-
8. MULTI-TASK INFERENCE:Can Large Language Models Follow Multiple Instructions at Once?논문 2024. 3. 26. 18:47
프로젝트를 같이 하면서 기여를 많이 하지 못했지만 참여한 첫 논문?
MULTI-TASK INFERENCE: Can Large Language Models Follow Multiple Instructions at Once?에 대해서 정리를 해보려고 한다. 사실 내일 스터디 발표가 있어 겸사겸사의 느낌이다.
대규모 언어 모델(Large Language Models, LLMs)이 통상적으로 한 번의 추론 호출에 단일 지시사항을 따르도록 요청받는 상황에서, LLMs가 여러 지시사항을 동시에 처리할 수 있는 능력을 분석합니다. 이를 위해, 다중 작업 추론(MULTI-TASK INFERENCE) 능력을 평가하기 위한 종합적인 벤치마크인 MTI BENCH를 소개합니다. MTI BENCH는 25개 작업에서 총 5000개의 인스턴스를 포함하며, 각 작업은 2에서 3개의 하위 작업으로 구성됩니다.
이 논문은 다중 작업 추론이 전체 추론 시간을 평균적으로 1.46배 줄일 수 있음을 보여줍니다. 이는 여러 번의 추론 호출이 필요하지 않기 때문입니다. 또한, 예상과 달리 LLMs가 작업을 나눌 때 더 나은 성능을 보일 것이라는 기대와는 반대로, LLAMA-2-CHAT-70B와 GPT-4 같은 최신 LLMs가 MTI BENCH에서 다중 작업 추론을 사용할 때 단일 작업 추론보다 각각 최대 7.3% 및 12.4% 향상된 성능을 보였습니다.
LLM이 다양한 작업에서 인상적인 성능을 보여주었지만, 기존에는 주로 단일 지시사항을 따르는 상황에서의 성능이 연구되었습니다. 그러나 현실 세계의 문제 해결 과정은 종종 여러 하위 작업을 동시에 처리해야 하는 복잡성을 포함합니다. 이에 따라, LLMs가 복잡한 지시사항을 처리하는 능력, 즉 다중 하위 작업을 한 번의 추론 호출로 처리할 수 있는지 여부가 의문시됩니다. 현재까지의 평가 자원은 주로 단일 단계 지시사항을 따르는 LLMs의 능력을 측정하거나, 특정 도메인(예: 상식 추론, 산수)에서 다단계 지시사항을 처리하는 능력만을 진단합니다.
논문에서는 이러한 문제를 해결하기 위해, LLMs가 한 번의 추론 호출에서 복수의 지시사항을 처리할 수 있는지를 평가하는 다중 작업 추론(MULTI-TASK INFERENCE)의 능력을 분석합니다.
이를 위해 MTI BENCH라는 새로운 평가 벤치마크를 소개합니다. MTI BENCH는 25개의 작업으로 구성되며, 각 작업은 2~3개의 하위 작업으로 이루어져 있습니다. 연구에서는 MTI BENCH를 사용하여 단일 작업 추론(SINGLE-TASK INFERENCE)과 배치 처리(BATCH PROMPTING)를 비교함으로써, 다중 작업 추론이 신뢰할 수 있는 성능과 함께 추론 속도의 개선을 제공한다는 것을 보여줍니다.

2.1 Language Model Evaluation
언어 모델 평가에 대한 부분에서는 LLMs가 다양한 작업과 도메인에서 뛰어난 성능을 보여주고 있음에도 불구하고, 모델의 성능과 행동을 다각도에서 평가하는 것의 중요성을 강조합니다. 특히, 전통적인 평가 방식이 특정 도메인이나 작업에 초점을 맞춘 반면, 최근 연구들은 LLMs의 다양한 속성과 고급 능력을 전반적으로 평가하려는 시도가 이루어지고 있음을 지적합니다. 예를 들어, 사용자 상호작용에서의 도움성과 해로움을 평가하거나, 추론 작업에서의 사고 과정을 생성하는 능력, 이론적 사고의 존재 여부, 유해 콘텐츠 생성 회피 능력 등이 연구되고 있습니다.
