수 있도록 함.
BERT에서 제안된 성공적인 마스크 언어 모델링(MLM)을 따르는 TaPas는 사전 훈련 중에 모델이 표의 특정 셀을 재구성하도록 요청
Pasta와 TUTA는 표의 전체 열이나 세그먼트를 마스킹할 것을 제안
TAPEX는 대규모 합성 SQL 데이터셋으로 인코더-디코더 모델을 사전 훈련해 SQL 실행기로 작동하여 표 구조를 더 잘 이해할 수 있게 함
표 이해를 위한 언어 모델 프롬프트 LLM은 In-context learning을 통해 몇 가지 샘플로부터 학습할 수 있음
이 전략은 모델에 추가 지침을 제공하여 다운스트림 작업을 더 잘 해결할 수 있도록 널리 사용
Chain-of-Thought는 끝에서 끝으로 답변을 생성하는 대신 답변하기 전에 추론 단계를 생성할 것을 제안
CoT를 따르는 Least-to-Most와 DecomP는 질문을 추론 체인의 하위 문제로 나누어 제안
추론 중 후속 단계는 이전 단계를 인식
이러한 반복 체인과 작업 분해는 하위 문제를 해결하여 얻은 중간 결과를 활용하여 복잡한 문제에서 결과를 더욱 향상
Jin & Lu(2023)는 입력과 출력이 텍스트 형식인 작업에 주로 초점을 맞춘 표 채우기 절차를 통해 CoT를 향상
그러나 CoT를 따르는 작업들은 표 데이터를 위해 특별히 설계된 것은 아님
이러한 일반적인 추론 방법을 사용하는 대형 언어 모델은 괜찮은 결과를 얻을 수 있지만, 이러한 방법과 표 시나리오에 특화된 방법 간에는 여전히 차이가 있음
CHAIN-OF-TABLE을 제안하여 중간 사고의 대리자로 표 작업에서 중간 표를 직접 통합하여 이 격차를 해결
표 이해 시나리오에서는 Text-to-SQL with LLMs 아이디어의 직접적인 응용
프로그램의 한계를 더 넓히기 위해 Binder는 SQL 또는 파이썬 프로그램을 생성하고 프로그램 내에서 LLM을 API로 호출하여 기능을 확장
LEVER는 또한 생성된 프로그램을 실행 결과로 검증하는 추가 단계를 통해 프로그램을 사용하여 표 기반 작업을 해결할 것을 제안
그러나 이러한 프로그램 지원 방법의 보조 프로그램은 복잡한 표가 포함된 어려운 사례를 해결하는 데 여전히 부족
이러한 제한 사항은 단일 패스 생성 프로세스의 제약에서 주로 발생하며, LLM이 특정 질문에 따라 표를 수정할 수 없기 때문에 정적 표에서 추론을 수행해야 함
Chain-of-Table 방법은 주어진 질문에 맞게 표를 변환하는 다단계 추론 프레임워크
Dater는 표 기반 작업을 해결하면서 표 컨텍스트를 수정하는 유일한 모델
그러나 Dater의 표 분해는 표 데이터를 LLM이 추론 수행하기에 너무 클 수 있다는 아이디어에 의해 동기가 부여
따라서 표 분해는 LLM 지원 데이터 전처리에 더 가깝고, 열과 행 선택에만 제한된 표 작업을 사용하며 모든 표와 질문에 고정되어 있어 추론 체인의 일부와는 다름
대조적으로, CHAIN-OF-TABLE은 더 큰 범위의 일반 표 작업을 일반화하고 입력에 기반하여 적응적으로 추론 체인을 동적으로 생성하여 LLM의 계획 능력을 활용
CHAIN - OF -TABLE REASONING
표 추론에서 각 항목은 삼중항 (T, Q, A)으로 나타낼 수 있음
여기서 T는 표를, Q는 표와 관련된 질문이나 진술을, A는 예상 답변
특히, 표 질문 응답(task)에서는 Q와 A가 자연어 형식의 질문과 예상 답변을 의미하며, 표 기반 사실 검증(task)에서는 Q가 표 내용에 대한 진술이고 A는 진술의 정확성을 나타내는 Boolean 값 {True, False}
목표는 주어진 질문 Q와 표 T에 대해 답변 A를 예측하는 것
일반적인 추론에 사용된 패러다임 내에서 표 기반 추론을 용이하게 하기 위해 모든 데이터 값을 포함한 표를 텍스트 형식으로 변환
표 형식 인코딩 비교
이전 연구들 및 기준 방법론과 일치하여 CHAIN-OF-TABLE에서 PIPE 인코딩을 채택
제안된 표 형식의 CoT의 성능 향상을 다양한 표 형식 선택의 영향으로부터 분리
다양한 인코딩 방법이 표 이해 성능에 미치는 영향을 더 깊이 이해하기 위해, 우리는 추가적인 실험을 수행
이 실험에서는 HTML, TSV, 및 Markdown과 같은 3가지 추가 표 표현을 사용
PaLM 2를 사용한 WikiTQ에서의 종단간 QA를 실행 예로 사용
이러한 결과들은 다양한 표 형식 인코딩 방법들이 다른 결과를 초래
특히, 연구에서 채택된 PIPE 형식이 테스트된 네 가지 인코딩 방법 중 가장 높은 성능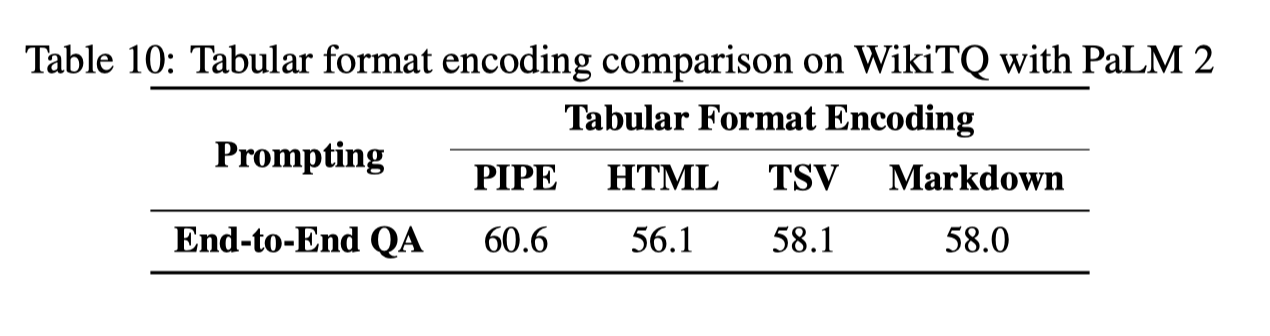
Format에 따른 성능 CHAIN-OF-TABLE 내 프롬프트
E.1 DynamicPlan
여기서 T는 최신 중간 테이블이고 Q는 해당 질문
chain은 테이블에 수행된 연산 목록
DynamicPlan을 통해, LLM은 현재 샘플에 대한 나머지 연산 체인을 생성(그림 6(c) 참조).
생성된 연산을 f_{i+1}(\text{args}_{i+1}) → ... → [E]로 표기합니다. 여기서 f i는 입력된 개방형 연산 체인의 마지막 연산입니다. 전체 체인이 생성되었음에도 불구하고, 우리는 첫 번째 생성된 연산, f i+1만을 고려하고 나머지 생성물을 포함한 인수 및 남은 연산은 무시합니다. f i+1은 이전 연산에서의 최신 중간 테이블을 기반으로 생성되며, 이후 연산의 생성은 가장 최신의 중간 테이블을 기반으로 하지 않으므로 생성된 내용에 오류가 있을 수 있습니다. 따라서, 우리는 생성된 체인 중 f i+1이 가장 신뢰할 수 있는 생성물이라고 믿습니다. 자세한 프롬프트는 그림 9를 참조하세요.