2.2 Multiprocessing Capabilities of LLMs
다중 처리 능력에 관한 부분에서는 정보 처리의 동시성이 지능의 핵심 지표 중 하나임을 언급하며, LLMs의 이러한 능력을 평가하기 위한 연구들을 소개합니다. 특히, 여러 단계의 추론을 필요로 하는 HotpotQA, StrategyQA 같은 데이터셋이 이러한 능력을 테스트하는 데 사용되었지만, 이러한 연구들은 주로 내부 추론 과정의 정확성을 평가하고, 연속적이거나 동시적인 처리와 비교하는 데 초점을 맞추었습니다. 최근에는 배치 프롬프팅(Batch Prompting)과 같은 방법이 제안되어, LLMs가 동일한 작업의 여러 인스턴스를 동시에 처리할 수 있는지를 평가하고 있습니다. 그러나 이러한 방법은 여전히 동일한 작업 내의 인스턴스 처리에 한정되어 있어, 본 논문에서 소개하는 MTI BENCH와 같은, 서로 다른 작업들 사이의 상호작용을 평가하는 데는 제한적입니다.
이 두 주제를 통해 저자들은 LLMs의 평가 방법론과 이에 대한 연구 트렌드의 발전을 소개하며, 특히 LLMs의 다중 처리 능력에 대한 이해와 평가 방법론 개발의 필요성을 강조합니다. 이는 LLMs의 다양한 활용 가능성을 탐색하고, 보다 복잡한 인간과 유사한 정보 처리 능력을 갖춘 모델을 개발하는 데 기여할 수 있습니다.


논문에서 소개하는 "The MTI BENCH Dataset" 섹션은 MTI BENCH(Multi-Task Inference Benchmark)의 구성과 생성 과정에 대해 상세히 설명합니다. 이 벤치마크는 LLMs의 다중 작업 추론 능력을 평가하기 위해 개발되었으며, 다양한 NLP(Natural Language Processing) 작업을 포함하는 25개의 작업으로 구성되어 있습니다. 각 작업은 2에서 3개의 하위 작업으로 이루어져 있으며, 이들은 복수의 지시사항을 처리할 수 있는 모델의 능력을 평가하기 위해 설계되었습니다.
3.1 Task Formulation
MTI BENCH는 LLMs의 다중 작업 추론 능력을 평가하기 위한 포괄적인 벤치마크로, 총 25개의 작업이 각각 200개의 인스턴스를 포함하여 총 5000개의 인스턴스로 구성되어 있습니다. 이러한 작업들은 분류, 다중 선택 질문 응답(MCQA), 산수, 자연어 추론 등 28개의 NLP 작업 유형에서 선택되었습니다.
3.2 Dataset Construction
MTI BENCH 구성을 위해, Quoref, SNLI, MMLU, MATH 등과 같은 기존 NLP 벤치마크에서 다양한 작업을 선정했습니다. 선정된 작업은 높은 품질의 데이터셋에서 오는 것을 보장하기 위해 엄격한 품질 관리 과정을 거쳤으며, 더 복잡한 작업으로 통합될 수 있는 가능성이 있는 것들이었습니다. 연구진은 이러한 작업들을 결합하여 복합 작업을 만들었고, 나아가 그 중 일부는 불필요하거나 품질이 낮은 것으로 판단되어 제외되기도 했습니다.
3.3 Dataset Analysis
"3.3 Dataset Analysis" 부분에서는 MTI BENCH 데이터셋의 구성, 다양성, 그리고 품질을 분석하는 과정을 자세히 설명합니다. 이 분석은 데이터셋이 다중 작업 추론 능력 평가에 적합한지 확인하기 위한 중요한 단계입니다. 분석 과정은 주로 세 가지 주요 측면에 초점을 맞춥니다: 다양성(Diversity), 구성성(Compositionality), 그리고 품질(Quality).
다양성(Diversity)
다양성 분석에서는 MTI BENCH가 포함하는 NLP 작업의 유형 분포를 검토합니다. 특히, 각 하위 작업이 데이터셋 내에서 어떻게 분포하는지, 그리고 이러한 분포가 LLMs의 다양한 능력을 평가할 수 있도록 충분한 범위와 깊이를 제공하는지를 평가합니다. 데이터셋에는 분류, 문장 정렬, 답변 가능성 분류, 자연어 추론 등 다양한 유형의 작업이 포함되어 있으며, 이는 모델이 다양한 유형의 지시사항을 처리할 수 있는지 평가하는 데 도움이 됩니다.