E.2 GenerateArgs
GenerateArgs(T, Q, f)에서 사용된 데모 예시와 프롬프트를 그림 7에서 설명합니다. 여기서 T는 최신 중간 테이블이고 Q는 해당 질문입니다; f는 선택된 테이블 연산입니다. 각 연산에 대한 자세한 프롬프트와 생성된 인수를 추출하기 위한 정규 표현식은 다음과 같습니다.
f_add_column: 그림 10 참조.f_select_row: 그림 12 참조.f_select_column: 그림 11 참조.f_group_by: 그림 13 참조.f_sort_by: 그림 14 참조.
E.3 Query
Query(T, Q)에서 사용된 프롬프트를 그림 8에서 설명합니다. 여기서 T는 CHAIN-OF-TABLE에서 결과로 나온 테이블이고 Q는 질문입니다. 보다 자세한 프롬프트는 그림 15를 참조하세요.3.1 OVERVIEW
CHAIN-OF-TABLE은 LLM이 주어진 질문 Q에 따라 표 T에 대한 연산 체인을 동적으로 계획할 수 있게 함
원자적 도구 기반 연산을 사용하여 표 체인을 구성.
연산에는 열 추가, 행 또는 열 선택, 그룹화 및 정렬이 포함되며, 이는 SQL 및 데이터프레임 개발에서 일반적으로 사용
Dater는 표와 질문을 분해하기 위한 전용이지만 고정된 절차를 사용했으며, 이는 새로운 연산과의 호환성을 제한
또한, Binder는 새로운 연산과 잠재적으로 호환될 수 있지만 SQL 또는 파이썬과 같은 코드 인터프리터와 함께 작동하는 연산에만 제한
대조적으로, Chain-of-Table 프레임워크는 확장 가능하며 맥락 학습(in-context learning) 기능을 활용하여 다양한 도구에서 효과적인 연산을 샘플링하고 실행할 수 있음
알고리즘 1에 설명된 대로, 각 반복에서 우리는 LLM이 주어진 질문 Q, 최신 표 상태 T, 연산 체인 chain을 사용하여 미리 정의된 연산 중 하나인 f를 샘플링하도록 프롬프트(4번째 줄).
그런 다음, LLM에게 f에 필요한 인수 args를 생성하도록 요청하고(5번째 줄), 이를 실행하여 표 T를 변환(6번째 줄).
연산 체인 chain에서 표에 수행된 연산 f를 추적(7번째 줄). 프로세스는 종료 태그 [E]가 생성되면 종료(8번째 줄).
마지막으로, 최신 표를 LLM에 입력하여 답변을 예측(9번째 줄).
이 일련의 연산은 LLM이 입력 표를 이해하고 최종 답변을 더 잘 생성할 수 있도록 하는 추론 단계를 제공합니다.

알고리즘 1: CHAIN-OF-TABLE 프롬프트
이 알고리즘은 주어진 표 질문 쌍 (T, Q)에 대해 예측된 답변 Â를 생성하는 과정을 설명합니다.
- 함수 정의: Function Chain-of-Table (T, Q)는 표와 질문을 입력으로 받습니다.
- 연산 체인 초기화:
- chain을 초기화하여 시작 태그 [B]와 인수가 필요 없는 ϕ로 구성된 리스트로 만듭니다.
- 반복 구조 (repeat): 4. 다음 연산 생성:
- DynamicPlan(T, Q, chain)을 사용하여 표, 질문, 현재 연산 체인을 기반으로 다음 연산 f를 생성합니다.
- 인수 생성:
- GenerateArgs(T, Q, f)를 사용하여 다음 연산 f에 필요한 인수 args를 생성합니다.
- 표 변환:
- f(T, args)를 실행하여 표 T를 업데이트합니다.
- 연산 기록:
- 연산 f와 인수 args를 연산 체인 chain에 추가합니다.
- 종료 조건:
- 종료 태그 [E]가 생성될 때까지 반복합니다.
- 최종 쿼리:
- 최종 표와 질문을 사용하여 LLM에 쿼리하여 최종 답변 Â를 얻습니다.
- 반환:
- 예측된 답변 Â를 반환합니다.
요약
이 알고리즘은 주어진 표와 질문에 대해 반복적으로 연산을 수행하고 중간 결과를 기반으로 다음 연산을 계획하여 최종적으로 질문에 대한 답변을 생성합니다. 연산 체인을 유지 관리하면서 각 단계에서 표를 동적으로 업데이트하고, 최종적으로 업데이트된 표를 사용하여 LLM에서 답변을 예측합니다.
3.2 DYNAMIC PLANNING
CHAIN-OF-TABLE은 맥락 학습을 통해 LLM이 다음 연산을 동적으로 계획하도록 합니다. 그림 2(a)에 표시된 대로, DynamicPlan에는 세 가지 구성 요소가 포함됩니다: 최신 중간 표 T(그림 2(a)(i)), 이전 연산 체인의 역사 chain(그림 2(a)(ii)), 및 질문 Q(그림 2(a)(iii)). 우리는 LLM이 (T, chain, Q)를 기반으로 연산 풀에서 다음 연산 f를 선택하도록 안내합니다. 그런 다음, LLM은 다음 연산을 동적으로 계획하고 단계별로 표 기반 추론 체인을 구축할 수 있습니다. 자세한 프롬프트는 부록 E.1을 참조하십시오.
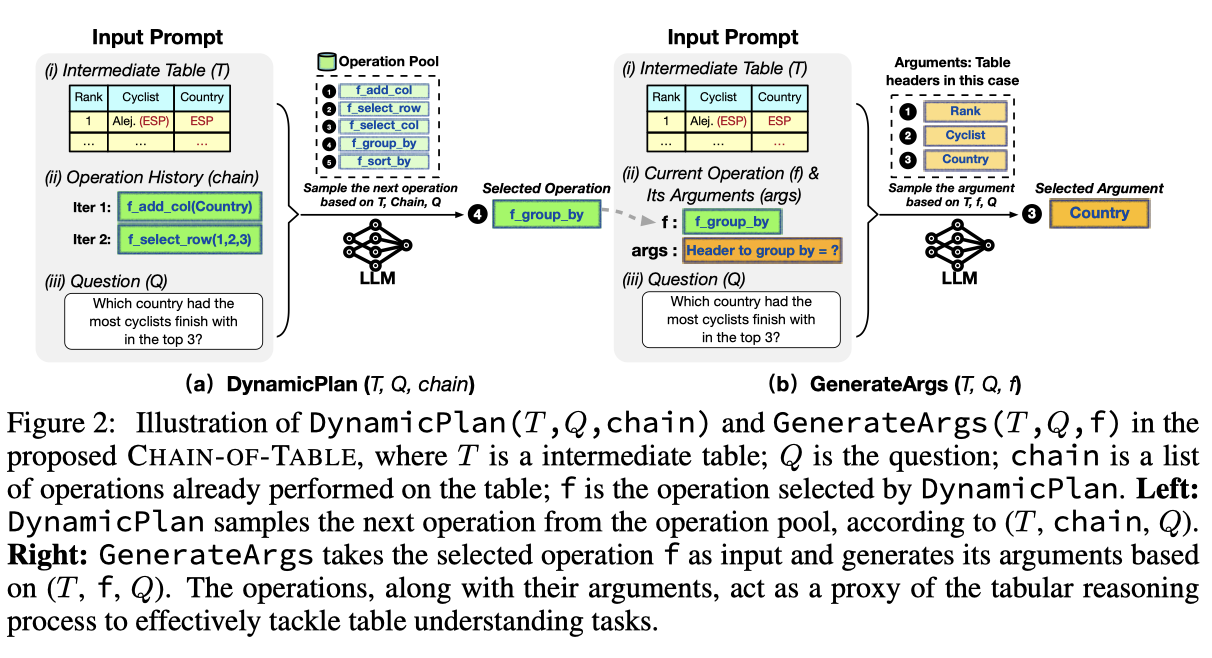
그림 2: DynamicPlan(T, Q, chain) 및 GenerateArgs(T, Q, f) 설명
이 그림은 제안된 CHAIN-OF-TABLE에서 DynamicPlan(T, Q, chain)과 GenerateArgs(T, Q, f)의 과정을 설명합니다. 여기서 T는 중간 표, Q는 질문, chain은 표에 대해 이미 수행된 연산 목록, f는 DynamicPlan에서 선택된 연산입니다.