구성성(Compositionality)
구성성 분석에서는 하위 작업들 간의 상호 의존성을 통계적으로 검증합니다. 이를 위해, GPT-3.5-TURBO 모델을 사용하여 MTI BENCH의 각 멀티-태스크 조합을 해결하고, 치퀘어(Chi-squared) 통계 검정을 적용하여 각 서브-태스크의 정확도 간의 의존성을 평가합니다. 특히, MULTI-STEP과 MULTI-PART 서브셋 간의 차이를 분석하여, 작업들이 의도된 대로 순차적 의존성 또는 독립성을 가지고 구성되었는지 확인합니다.
품질(Quality)
품질 검증 과정에서는 MTI BENCH의 인스턴스가 높은 품질 기준을 충족하는지 검토합니다. 이를 위해, 무작위로 선택된 인스턴스를 대상으로 한 양질의 검토가 이루어집니다. 두 명의 저자가 각 인스턴스에서 하위 작업 간의 유효한 의존성, 적절한 범주화, 그리고 일관성 있는 정답 처리 여부를 평가합니다. 이 과정은 데이터셋의 전반적인 품질을 높이고, 평가의 신뢰성을 보장하는 데 중요한 역할을 합니다.
이러한 분석을 통해, MTI BENCH가 다양한 하위 작업을 포함하고 있으며, 이 작업들 사이에 상호 의존성을 적절히 반영하고 있음을 확인할 수 있습니다. 또한, 철저한 품질 검증 과정을 거쳐, 데이터셋의 신뢰성과 유효성이 보장되었습니다.

"4 Experimental Setup" 섹션에서는 MTI BENCH를 사용하여 대규모 언어 모델(Large Language Models, LLMs)의 다중 작업 추론 능력을 평가하는 실험 설정에 대해 설명합니다. 이 섹션은 실험의 목적, 사용된 모델, 평가 방법론, 그리고 하드웨어 사양에 대한 상세 정보를 제공합니다.
실험 목적
실험의 주요 목적은 LLMs의 다중 작업 추론 능력을 평가하고, 이를 통해 모델의 성능과 추론 시간에 미치는 영향을 분석하는 것입니다. 이를 위해, SINGLE-TASK INFERENCE(단일 작업 추론), BATCH PROMPTING(배치 프롬프팅), 그리고 MULTI-TASK INFERENCE(다중 작업 추론)라는 세 가지 주요 추론 방법을 비교합니다.
사용된 모델
실험에는 여러 가지 LLMs가 사용되었습니다. 이들 모델에는 GPT-4, GPT-3.5, TULU(7b, 13b, 30b, 65b), VICUNA(7b, 13b), 그리고 LLAMA-2-CHAT(7b, 13b, 70b)가 포함됩니다. 이 모델들은 다양한 매개변수 크기를 가지며, 실험을 통해 이러한 다양한 크기의 모델들이 다중 작업 추론을 어떻게 처리하는지 평가됩니다.
평가 방법론
평가는 MTI BENCH의 25개 작업을 사용하여 수행됩니다. 각 작업은 여러 하위 작업으로 구성되어 있으며, 모델은 이러한 하위 작업을 동시에 또는 순차적으로 처리할 수 있는지를 평가받습니다. 평가는 각 추론 방법의 최종 정확도와 추론 시간을 기준으로 합니다. 특히, 정확도는 모델이 모든 하위 작업을 정확하게 완료한 경우에만 고려됩니다.
하드웨어 사양
실험에 사용된 하드웨어 사양도 중요한 요소입니다. TULU 모델의 경우, 다양한 GPU 설정이 사용되었습니다. 예를 들어, 7B와 13B 모델은 NVIDIA SXM4 GPU(80GB RAM) 하나를 사용했으며, 30B 모델은 같은 GPU 두 개를 사용했고, 65B 모델은 8개의 RTX A6000 GPU(각각 48GB RAM)를 사용했습니다. 이러한 하드웨어 구성은 모델의 추론 시간 평가에 영향을 미칠 수 있습니다.
이 섹션은 실험의 설계와 구성을 상세히 설명함으로써, LLMs의 다중 작업 추론 능력을 평가하는 과정에 대한 명확한 이해를 제공합니다. 실험 설정은 이후 섹션에서 제시되는 결과의 해석과 이해에 중요한 기반을 마련합니다.