(a) DynamicPlan(T, Q, chain)
- 입력 프롬프트:
- (i) 중간 표 (T):
순위 | 사이클리스트 | 국가1 | Alej. (ESP) | ESP ...
- (ii) 연산 이력 (chain):
- 반복 1: f_add_col(Country)
- 반복 2: f_select_row(1, 2, 3)
- (iii) 질문 (Q): "상위 3위 내에 들어간 사이클리스트가 가장 많은 국가는 어디인가요?"
- (i) 중간 표 (T):
- 과정:
- 연산 풀에서 다음 연산을 샘플링합니다 (f_add_col, f_select_row, f_select_col, f_group_by, f_sort_by).
- LLM을 사용하여 표, 체인, 질문을 기반으로 다음 연산을 선택합니다.
- 선택된 연산은 f_group_by입니다.
(b) GenerateArgs(T, Q, f)
- 입력 프롬프트:
- (i) 중간 표 (T):
순위 | 사이클리스트 | 국가1 |. Alej. (ESP) | ESP ...
- (ii) 현재 연산 (f) 및 해당 인수 (args):
- 연산: f_group_by
- 인수: "그룹화할 헤더는 무엇인가요?"
- (iii) 질문 (Q): "상위 3위 내에 들어간 사이클리스트가 가장 많은 국가는 어디인가요?"
- (i) 중간 표 (T):
- 과정:
- LLM을 사용하여 현재 표, 연산, 질문을 기반으로 인수를 샘플링합니다.
- 이 경우, 샘플링된 인수는 "Country"입니다.
요약
- **DynamicPlan(T, Q, chain)**은 현재 중간 표, 연산 이력, 질문을 기반으로 연산 풀에서 다음 연산을 샘플링하고 선택합니다.
- **GenerateArgs(T, Q, f)**는 선택된 연산과 질문을 기반으로 해당 연산의 인수를 생성합니다.
- 이러한 연산과 인수는 표 기반 추론 과정을 효과적으로 처리하는 데 중요한 역할을 합니다.
3.3 ARGUMENT GENERATION
다음 단계인 GenerateArgs는 DynamicPlan에 의해 샘플링된 선택된 표 연산 f에 대한 인수를 생성하는 것입니다. GenerateArgs는 세 가지 주요 구성 요소로 구성됩니다: 최신 중간 표 T(그림 2(b)(i)), 선택된 연산 f 및 해당 인수 args(그림 2(b)(ii)), 및 질문 Q(그림 2(b)(iii)). 우리는 다양한 연산에 필요한 인수 수를 고려하기 위해 간단한 정규 표현식을 사용합니다(자세한 내용은 부록 E.2 참조). 마지막으로, 프로그래밍 언어를 적용하여 연산을 실행하고 해당 중간 표를 생성합니다.
3.4 FINAL QUERY
우리는 동적 계획(섹션 3.2)과 인수 생성(섹션 3.3)을 통해 표를 변환합니다. 이 과정에서, 우리는 표 기반 추론 단계를 대리하는 일련의 연산을 생성합니다. 이러한 연산은 각 단계를 저장하고 LLM에 결과를 제시하는 중간 표를 생성합니다. 결과적으로, 이 연산 체인에서 생성된 출력 표는 표 기반 추론의 중간 단계를 포괄적으로 포함합니다. 그런 다음, 이 출력 표와 질문을 LLM에 입력하여 최종 답변을 제공합니다. 이는 알고리즘 1의 9번째 줄에 설명된 대로입니다.
CHAIN-OF-TABLE 평가
우리는 제안된 CHAIN-OF-TABLE을 세 가지 공개된 표 이해 벤치마크에서 평가했습니다: WikiTQ (Pasupat & Liang, 2015), FeTaQA (Nan et al., 2022), 그리고 TabFact (Chen et al., 2019). WikiTQ와 FeTaQA는 표 기반 질문 응답에 초점을 맞춘 데이터셋으로, 질문에 답하기 위해 제공된 표를 복잡하게 추론해야 합니다. WikiTQ는 일반적으로 짧은 텍스트 답변을 요구하는 반면, FeTaQA는 더 긴 자유 형식의 답변을 요구합니다. 반면 TabFact는 표 기반 이진 사실 검증 벤치마크로, 표를 기반으로 주어진 진술의 진실성을 확인하는 작업입니다. WikiTQ 평가에서는 공식 표기 정확도를 사용하고, TabFact에서는 이진 분류 정확도를 사용합니다. FeTaQA는 더 긴 목표 텍스트와 예측을 비교하는 특성상 BLEU (Papineni et al., 2002), ROUGE-1, ROUGE-2, ROUGE-L (Lin, 2004)를 평가 지표로 사용합니다. 실험에서는 PaLM 2-S, GPT 3.5 (turbo-16k-0613), 그리고 LLaMA 2 (Llama-2-17B-chat)를 백본 LLM으로 사용했습니다. 맥락 학습을 수행하기 위해 프롬프트에 훈련 세트의 몇 가지 샘플을 포함시켰습니다. 이러한 프롬프트 예시는 부록 E에서 확인할 수 있습니다. LLM 추론 매개변수와 사용된 데모 샘플 수에 대한 자세한 내용은 부록 C에 제공됩니다.

4.1 BASELINES
기준선 방법은 두 그룹으로 분류됩니다: (a) 일반 추론, 여기에는 End-to-End QA, Few-Shot QA, Chain-of-Thought (Wei et al., 2022)가 포함됩니다; (b) 프로그램 지원 추론, 여기에는 Text-to-SQL (Rajkumar et al., 2022), Binder (Cheng et al., 2022), Dater (Ye et al., 2023)가 포함됩니다. 이러한 기준선 방법에 대한 자세한 설명은 아래에 제공됩니다.
- 일반 추론: End-to-End QA는 표와 질문이 입력 프롬프트로 제공될 때 LLM이 직접 답변을 생성하도록 안내합니다. Few-Shot QA는 비슷하게 작동하지만, 프롬프트에 (표, 질문, 답변) 삼중항의 몇 가지 예를 포함시킵니다. 이러한 예는 훈련 세트에서 선택되며, 모델은 또한 답변을 직접 출력합니다. Chain-of-Thought (Wei et al., 2022)는 질문을 전달하기 전에 LLM이 추론 과정을 텍스트 형식으로 명확히 하도록 프롬프트합니다. 기준선의 프롬프트는 부록 F에서 확인할 수 있습니다.
- 프로그램 지원 추론: Text-to-SQL (Rajkumar et al., 2022)은 LLM이 질문에 답하기 위해 SQL 쿼리를 생성하도록 안내하는 맥락 학습 샘플을 활용합니다. 이 접근법은 Chen et al. (2022)와 Gao et al. (2023)이 소개한 개념을 따릅니다. Binder (Cheng et al., 2022)는 SQL이나 Python과 같은 프로그래밍 언어와 언어 모델 API를 통합합니다. 이 통합은 LLM이 주어진 표와 질문에 대해 표 추론 작업을 수행하는 실행 가능한 프로그램을 생성하도록 프롬프트합니다. Dater (Ye et al., 2023)는 표 컨텍스트와 질문을 효율적으로 분해하기 위해 몇 가지 샘플을 사용하여 하위 표와 하위 질문으로 분해된 끝에서 끝 표 추론을 향상시킵니다.