"5 Experimental Results" 섹션에서는 MTI BENCH를 사용하여 대규모 언어 모델들의 다중 작업 추론 능력을 평가한 실험 결과에 대해 자세히 설명합니다. 이 섹션은 주요 결과, 추론 지연(latency) 분석, 그리고 자유 형식 생성(Free-Form Generation) 하위 집합에 대한 평가로 구성됩니다.
5.1 주요 결과
실험 결과는 SINGLE-TASK INFERENCE, BATCH PROMPTING, 그리고 MULTI-TASK INFERENCE의 세 가지 주요 추론 방법을 비교 분석합니다. 결과적으로, MULTI-TASK INFERENCE가 다른 방법들에 비해 일관되게 우수한 성능을 보여주었습니다. 특히, 상태 기반의 LLMs인 LLAMA-2-CHAT-70B와 GPT-4 모델은 MULTI-TASK INFERENCE를 사용했을 때 SINGLE-TASK INFERENCE 및 BATCH PROMPTING 대비 더 높은 성능 향상을 경험했습니다. 이는 모델의 규모가 클수록 다중 작업 추론의 이점이 더 크게 나타난다는 것을 시사합니다.
5.2 추론 지연(Inference Latency)
추론 지연 분석에서는 다양한 추론 방법이 모델의 처리 속도에 미치는 영향을 조사했습니다. MULTI-TASK INFERENCE는 SINGLE-TASK INFERENCE에 비해 평균적으로 1.46배 빠른 추론 속도를 보였습니다. 이는 다중 작업 추론이 단일 작업을 순차적으로 처리하는 것보다 더 효율적임을 보여줍니다. BATCH PROMPTING도 추론 속도를 개선시켰지만, MULTI-TASK INFERENCE가 성능과 속도 면에서 더 우수한 방법으로 평가되었습니다.
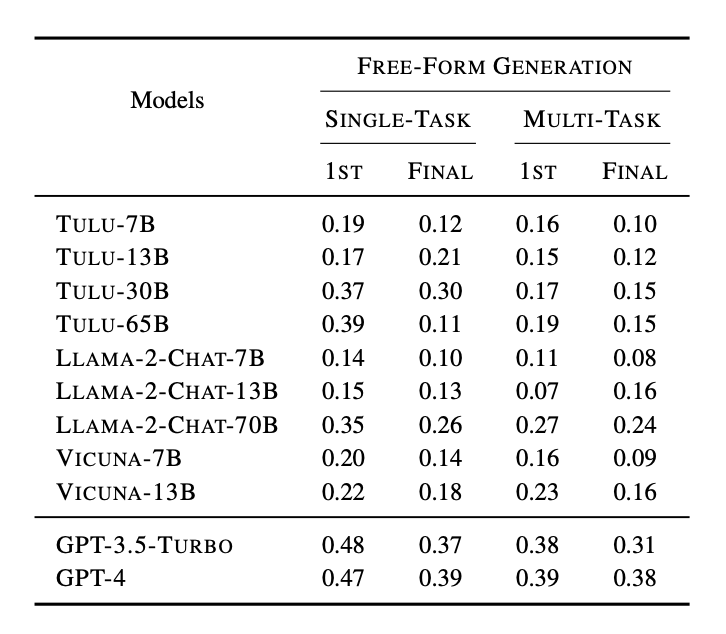
5.3 FREE-FORM GENERATION Subset
FREE-FORM GENERATION 하위 집합에 대한 평가는 다중 작업 추론의 효과를 자유 형식의 생성 작업에 적용하여 검토합니다. 이 하위 집합은 주로 번역과 요약 작업을 포함하며, 모델이 이러한 자유 형식의 작업에서 얼마나 잘 수행하는지를 평가합니다. 결과적으로, 작은 규모의 모델들은 SINGLE-TASK INFERENCE에서 더 좋은 성능을 보였으나, 모델의 규모가 클수록 MULTI-TASK INFERENCE와 SINGLE-TASK INFERENCE 사이의 성능 차이가 줄어들었습니다. GPT-4와 같은 큰 모델의 경우, 두 추론 방법 사이에 유의미한 성능 차이가 거의 관찰되지 않았습니다.
이 섹션에서 제시된 실험 결과는 LLMs의 다중 작업 추론 능력에 대한 깊은 통찰을 제공하며, 특히 모델의 규모가 큰 경우 다중 작업 추론이 성능과 효율성 면에서 유리함을 보여줍니다. 이러한 발견은 향후 LLMs의 개선과 응용에 중요한 영향을 미칠 수 있습니다

"6 Analysis of MULTI-TASK INFERENCE" 섹션에서는 MULTI-TASK INFERENCE가 대규모 언어 모델(Large Language Models, LLMs)의 성능에 긍정적인 영향을 미치는 이유와 방식을 분석합니다. 이 분석은 실험 결과에서 관찰된 패턴을 이해하고 설명하기 위한 목적으로, 두 가지 주요 부분으로 나뉩니다: 추가 입력 구성 요소에 대한 연구(ablation experiment)와 질적 분석(qualitative analysis).
6.1 Ablation Experiment
추가 입력 구성 요소에 대한 연구는 다중 작업 추론 시 제공되는 추가 정보가 모델의 성능에 어떤 영향을 미치는지를 탐구합니다. 특히, SINGLE-TASK INFERENCE 시 2번째 지시사항(2ND INSTRUCTION)과 2번째 컨텍스트(2ND CONTEXT)를 추가할 때 모델 성능에 미치는 영향을 분석합니다. 실험 결과, 다양한 모델과 데이터셋 서브셋에 대해, 2번째 지시사항 또는 2번째 컨텍스트를 추가함으로써 성능이 향상되었다는 것이 관찰되었습니다. 이는 추가적인 정보가 모델이 첫 번째 하위 작업을 해결하는 데 유용한 단서를 제공하며, 이로 인해 성능이 향상될 수 있음을 시사합니다.
6.2 Qualitative Analysis
질적 분석에서는 MULTI-TASK INFERENCE를 사용했을 때와 사용하지 않았을 때의 차이를 설명할 수 있는 특정 패턴을 식별합니다. GPT-4 모델을 사용한 분석에서, 다음과 같은 네 가지 주요 패턴이 관찰되었습니다:
- No Outputs: SINGLE-TASK INFERENCE에서는 아무런 출력도 제공하지 않는 경우가 있었으나, MULTI-TASK INFERENCE에서는 가능한 답변을 선택했습니다.
- Multiple Outputs: SINGLE-TASK INFERENCE에서 여러 답변을 제공하는 경우와 달리, MULTI-TASK INFERENCE는 가장 관련성 높은 답변 하나를 선택했습니다.
- Referencing: MULTI-TASK INFERENCE는 이후의 작업으로부터 정보를 참조하여 첫 번째 작업의 답변을 개선할 수 있었습니다.
- Planning: MULTI-TASK INFERENCE는 특정 작업을 해결하기 위한 계획을 수립하는 것처럼 보였습니다.
이러한 패턴은 MULTI-TASK INFERENCE가 모델에 추가적인 컨텍스트와 정보를 제공하며, 이것이 모델이 보다 효과적으로 문제를 해결하도록 돕는다는 것을 보여줍니다. 특히, 추가적인 지시사항과 컨텍스트는 모델이 문제에 접근하는 방식에 영향을 미치고, 이를 통해 모델이 더 정확한 답변을 생성할 수 있도록 합니다.
이 분석은 MULTI-TASK INFERENCE가 LLMs의 성능을 향상시킬 수 있는 중요한 메커니즘을 제공한다는 것을 보여줍니다. 이러한 이해는 향후 LLMs의 개선과 활용에 있어 중요한 기초 자료가 될 수 있습니다.
"7 Conclusion" 섹션에서는 논문 전체의 핵심 내용을 요약하고, 연구의 중요성과 그 결과를 정리합니다. 이 논문에서는 대규모 언어 모델(Large Language Models, LLMs)이 다중 작업 추론(MULTI-TASK INFERENCE)을 수행할 수 있는지, 그리고 이러한 능력이 모델의 성능과 추론 시간에 어떤 영향을 미치는지를 평가하기 위해 MTI BENCH라는 새로운 벤치마크를 소개합니다.
논문의 결론 부분에서는 다음과 같은 주요 포인트를 강조합니다:
- MTI BENCH 소개: 연구진은 LLMs의 다중 작업 추론 능력을 평가하기 위해 MTI BENCH라는 포괄적인 평가 도구를 개발했습니다. 이 벤치마크는 25개의 다양한 작업으로 구성되어 있으며, 각 작업은 여러 하위 작업으로 이루어져 있습니다. 이를 통해, LLMs가 복잡한 지시사항을 효과적으로 처리할 수 있는지를 평가할 수 있습니다.
- 다중 작업 추론의 효과: 실험 결과, 다중 작업 추론을 사용할 때, 특히 더 크고 발전된 모델에서 성능이 향상되었음을 보여줍니다. 이는 다중 작업 추론이 LLMs에게 제공하는 추가적인 컨텍스트와 정보가 모델의 추론 능력을 개선하는 데 도움이 될 수 있음을 시사합니다.
- 추론 시간의 개선: 다중 작업 추론은 추론 시간을 줄이는 데에도 효과적입니다. 연구 결과, 다중 작업 추론을 사용하면 단일 작업 추론에 비해 추론 시간을 평균적으로 1.46배 줄일 수 있었습니다. 이는 다중 작업 추론이 실제 애플리케이션에서 LLMs의 효율성을 높일 수 있는 방법을 제시한다는 것을 의미합니다.
논문은 또한 연구의 한계를 인정하며, 향후 연구에서 이를 해결하고 연구를 더 확장할 수 있는 방안을 제시합니다. 예를 들어, 다양한 언어와 문화적 배경에 대한 추가 연구, 다른 유형의 LLMs에 대한 평가, 더 복잡한 다중 작업 시나리오에 대한 연구 등이 포함됩니다.
결론적으로, 이 논문은 LLMs의 다중 작업 추론 능력을 체계적으로 평가하고 이해를 증진시키는 데 중요한 기여를 합니다. 이는 LLMs의 개선과 응용에 있어 중요한 단계를 마련하며, 향후 연구와 개발의 방향을 제시합니다.
"8 Limitations" 섹션에서는 연구의 한계점과 이러한 한계점이 미래 연구에 주는 시사점에 대해 설명합니다. 이 연구에서 개발된 MTI BENCH를 사용하여 대규모 언어 모델(Large Language Models, LLMs)의 다중 작업 추론 능력을 평가하는 과정에서 몇 가지 중요한 제한 사항이 확인되었습니다.
언어와 다양성의 제한
- 언어 범위: MTI BENCH는 주로 영어 데이터로 구성되어 있으며, FREE FORM GENERATION 하위 집합에는 프랑스어와 독일어가 포함되어 있지만, 이는 세계 수백 개 언어 중 소수에 불과합니다. 따라서 연구 결과의 언어적 범위와 다양성이 제한됩니다.
- 문화적 다양성: 데이터셋의 구성과 평가 사례들이 특정 문화적 배경에 기반하고 있을 가능성이 있으며, 이는 모델 평가의 일반화에 영향을 줄 수 있습니다.
데이터셋의 출처와 적용 범위
- 학술적 데이터셋: MTI BENCH의 소스 데이터셋은 주로 학술적인 벤치마크에서 가져온 것이며, 실제 사용자의 다양한 요구를 완벽히 반영하지 못할 수 있습니다.
- 평가 방법론의 한계: 자동 평가 방법이 모델 성능을 완전히 정확하게 반영하지 못할 수 있으며, 특히 자유 형식의 생성 작업에서 인간의 판단과 일치하지 않을 수 있습니다.
실험 설정과 모델 다양성
- 실험 설정의 제한: 모든 실험이 일관된 하이퍼파라미터 설정과 한정된 실험 환경 내에서 수행되었기 때문에, 다른 설정에서는 다른 결과가 나타날 수 있습니다.
- 모델 규모와 구조의 다양성: 실험에 포함된 LLMs의 규모와 구조가 다양하지만, 아직 평가되지 않은 다른 유형의 모델이나 구조가 있을 수 있습니다.
이러한 한계들에도 불구하고, 이 연구는 LLMs의 다중 작업 추론 능력을 체계적으로 평가하고 이해하는 데 중요한 기여를 합니다. 또한, 언어적 및 문화적 다양성, 평가 방법론, 실험 설정의 확장, 그리고 추가적인 모델 구조의 탐색 등 미래 연구의 방향을 제시합니다. 연구자들은 이 한계점들을 인정하고 미래의 연구에서 이를 해결하기 위한 방안을 모색할 것을 권장합니다.

'논문' 카테고리의 다른 글