4.2 RESULTS
우리는 세 가지 데이터셋(WikiTQ, TabFact, FeTaQA)에서 일반 추론 방법과 프로그램 지원 추론 방법을 CHAIN-OF-TABLE과 비교했습니다. WikiTQ와 TabFact의 결과는 표 1에 제시되어 있습니다. FeTaQA에 대한 추가 결과는 부록 B에서 확인할 수 있습니다. 우리는 이전 작업을 따르고 공식 평가 파이프라인을 사용하여 성능을 보고합니다.
표 1은 CHAIN-OF-TABLE이 TabFact와 WikiTQ에서 모든 일반 추론 방법과 프로그램 지원 추론 방법을 크게 능가한다는 것을 보여줍니다. 이는 CHAIN-OF-TABLE의 동적으로 샘플링된 연산과 정보가 풍부한 중간 표에 기인합니다. CHAIN-OF-TABLE은 표 추론 단계를 대리하는 연산을 반복적으로 생성하며, 이러한 연산은 LLM에 중요한 중간 사고를 전달하는 맞춤형 중간 표를 생성하고 제시합니다. CHAIN-OF-TABLE의 지원으로 LLM은 신뢰할 수 있는 올바른 답변에 도달할 수 있습니다.
결과에서, 일반 Chain-of-Thought를 PaLM 2를 사용한 End-to-End QA에 도입했을 때, 표 구조의 복잡성으로 인해 WikiTQ에서 성능이 감소하는 것을 관찰했습니다. 반면, 제안된 CHAIN-OF-TABLE은 PaLM 2로 TabFact에서 8.69%, WikiTQ에서 6.72%의 End-to-End QA 성능을 지속적으로 향상시켰습니다.
또한, 제안된 CHAIN-OF-TABLE은 실험된 모든 백본 모델에서 효과적이며, 다른 경쟁 방법(Binder 등)은 더 큰 LLM에서 더 잘 작동하지만, 작은 LLaMA 2 (Llama-2-17B-chat)에서는 성능이 감소했습니다. 우리는 Binder의 단일 패스 생성 프로세스가 이러한 성능 저하의 원인이라고 봅니다. Binder는 프레임워크 내에서 API 호출을 통합하지만, 변환된 표를 수정하고 관찰할 수 있는 기능이 부족하여 정적 표에서만 표 추론을 수행할 수 있습니다. 결과적으로, 복잡한 사례를 해결하는 것이 어려워집니다.

4.3 PERFORMANCE ANALYSIS UNDER DIFFERENT OPERATION CHAIN LENGTHS
CHAIN-OF-TABLE에서 각 연산의 선택은 질문과 해당 표의 난이도와 복잡성에 따라 동적으로 결정됩니다. 따라서 우리는 연산 길이에 따른 성능을 자세히 연구했습니다. 테스트 샘플을 연산 체인 길이에 따라 분류하여 각 연산 체인 길이에서 CHAIN-OF-TABLE을 Chain-of-Thought 및 Dater와 비교했습니다. PaLM 2를 사용한 WikiTQ 결과를 예로 들어, 모든 방법의 정확도를 막대 그래프로 나타냈습니다. CHAIN-OF-TABLE이 모든 연산 체인 길이에서 기준선 방법보다 일관되게 뛰어나다는 것을 강조했습니다. 특히 Chain-of-Thought와 비교하여 최대 11.6%, Dater와 비교하여 최대 7.9% 더 높은 정확도를 보였습니다.
일반적으로, 표 추론 체인에서 요구되는 표 연산 수가 증가함에 따라 질문과 표의 난이도와 복잡성이 증가하여 이러한 방법의 성능이 감소합니다. 그럼에도 불구하고, 제안된 CHAIN-OF-TABLE은 다른 기준선 방법과 비교하여 성능이 크게 감소하지 않았습니다. 예를 들어, 연산 수가 4에서 5로 증가할 때 CHAIN-OF-TABLE의 성능은 최소한으로 감소했습니다.

4.4 PERFORMANCE ANALYSIS UNDER DIFFERENT TABLE SIZES
대형 표는 LLM이 긴 입력 프롬프트의 컨텍스트를 해석하고 통합하는 데 어려움을 겪기 때문에 큰 도전 과제를 제시합니다. 다양한 크기의 표에서 성능을 평가하기 위해 WikiTQ의 입력 표를 토큰 수에 따라 세 그룹으로 분류했습니다: 소형(<2000 토큰), 중형(2000-4000 토큰), 대형(>4000 토큰). 그런 다음 CHAIN-OF-TABLE을 Dater (Ye et al., 2023) 및 Binder (Cheng et al., 2022)와 비교했습니다. 예상대로 입력 표가 커질수록 성능이 감소하지만, 제안된 CHAIN-OF-TABLE의 성능은 우아하게 감소하며, 대형 표를 처리할 때 두 번째로 좋은 경쟁 방법보다 10% 이상 향상된 성능을 보였습니다. 이는 긴 표 입력을 처리하는 데 있어 추론 체인의 효능을 보여줍니다.
4.5 EFFICIENCY ANALYSIS OF CHAIN - OF -TABLE
우리는 생성된 샘플 수를 평가하여 CHAIN-OF-TABLE의 효율성을 분석했습니다. 가장 최신의 경쟁 기준선 방법인 Binder(Cheng et al., 2022)와 Dater(Ye et al., 2023)와 비교했습니다. WikiTQ에서의 분석 결과는 표 4에 제시되어 있습니다. Binder는 일관된 결과를 위해 50개의 샘플이 필요한 Neural-SQL 쿼리를 생성합니다. Dater는 표를 분해하고 질문에 대한 클로즈 쿼리를 생성하는 등 여러 정교하지만 고정된 단계를 포함합니다. 각 단계에서 Dater는 LLM 출력의 정확성을 향상시키기 위해 자기 일관성을 사용하여 많은 수의 샘플이 필요합니다. 이러한 프레임워크에 대한 자세한 설명은 Ye et al. (2023) 및 Cheng et al. (2022)의 논문을 참조하십시오.
이전 방법과 달리, 제안된 CHAIN-OF-TABLE은 성능 향상을 위해 자기 일관성 샘플링에 의존하지 않고 탐욕적인 검색 전략을 사용하여 표 추론 과정을 수행합니다. 이 접근법은 CHAIN-OF-TABLE이 반복적 추론 과정을 채택함에도 불구하고 쿼리 수를 줄이는 결과를 가져옵니다. 구체적으로, CHAIN-OF-TABLE이 필요한 쿼리 수는 가장 최근 기준선 방법 중 가장 낮으며, Binder보다 50%, Dater보다 75% 적습니다. 우리는 이 방법의 쿼리 효율성을 동적 연산 실행을 통해 설명할 수 있습니다. 모델은 최종 출력에 더 빠르고 신뢰할 수 있게 도달하는 효과적인 추론 과정을 찾을 수 있습니다.

4.6 사례 연구
그림 4에서는 CHAIN-OF-TABLE의 표 추론 과정을 설명합니다. 이 질문은 복잡한 표를 기반으로 하며, 1) 관련 열을 식별하고, 2) 집계를 수행하고, 3) 집계된 중간 정보를 재정렬해야 하는 여러 추론 단계를 필요로 합니다. 제안된 CHAIN-OF-TABLE은 연산 체인을 동적으로 계획하고 변환된 표에 중간 결과를 정확히 저장하는 과정을 포함합니다. 이러한 중간 표는 LLM이 올바른 답변에 더 신뢰할 수 있게 도달할 수 있도록 안내하는 표 기반 사고 과정으로 작용합니다.
'논문' 카테고리의 다른 글
- 문제 상황: