-
7. Unsupervised Learning of Visual Features by Contrasting Cluster Assignments논문 2024. 3. 24. 13:40
대학원 고급기계학습 3주차 2번째 논문인 Unsupervised Learning of Visual Features by Contrasting Cluster Assignments, 즉SwAV에 대해서 정리를 하고자 한다.
수업의 2-3주차에는 주로 SSL에 대한 논문을 중심으로 공부를 하고 있다. 뭔가 정리가 되어가고 있는 느낌?
성능부터 우선 말하자면 내가 SSL의 SOTA이다!ㅋㅋ
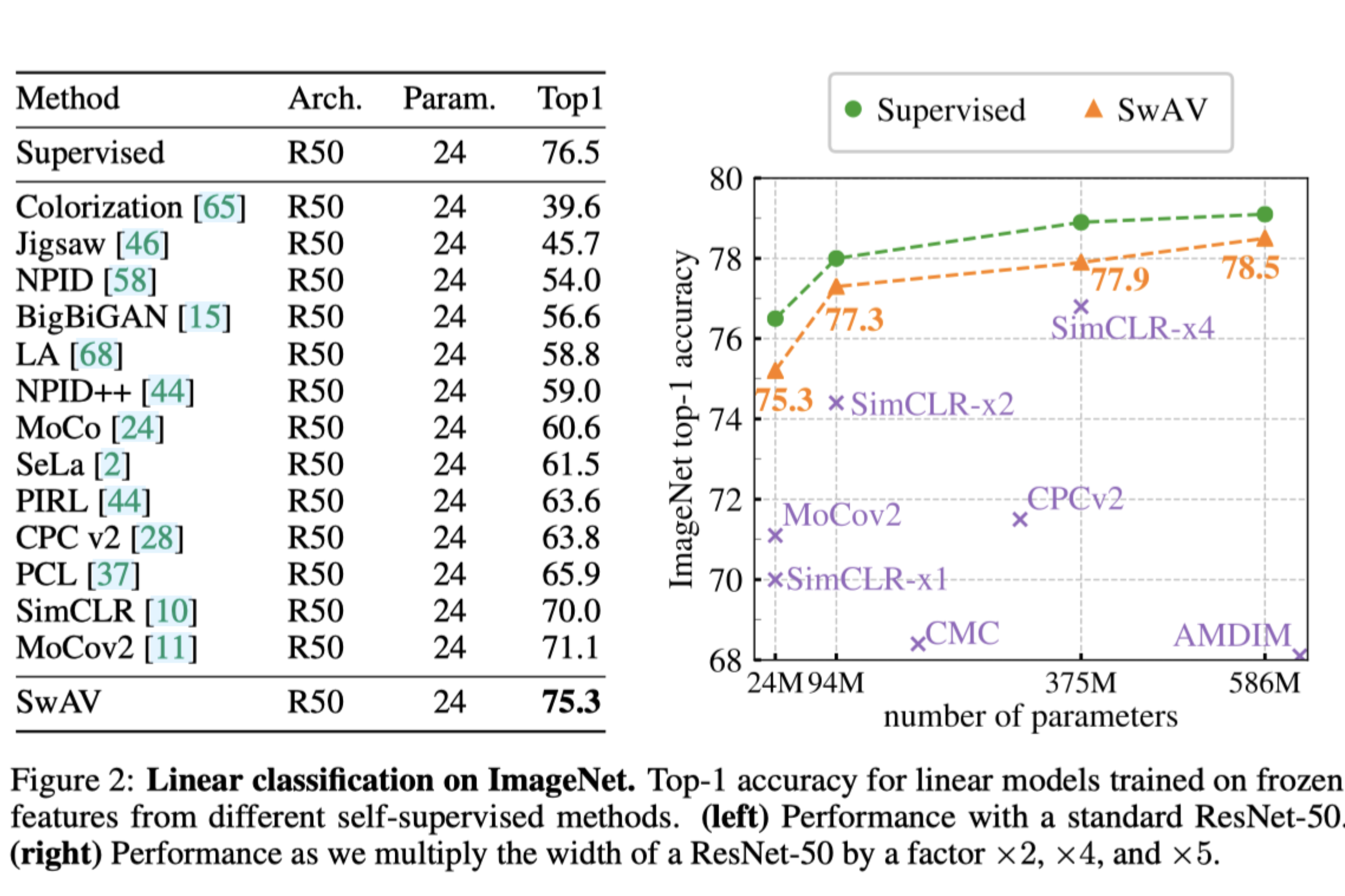
"SwAV(Swapping Assignments between Views)"라는 새로운 SSL 알고리즘을 소개합니다. 이 방법은 최근 contrastive learning 방법들이 달성한 성과에 기반하여, 이미지 표현의 학습에서 지도 학습과의 성능 격차를 상당히 줄이는 새로운 접근 방식을 제시합니다. contrastive learning 방법들이 온라인에서 작동하며 대량의 명시적인 특성 쌍 비교에 의존하는 것과 달리, SwAV는 이러한 특성 쌍 비교 없이도 대조 방법의 이점을 취할 수 있도록 합니다. 특히, SwAV는 동일한 이미지의 다른 변형(또는 "뷰") 사이에서 생성된 클러스터 할당 간의 일관성을 유지하면서 데이터를 클러스터링함으로써 작동합니다. 즉, 대조 학습에서 직접적인 특성 비교 대신에, SwAV는 다른 뷰의 표현을 바탕으로 한 뷰의 코드를 예측하는 "교환된" 예측 메커니즘을 사용합니다.
간단하게 정리하자면, 위의 논문에서는
1. 사자, 호랑이, 고양이 이미지가 존재하고, 해당 이미지들을 증강
2. 증강된 이미지들의 벡터들을 통해서 A, B, C 클러스터링에 들어가도록 분류 진행
3. 사자가 A 클러스터링에 들어가면 사자는 나머지 사진들을 클러스터링 할 수 있음(호랑이, 고양이의 벡터값들이 다르기 때문에)
SwAV(Swapping Assignments between Views)는 이미지의 다양한 변형이나 뷰를 기반으로 클러스터링을 수행하는 SSL 방법입니다. 이 방식은 기존의 contrastive learning과는 달리, 이미지의 특성 자체를 직접 비교하는 대신 이미지 변형 간의 클러스터 할당의 일관성을 유지하여 학습합니다. 이를 통해, SwAV는 이미지의 다양한 뷰에 대한 표현의 일관성을 강조하면서도 효율적인 학습을 가능하게 합니다.
작동 원리
1. 다양한 뷰 생성: 우선, 동일한 이미지에서 두 가지 이상의 변형(또는 뷰)을 생성합니다. 이 변형들은 이미지의 랜덤 크롭, 색상 조정 등 다양한 데이터 증강 기법을 사용하여 생성될 수 있습니다.
2. 클러스터 할당: 각 뷰는 네트워크를 통과하여 특성 벡터로 변환됩니다. 이 특성 벡터들은 사전에 정의된 클러스터 중 하나에 할당됩니다. 이 클러스터 할당은 일종의 "코드"로 간주되며, 이미지가 어떤 클러스터에 속하는지를 나타냅니다.
3. Handcrafted pretext tasks : 핵심 아이디어는 한 이미지 변형의 특성을 사용하여 다른 변형의 클러스터 할당(코드)을 예측하는 것입니다. 예를 들어, 이미지의 첫 번째 변형으로부터 생성된 특성을 사용하여 두 번째 변형의 클러스터 할당을 예측합니다. 이 과정은 모든 변형 쌍에 대해 반복됩니다.
4. 일관성 강제: SwAV의 학습 목표는 각 뷰의 클러스터 할당이 일관되게 유지되도록 하는 것입니다. 즉, 동일한 이미지의 서로 다른 뷰가 동일한 클러스터에 할당되도록 학습 과정에서 네트워크를 조정합니다. 이를 통해, 이미지의 다양한 뷰에서 추출된 특성이 유사하도록 만듦으로써, 더 강력하고 일반화된 이미지 표현을 학습할 수 있습니다.
효율성과 효과성
SwAV의 접근 방식은 대규모 이미지 데이터셋에서도 효율적으로 확장될 수 있으며, 메모리 사용량을 크게 줄입니다. 이는 각 이미지 변형 간의 직접적인 특성 비교를 수행하지 않기 때문입니다. 또한, "교환된" 예측 메커니즘은 클러스터 할당의 일관성을 유지함으로써 보다 풍부한 이미지 표현을 학습하도록 돕습니다. 이러한 방식으로 SwAV는 지도 학습과 비교하여 경쟁력 있는 성능을 달성하며, 특히 다양한 이미지 처리 태스크에서 우수한 전이 학습 능력을 보여줍니다.이 방법은 크고 작은 배치 모두에서 효과적으로 작동하며, 제한 없는 양의 데이터로 확장이 가능합니다. 또한, SwAV는 이전 contrastive learning들이 요구하는 대규모 메모리 은행이나 특별한 모멘텀 네트워크 없이도 더 메모리 효율적으로 작동합니다. 추가로, 다양한 해상도의 뷰를 활용하는 새로운 데이터 증강 전략인 "multi-crop"을 도입하여, 메모리나 계산 요구사항을 증가시키지 않고도 효과를 높입니다. 이러한 기법들을 통합하여, SwAV는 ImageNet에서 ResNet-50을 사용하여 75.3%의 top-1 정확도를 달성하고, 모든 고려된 전달 학습 태스크에서 지도 학습을 초과하는 성능을 보여줍니다.
SSL 학습 방법은 수동 주석 없이 이미지로부터 유용한 특성을 추출하는 것을 목표로 합니다. 이 분야는 최근 몇 년 동안 눈에 띄는 발전을 이루었으며, 이는 주로 인스턴스 차별화라는 개념에 기반을 둔 최신 방법론들 덕분입니다. 인스턴스 차별화 작업은 데이터셋의 각 이미지와 그 변형을 별개의 클래스로 취급하며, 이를 통해 다른 이미지들 사이를 구별할 수 있는 표현을 학습하고 이미지 변형에 대한 일정 수준의 불변성을 달성하려고 합니다.
인스턴스 차별화(instance discrimination)는 컴퓨터 비전과 자기지도 학습에서 사용되는 중요한 개념 중 하나입니다. 이 개념은 데이터셋 내 각각의 개별 이미지(또는 인스턴스)를 독립된 클래스로 취급하여 학습하는 방법을 말합니다. 목적은 모델이 각 인스턴스를 유니크하게 식별하고 구별할 수 있는 강력한 특성을 학습하는 것입니다.
1. 인스턴스 차별화의 핵심 원리
유니크한 표현 학습: 인스턴스 차별화는 모델에게 데이터셋 내의 각 이미지가 서로 다른 특성을 가지고 있음을 학습시킵니다. 이를 통해 모델은 각 이미지에 대해 구별 가능한, 유니크한 표현을 생성하게 됩니다.양의 쌍과 음의 쌍: 학습 과정에서, 이미지의 변형(예: 크롭, 회전 등)은 '양의 쌍'(positive pairs)으로 취급되어, 같은 이미지의 변형끼리는 서로 가깝게 배치됩니다. 반면, 다른 이미지들은 '음의 쌍'(negative pairs)으로 간주되어, 서로 멀어지도록 학습됩니다.
2. 인스턴스 차별화를 사용하는 이유
강인한 특성 학습: 이 방식을 통해, 모델은 이미지의 소소한 변형에도 불구하고 각 이미지를 식별할 수 있는 강인한 특성을 학습할 수 있습니다. 이는 다양한 시각적 작업에서 모델의 성능을 향상시키는 데 도움이 됩니다.
데이터 라벨링의 필요성 감소: 인스턴스 차별화는 라벨이 없는 대규모 데이터셋에서 특히 유용합니다. 각 이미지를 독립된 클래스로 취급하기 때문에, 수동으로 라벨을 붙일 필요가 없으며, 이는 비용과 시간을 크게 절약할 수 있습니다.
3. 인스턴스 차별화의 한계
음의 쌍의 확장성 문제: 대규모 데이터셋에서 모든 가능한 음의 쌍을 고려하는 것은 계산상 매우 비효율적일 수 있습니다. 이는 학습 과정을 느리게 하고, 계산 자원을 많이 요구합니다.
유의미한 음의 쌍의 선택: 데이터셋이 매우 클 경우, 무작위로 선택된 음의 쌍 대부분이 이미 충분히 멀기 때문에, 학습에 큰 도움이 되지 않을 수 있습니다. 따라서 유의미한 음의 쌍을 효과적으로 선택하는 것이 중요합니다.최근의 SSL방법들은 두 가지 주요 요소에 의존합니다: 하나는 Contrastive Loss이며, 다른 하나는 set of image transformations입니다. Contrastive Loss은 이미지 특성을 직접 비교함으로써 인스턴스 클래스의 개념을 제거하고, image transformations은 특성에 인코딩된 robustness를 정의합니다. 이 두 요소는 네트워크가 학습한 결과의 품질에 매우 중요합니다.
이러한 배경 하에, 본 논문에서 제안하는 SwAV(Swapping Assignments between Views) 방법은 대조 학습의 접근 방식을 발전시킵니다. SwAV는 클러스터 할당 간의 일관성을 강제함으로써 데이터를 클러스터링하는 동시에, 대조적 방법의 이점을 활용하는 새로운 온라인 알고리즘입니다. 이 방법은 이미지의 다양한 변형 사이에서 생성된 클러스터 할당을 비교함으로써 작동하며, 이는 직접적인 특성 비교를 필요로 하지 않습니다. 이러한 접근 방식은 계산상의 이점을 제공하며, 크고 작은 배치 크기에도 효과적으로 적용될 수 있습니다.
자기지도 학습(Self-Supervised Learning)
자기지도 학습은 라벨이 없는 데이터로부터 학습 신호를 자동으로 생성하는 방법입니다. 이는 주로 데이터 자체의 구조나 패턴을 이용하여 학습 과제를 정의하고, 이를 통해 유용한 특성을 추출하는 데 사용됩니다. 예를 들어, 이미지에서는 데이터 증강을 통해 생성된 이미지 변형 간의 관계를 학습 과제로 설정할 수 있습니다.
Instance and Contrastive learning
대조 학습은 자기지도 학습의 한 형태로, 데이터 내의 유사한 샘플은 서로 가깝게, 서로 다른 샘플은 멀게 배치하는 방식으로 특성 공간을 학습합니다. 이는 이미지의 변형 간, 또는 서로 다른 이미지 간의 관계를 통해 강력한 특성을 학습하는 데 효과적인 방법으로 입증되었습니다.
Clustering for deep representation learning
SwAV는 클러스터링 기반의 학습 방법론도 참조합니다. 이 접근 방식은 데이터를 자동으로 그룹화하여, 각 그룹 내의 데이터 포인트가 유사한 특성을 공유하도록 합니다. 이는 복잡한 데이터셋 내의 구조를 이해하고, 특정 패턴이나 카테고리를 학습하는 데 도움을 줍니다. SwAV는 이러한 클러스터링 방식을 활용하여, 이미지 변형 간의 클러스터 할당의 일관성을 통한 학습을 제안합니다.
Swapped prediction Mechanism
SwAV의 핵심 기여 중 하나는 "Swapped prediction Mechanism"입니다. 이는 이미지 변형의 특성을 바탕으로 다른 변형의 클러스터 할당을 예측하는 과정을 말합니다. 이 메커니즘은 기존의 직접적인 비교 방식이나 클러스터 내 데이터 포인트 간의 유사성만을 고려하는 접근보다 더 복잡한 데이터의 내재된 구조와 패턴을 포착할 수 있습니다.
SwAV는 전통적인 Handcrafted Pretext Tasks 방식과는 다른 접근 방식을 취합니다.
SwAV는 이미지의 다양한 변형 사이의 클러스터 할당 일관성을 유지하는 것에 초점을 맞춘 SSL방법론입니다. 그러나, SwAV의 기본 개념과 데이터를 변형하고 이를 학습 과제로 사용한다는 점에서, Handcrafted Pretext Tasks와의 관련성을 찾을 수 있습니다.
SwAV와 Handcrafted Pretext Tasks의 관계
1. 데이터 변형: SwAV도 이미지의 다양한 변형을 사용합니다. 이는 Handcrafted Pretext Tasks에서 볼 수 있는 데이터 변형과 유사합니다. 예를 들어, SwAV는 다양한 크기의 크롭이나 색상 변형 등의 데이터 증강 기법을 사용하여 이미지의 여러 뷰를 생성합니다.
2. 자기지도 학습: SwAV는 라벨 없이 이미지 데이터로부터 유용한 특성을 학습합니다. 이는 Handcrafted Pretext Tasks의 목표와 일치합니다. SwAV는 클러스터 할당과 교환된 예측 메커니즘을 통해, 데이터의 내재된 패턴을 학습함으로써 강력한 이미지 표현을 개발합니다.
적용 차이점
1. 학습 과제의 자동화: SwAV는 특정 Handcrafted Pretext Task를 직접적으로 사용하지 않습니다. 대신, 이미지 변형 간의 클러스터 할당 일관성을 유지하는 복잡한 학습 과제를 통해, 더 일반화된 방식으로 이미지 표현을 학습합니다.
2. 클러스터링과 예측: SwAV의 핵심은 이미지 변형을 다양한 클러스터에 할당하고, 이러한 할당을 바탕으로 다른 변형의 클러스터 할당을 예측하는 것입니다. 이 과정은 Handcrafted Pretext Tasks의 명시적인 작업(예: 이미지 회전 각도 예측, 조각 맞추기 등)과는 다른, 모델이 스스로 학습 과제를 해결하도록 하는 방식입니다.
SwAV알고리즘의 구체적인 방법론을 설명합니다. SwAV는 Contrastive Learning의 한 형태로서, 이미지의 다양한 변형 간의 일관된 클러스터 할당을 통해 강력하고 일반화된 이미지 표현을 학습하는 방식입니다. 인공지능 전문가의 입장에서 이 방법을 분석해보겠습니다.
SwAV의 핵심 아이디어
SwAV의 핵심은 각 이미지의 다양한 변형(뷰)을 생성하고, 이 변형들이 같은 클러스터에 할당될 수 있도록 학습하는 것입니다. 이를 통해, 모델은 이미지 변형에 불변하는 특성을 학습하며, 이러한 특성은 이미지의 본질적인 정보를 반영합니다.
SwAV의 주요 컴포넌트
- 데이터 증강 및 변형 생성: SwAV는 먼저 원본 이미지로부터 여러 변형을 생성합니다. 이는 데이터 증강 기법(예: 임의 크롭, 색상 조정, 회전 등)을 사용하여 수행됩니다. 이 과정은 모델이 다양한 시각적 변화에 대해 불변성을 학습할 수 있는 기반을 마련합니다.
- 클러스터 할당 및 'swapped prediction' 메커니즘: 생성된 이미지 변형들로부터 특성을 추출한 뒤, 이 특성을 바탕으로 각 변형을 사전 정의된 클러스터 중 하나에 할당합니다. SwAV는 이 클러스터 할당을 기반으로, 한 변형의 특성을 사용하여 다른 변형의 클러스터 할당을 예측하는 교환된 예측 메커니즘을 적용합니다. 이는 모델이 클러스터 할당의 일관성을 유지하면서도 데이터의 복잡한 구조를 학습할 수 있도록 합니다.
- 손실 함수 및 최적화: SwAV는 클러스터 할당의 일관성을 최대화하는 방향으로 모델을 최적화합니다. 이를 위해, 교환된 예측 메커니즘에서 발생하는 오류를 최소화하는 손실 함수를 정의하고, 이 손실 함수에 따라 모델의 파라미터를 업데이트합니다.
SwAV의 혁신적인 점
- 메모리와 계산 효율: SwAV는 클러스터 할당과 swapped prediction 메커니즘을 사용함으로써, 대규모 이미지 데이터셋에 대한 학습을 메모리와 계산 측면에서 효율적으로 수행할 수 있습니다. 이는 대조 학습에서 흔히 발생하는 대규모 음의 쌍 처리의 필요성을 줄입니다.
- 유연성과 확장성: SwAV는 다양한 데이터 증강 및 변형 기법과 결합할 수 있으며, 다양한 크기의 데이터셋과 네트워크 구조에 적용 가능합니다. 이는 SwAV를 다양한 시각적 태스크에 유연하게 적용할 수 있게 합니다.
"3.1 Online Clustering"은 SwAV(Swapping Assignments between Views) 방법론 내에서 중요한 부분입니다. SwAV는 SSL을 통해 이미지의 다양한 뷰에서 강력한 특성을 학습합니다. 이 과정에서, Online Clustering는 실시간으로 이미지 데이터의 클러스터링을 수행하고, 이 클러스터 정보를 바탕으로 모델을 학습시키는 메커니즘입니다.
Online Clustering의 핵심 개념
Online Clustering은 데이터 포인트가 순차적으로 주어질 때, 실시간으로 클러스터를 형성하고 업데이트하는 과정입니다. SwAV에서는 이를 이미지의 특성 공간 내에서 수행합니다. 각 이미지 뷰의 특성을 추출한 후, 이 특성들을 사전에 정의된 클러스터 중 하나에 할당합니다. 이 클러스터링 과정은 다음과 같은 목적을 가지고 있습니다:
- 데이터의 구조 파악: 데이터 내의 복잡한 구조와 패턴을 학습하고, 유사한 특성을 가진 데이터 포인트들을 같은 클러스터에 그룹화함으로써, 모델이 데이터를 보다 효과적으로 이해할 수 있도록 합니다.
- 특성의 불변성 학습: 클러스터링을 통해, 모델은 이미지 변형에도 불구하고 일관된 특성을 유지하는 방법을 학습합니다. 이는 불변성(invariance)이라고 하며, 다양한 시각적 조건 하에서도 이미지를 일관되게 인식할 수 있는 능력을 의미합니다.
Online Clustering의 구현 방법
SwAV에서 Online Clustering은 다음 단계로 구현됩니다:
- 데이터 증강: 각 이미지로부터 여러 변형(뷰)을 생성합니다.
- 특성 추출: 생성된 각 뷰를 신경망을 통과시켜 특성 벡터를 추출합니다.
- 소프트 클러스터 할당: 추출된 특성 벡터를 기반으로, 각 뷰를 사전에 정의된 클러스터 중 하나에 소프트 할당합니다. 이 과정에서, 각 뷰는 하나 이상의 클러스터에 속할 수 있으며, 소속 확률을 가집니다.
- Swapped prediction 메커니즘: 하나의 뷰의 특성을 사용하여 다른 뷰의 클러스터 할당을 예측합니다. 이는 모델이 클러스터 할당의 일관성을 유지하도록 하며, 학습 과정에서 이 일관성을 최대화하려고 노력합니다.
Online Clustering의 이점
- 유연성과 확장성: Online Clustering은 데이터셋의 크기에 관계없이 효율적으로 작동할 수 있으며, 실시간 데이터 스트림에서도 클러스터를 형성하고 업데이트할 수 있습니다.
- 특성 학습의 효율성: 이 방법은 모델이 데이터의 내재된 구조를 더 잘 이해하고, 강력한 이미지 특성을 효율적으로 학습할 수 있게 합니다.
Online Clustering의 학습 과정 최적화
SwAV 방법론에서는, 클러스터 할당 과정을 최적화하기 위해 몇 가지 특별한 기술을 사용합니다:
- Sinkhorn-Knopp 알고리즘: 클러스터 할당 과정에서 발생할 수 있는 균형 문제를 해결하기 위해, SwAV는 Sinkhorn-Knopp 알고리즘을 사용하여 클러스터 할당을 정규화합니다. 이 알고리즘은 전체 데이터셋에 대한 클러스터 할당이 균등하게 분포하도록 돕습니다, 즉, 모든 클러스터가 대략적으로 동일한 수의 데이터 포인트를 가지도록 합니다. 이는 클러스터의 편향을 방지하고, 더욱 균형 잡힌 학습을 가능하게 합니다.
- Multi-crop strategy: SwAV는 다양한 크기의 이미지 크롭을 사용하는 multi-crop 전략을 도입합니다. 이는 큰 크롭과 작은 크롭을 함께 사용함으로써, 모델이 이미지의 전역적인 구조뿐만 아니라 세부적인 특성에 대해서도 학습할 수 있게 합니다. 이 전략은 이미지의 다양한 해상도에서 유의미한 특성을 추출하는 데 도움을 주며, 모델의 일반화 능력을 향상시킵니다.
Online Clustering을 통한 학습의 장점
Online Clustering과 이와 관련된 최적화 기법들을 통해 SwAV는 다음과 같은 주요 장점을 가집니다:
- 데이터의 복잡성 이해: 모델은 다양한 뷰에 대한 클러스터 할당의 일관성을 유지하면서, 이미지 데이터의 복잡한 구조와 패턴을 효과적으로 학습합니다.
- 강력한 특성 추출: SwAV는 이미지의 본질적인 특성과 불변성을 학습함으로써, 다양한 시각적 태스크에서 사용할 수 있는 강력한 특성 표현을 개발합니다.
- 효율적인 학습 과정: Sinkhorn-Knopp 알고리즘과 multi-crop 전략을 포함한 최적화 기법들은 학습 과정의 효율성을 크게 향상시킵니다.
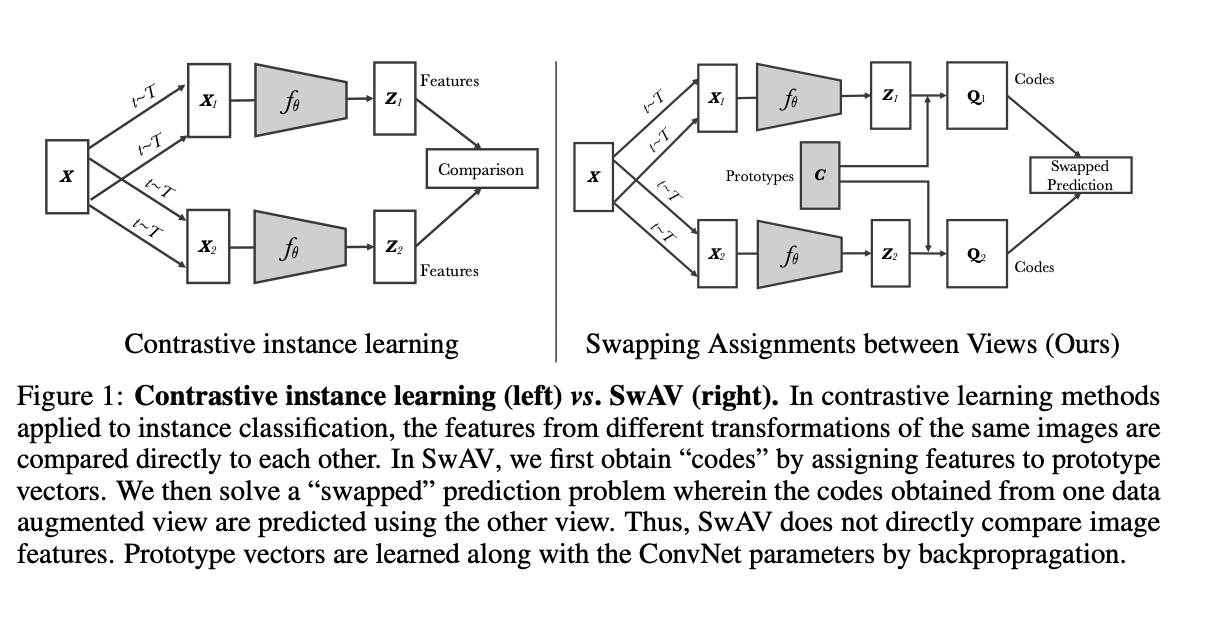
Contrastive Instance Learning방법과 SwAV방법을 비교하는 구조도를 나타냅니다.
Contrastive Instance Learning
- 대조적 인스턴스 학습 방법은 원본 이미지 $X$에서 여러 변형 $X_1, X_2, ... 을 생성합니다.
- 이 변형된 이미지들은 각각 특징 추출기 $f_\theta 를 통과하여 특성 벡터 $Z1,Z2,...로 변환됩니다.
- 변환된 특성 벡터들은 서로 직접 비교되어, 유사한 이미지 변형끼리는 서로 가깝게, 다른 이미지 변형끼리는 멀게 배치되도록 합니다.
- 이러한 과정은 이미지들의 유사성을 인코딩하여 각 인스턴스를 독립적으로 식별할 수 있는 강력한 특성을 학습하는 데 목표를 둡니다.
SwAV
- SwAV 방법론에서도 원본 이미지 $X$로부터 여러 변형 $X_1, X_2, ... 을 생성합니다.
- 각 변형된 이미지는 동일한 특징 추출기 $f_\theta 를 통과하여 특성 벡터 $Z1,Z2,...로 변환됩니다.
- 다음으로, 변환된 특성 벡터는 프로토타입 벡터(Prototypes )에 할당되어 코드 $ Q_1, Q_2, ... 가 생성됩니다. 이 코드는 클러스터 할당을 나타냅니다.
- SwAV의 핵심은 한 데이터 뷰에서 얻은 코드를 사용하여 다른 뷰의 클러스터 할당을 "Swapped"하여 예측하는 것입니다. 이는 한 이미지의 변형이 어떻게 다른 변형을 인코딩하는지 학습하는 문제를 해결합니다.
- SwAV는 이미지 특성을 직접 비교하지 않고, 대신 클러스터 할당의 일관성을 통해 특성을 학습합니다. 프로토타입 벡터는 학습 과정에서 ConvNet 파라미터와 함께 업데이트되며, 이를 통해 강력한 이미지 표현이 학습됩니다.

첫 번째 수식은 SwAV의 핵심 손실 함수인 교차 엔트로피 손실을 나타냅니다. 여기서의 목적은 특정 이미지 변형 $ Z_t $에 대한 모델의 예측 확률 $ P_t $가 실제 클러스터 할당 $ Q_s $와 일치하도록 만드는 것입니다. 이 수식을 좀 더 자세히 분해하여 설명해보겠습니다.
손실 함수 $( \ell )$
$\ell(Z_t, Q_s) = -\sum_k q_s^{(k)} \log p_t^{(k)}$
- $ \ell(Z_t, Q_s) $는 타겟 변형 $ Z_t $의 특성 벡터와 소스 변형의 클러스터 할당 $ Q_s $ 사이의 교차 엔트로피 손실을 나타냅니다.
- $ q_s^{(k)} $는 소스 변형이 $ k $ 클러스터에 할당된 확률을 나타냅니다.
- $ p_t^{(k)} $는 타겟 변형의 특성 $ Z_t $를 기반으로 계산된 $ k $ 클러스터에 대한 모델의 예측 확률입니다.
- 교차 엔트로피 손실은 실제 확률 분포와 모델이 예측한 확률 분포 사이의 일치도를 측정하는 데 사용됩니다.
확률 $ P_t $
$ p_t^{(k)} = \frac{\exp(\frac{1}{\tau}Z_t^T c_k)}{\sum_{k'} \exp(\frac{1}{\tau}Z_t^T c_{k'})} $
- $ p_t^{(k)} $는 모델이 $ Z_t $가 $ k $ 클러스터에 속한다고 예측하는 소프트맥스 확률입니다.
- $ c_k $는 $ k $ 클러스터의 프로토타입(또는 중심) 벡터입니다.
- $ Z_t^T c_k $는 타겟 변형의 특성 벡터와 클러스터의 프로토타입 벡터 사이의 내적을 의미합니다. 이 값은 변형과 프로토타입 간의 유사도를 나타내며, 높을수록 $ Z_t $가 $ c_k $에 더 가깝다는 것을 의미합니다.
- $ \tau $는 온도 매개변수로, 이 값에 따라 분포의 '평활성'이 결정됩니다. 온도가 낮으면 몇몇 클러스터에 대한 확률이 높아지고, 높으면 확률 분포가 더 평활해집니다.
핵심 요약
이 손실 함수는 모델이 각 클러스터 프로토타입과 얼마나 잘 일치하는지를 기준으로 특성 벡터 $ Z_t $를 평가합니다. 각 클러스터 프로토타입은 데이터의 특정 영역을 대표하며, 모델이 이 손실 함수를 최소화하도록 학습함으로써, 각 이미지 변형의 특성이 올바른 클러스터에 할당될 수 있도록 유도합니다.SwAV의 학습 과정에서 사용되는 "소스 변형(source view)"와 "타겟 변형(target view)"은 같은 이미지에서 파생된 두 가지 다른 변형을 의미합니다. 이 개념은 이미지가 여러 변형을 겪을 때, 각 변형이 독립적인 클러스터링 할당을 받아 모델에 의해 비교 및 학습되는 방식에 기반합니다.
소스 변형 (Source View)
- 소스 변형은 기준이 되는 이미지 변형으로서, 이 변형에 대한 클러스터 할당(또는 코드) $ Q_s $가 이미 주어져 있습니다.
- 이 클러스터 할당은 모델의 특정 뷰(즉, 이미지 변형)에 대해 이미 계산된 것으로, 이 뷰가 어떤 프로토타입 클러스터에 얼마나 잘 일치하는지 나타냅니다.
- 이는 다른 변형(타겟 변형)의 클러스터 할당을 예측하는 데 사용되는 "진실" 또는 레퍼런스로 작용합니다.
타겟 변형 (Target View)
- 타겟 변형은 같은 원본 이미지에서 파생되지만, 소스 변형과 다르게 처리된 이미지 변형입니다.
- 이 변형의 특성 벡터 $ Z_t $를 사용하여, 모델은 소스 변형에 대한 클러스터 할당 $ Q_s $를 예측하려고 시도합니다.
- 타겟 변형에 대한 예측된 클러스터 할당은 소스 변형의 실제 할당과의 일치도를 측정하여 모델의 손실을 계산하는 데 사용됩니다.
Swapped Prediction 메커니즘
SwAV는 이러한 두 가지 변형을 활용하여 "swapped prediction" 메커니즘을 구현합니다. 이는 소스 변형의 클러스터 할당을 타겟 변형의 클러스터 할당을 예측하는 데 사용하고, 이를 통해 모델이 다음과 같은 것을 학습하도록 유도합니다:
- 데이터의 내재된 구조: 모델은 다양한 변형에서 일관된 클러스터 할당을 유지하며, 이를 통해 이미지의 본질적인 특성과 데이터 내의 패턴을 학습합니다.
- 불변성: 여러 변형에 걸쳐 일관된 클러스터 할당을 유지함으로써, 모델은 변형에 불변하는 특성을 인코딩하고, 이를 통해 강력한 시각적 표현을 학습합니다.
이와 같은 방식으로 소스 변형과 타겟 변형은 SwAV 모델에서 중요한 역할을 하며, 모델이 자기지도 학습을 통해 이미지 데이터로부터 효과적인 특성을 추출하고 학습하는 데 기여합니다.
두 번째 수식: 손실 함수의 확장
이 수식은 SwAV에서 사용되는 대조적인 손실 함수입니다. 이 손실 함수는 모델이 이미지의 서로 다른 변형 사이에서 일관된 클러스터 할당을 학습하도록 하는 것을 목적으로 합니다. 수식을 분석해 보겠습니다.
손실 함수의 개요
손실 함수는 $ N $개의 데이터 포인트 각각에 대해 계산됩니다. $ N $은 배치 사이즈를 의미하며, 각 이미지 변형 $ n $에 대해 소스 변형 $ s $와 타겟 변형 $ t $가 있습니다. 손실은 이들 각각에 대해 계산되고 평균됩니다.
수식 내 각 부분의 의미
1. $ \frac{1}{N} \sum_{n=1}^N \sum_{s,t\sim \mathcal{T}} $
- 이 부분은 모든 이미지 변형 쌍 $ s $, $ t $에 대한 평균 손실을 계산합니다. $ \mathcal{T} $는 변형들의 집합을 나타냅니다.
2. $ -\frac{1}{\tau} z_{nt}^T C q_{ns} + \frac{1}{\tau} z_{ns}^T C q_{nt} $
- $ z_{nt} $와 $ z_{ns} $는 각각 타겟과 소스 변형의 특성 벡터입니다.
- $ q_{ns} $와 $ q_{nt} $는 소스와 타겟 변형에 대한 클러스터 할당 벡터입니다.
- $ C $는 모든 클러스터 프로토타입 벡터를 포함하는 행렬입니다.
- 이 항들은 각 변형의 특성 벡터가 해당 클러스터 할당에 얼마나 잘 부합하는지를 나타냅니다.
3. $ \log \sum_{k=1}^K \exp(\frac{1}{\tau} z_{nt}^T c_k) $와 $ \log \sum_{k=1}^K \exp(\frac{1}{\tau} z_{ns}^T c_k) $
- 이 두 항은 소프트맥스 정규화를 수행합니다. 내부의 지수 함수는 각 클러스터 프로토타입과 특성 벡터 간의 유사도를 나타내며, 온도 매개변수 $ \tau $로 조정됩니다.
- 소프트맥스 정규화는 타겟 변형이나 소스 변형의 특성이 모든 클러스터에 얼마나 잘 부합하는지를 확률적으로 나타냅니다.
손실 함수의 작동 원리
이 손실 함수는 크게 두 부분으로 작동합니다:
- 첫 번째 부분 : 모델이 타겟 변형의 특성 $ z_{nt} $를 사용하여 소스 변형 $ s $의 클러스터 할당 $ q_{ns} $를 얼마나 잘 예측할 수 있는지 측정합니다.
- 두 번째 부분 : 이와 동시에 소스 변형의 특성 $ z_{ns} $을 사용하여 타겟 변형의 클러스터 할당 $ q_{nt} $를 얼마나 잘 예측할 수 있는지 측정합니다.
이 손실 함수를 최소화함으로써 모델은 이미지 변형 간의 일관된 클러스터 할당을 학습하게 됩니다. 이는 모델이 변형에 강인한 특성 표현을 학습하게 하며, 실제로는 이미지에 포함된 복잡한 구조를 파악하고 추상화하는 능력을 개발합니다.이 과정을 통해 모델은 이미지의 뷰에 대한 구체적인 특성들을 넘어서서, 이미지의 뷰들이 공유하는 더 깊은 패턴과 구조를 학습할 수 있습니다. 이를 통해 모델은 새로운 데이터나 미래의 다양한 시각적 태스크에서 더 나은 일반화와 성능을 보일 수 있습니다.
손실 함수가 최소화될 때, 모델은 각 변형의 특성 벡터가 해당 변형이 속한 클러스터의 프로토타입 벡터와 얼마나 일치하는지를 적절히 예측할 수 있게 되는데, 이는 각 이미지가 어떤 클러스터에 속해야 하는지를 결정하는 것이 아니라, 이미지 변형 사이에서 일관된 클러스터 할당을 유지하는 것이 중요합니다.
따라서 SwAV의 손실 함수는 라벨이 없는 데이터에서도 효과적인 특성 학습을 가능하게 하는 중요한 역할을 수행합니다. 이 방식은 다양한 데이터 증강과 결합하여 강력한 이미지 표현을 생성하는 현대의 자기지도 학습 기법 중 하나입니다.
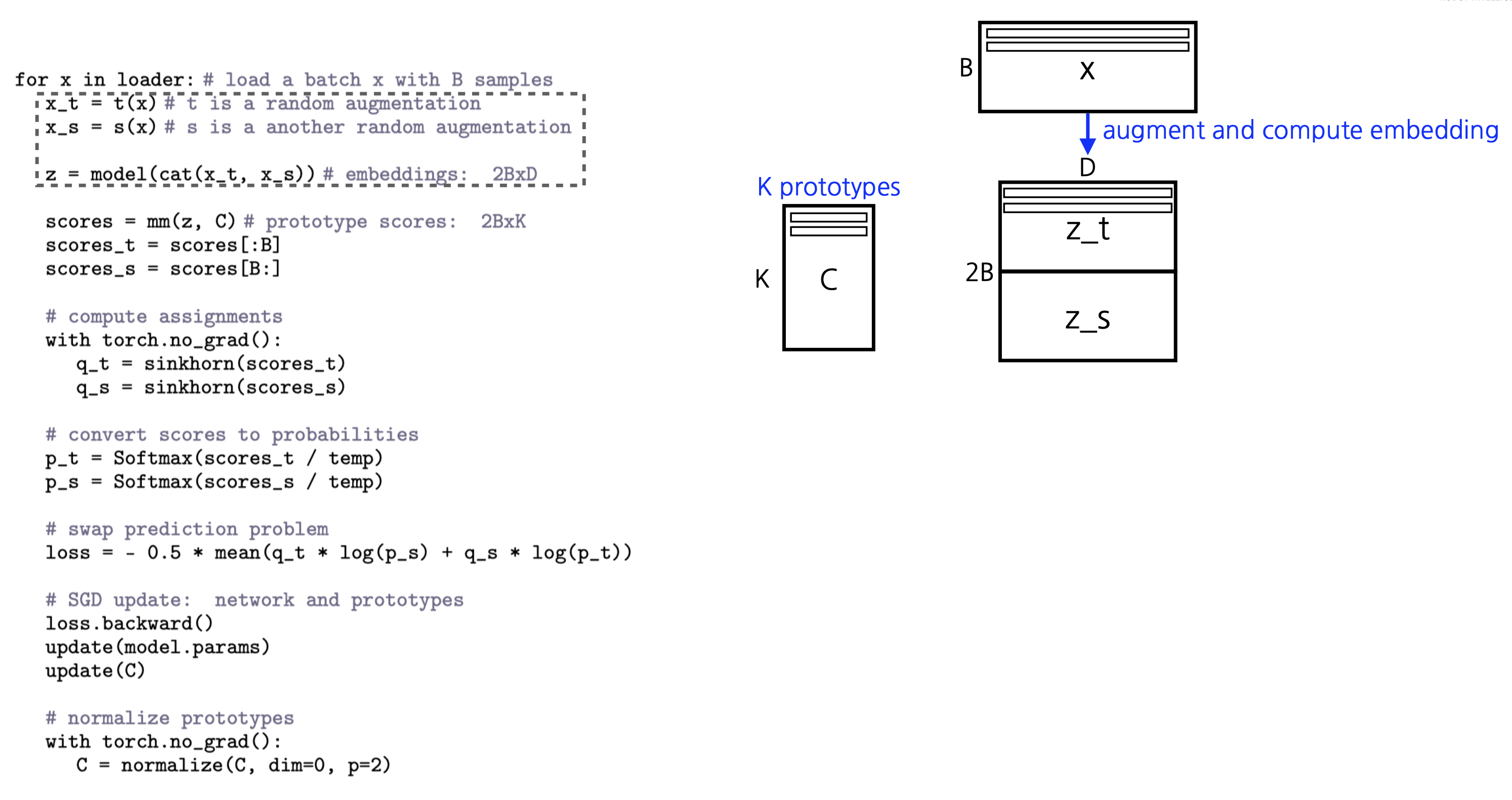
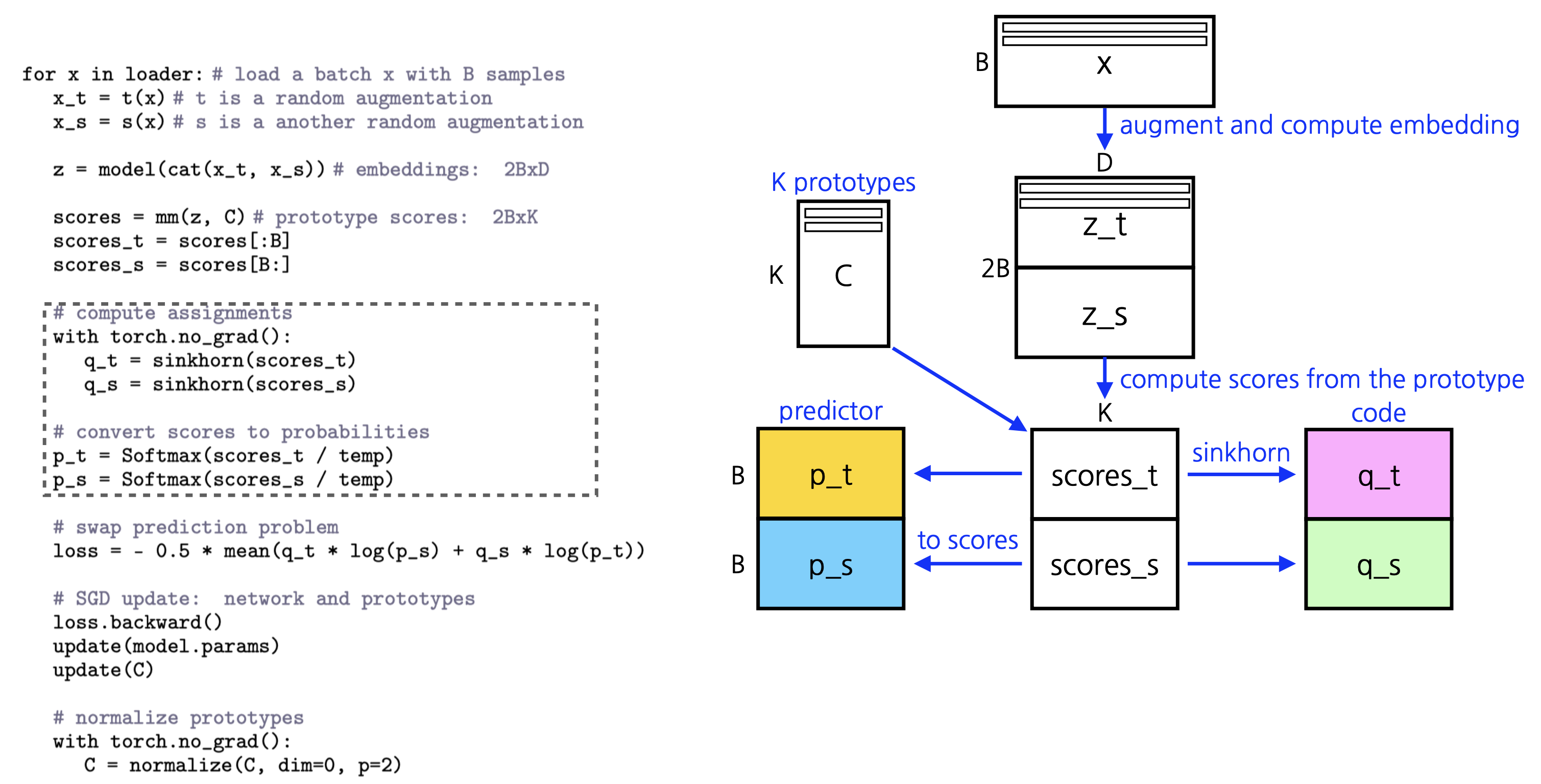
SwAV(Swapping Assignments between Views) 알고리즘에서 "Computing codes online"은 실시간으로 이미지의 특성을 클러스터 프로토타입에 매핑하는 과정을 말합니다. 이 과정은 특성 추출과 클러스터 할당을 학습 단계마다 동시에 수행함으로써 효율성을 높이고, 모델이 실제 학습 시간에 이미지를 어떻게 그룹화할지 결정하게 합니다.
자세한 내용은 다음과 같습니다:
- 특성 추출:
- 네트워크는 입력 이미지의 변형들로부터 특성을 추출합니다. 이는 일반적으로 CNN(Convolutional Neural Network)을 통해 수행되며, 네트워크의 마지막 계층에서 얻은 특성 벡터들은 이미지의 추상적인 표현을 제공합니다.
- 실시간 클러스터 할당:
- 추출된 특성 벡터들은 클러스터 프로토타입에 매핑됩니다. SwAV에서는 이를 위해 Sinkhorn-Knopp 알고리즘과 같은 최적화 기법을 사용하여 특성 벡터와 클러스터 프로토타입 간의 관계를 신속하게 조정합니다.
- 코드 생성:
- 각 특성 벡터에 대해, 네트워크는 클러스터 할당을 나타내는 코드를 생성합니다. 이 코드는 소프트 할당을 통해 표현되며, 각 이미지 변형이 각 클러스터 프로토타입과 얼마나 유사한지를 나타내는 확률 분포입니다.
- 손실 계산 및 업데이트:
- 생성된 코드를 사용하여, 네트워크는 'swapped prediction'을 수행합니다. 이는 다른 변형의 클러스터 할당을 예측하고, 그 결과를 손실 함수에 적용하여 네트워크의 가중치를 업데이트합니다.
- 역전파:
- 계산된 손실에 대해 역전파를 수행하여 네트워크 파라미터를 업데이트합니다. 이 과정에서 프로토타입 벡터도 학습되며, 학습된 프로토타입은 데이터 내의 구조적인 패턴을 반영하게 됩니다.
"Computing codes online"의 주된 이점은 메모리 효율성과 실시간 클러스터 조정 능력입니다. 데이터를 배치로 처리하면서, 각 배치에 대한 특성과 코드를 실시간으로 계산하고 할당함으로써, SwAV는 대규모 데이터셋에도 확장 가능하며 효과적인 클러스터링을 수행할 수 있습니다. 이는 대량의 이미지 변형들을 처리할 수 있게 하며, 모델이 풍부하고 복잡한 데이터로부터 강력한 이미지 표현을 학습하도록 돕습니다.
SwAV에서는 큰 배치 크기가 성능에 중요한 역할을 합니다. 큰 배치 크기를 사용하면 다양한 이미지와 변형에 대한 충분한 정보를 모델이 활용할 수 있어, 일관된 클러스터 할당과 더 나은 일반화가 가능해집니다. 그러나, 모든 경우에 큰 배치를 사용할 수 있는 것은 아니며, 하드웨어 자원이 제한적일 수 있습니다. "Working with small batches"라는 맥락은 이러한 제약 속에서도 효과적인 학습을 할 수 있는 방법에 대한 설명을 포함할 수 있습니다.
작은 배치 크기의 문제점
- 정보의 한계: 작은 배치 크기는 모델이 각 학습 단계에서 접근할 수 있는 정보의 양을 제한합니다. 이는 클러스터링의 품질에 영향을 줄 수 있으며, 모델이 충분한 정보 없이 판단해야 하는 상황을 만듭니다.
- 클러스터 할당의 불안정성: 작은 배치 크기는 클러스터 할당이 불안정해지는 원인이 될 수 있습니다. 각 배치가 전체 데이터 분포를 충분히 대표하지 못할 수 있기 때문입니다.
- 일반화의 어려움: 모델이 제한된 컨텍스트에서만 학습을 진행하면, 학습된 특성의 일반화 능력이 저하될 수 있습니다.
작은 배치 크기로 효과적으로 작업하는 방법
- 데이터 증강 강화: 데이터의 변형을 최대화하여 작은 배치 내에서도 다양성을 증가시킵니다. 이렇게 하면 모델이 더 다양한 특성을 경험할 수 있게 됩니다.
- 정규화 기법: 드롭아웃, 가중치 감쇠 등과 같은 정규화 기법을 사용하여 과적합을 방지합니다.
- Memory Bank or Queue: 메모리 뱅크나 큐를 사용하여 이전 배치들로부터의 정보를 저장하고 활용합니다. 이는 모델이 한 번에 제한된 수의 예시로부터 학습하는 대신 더 큰 컨텍스트에서 학습할 수 있도록 해줍니다.
- Accumulated Gradients: 배치마다 바로 가중치를 업데이트하지 않고, 여러 배치의 그래디언트를 축적(accumulate)하여 한 번에 업데이트하는 방식을 사용할 수 있습니다. 이는 작은 배치로도 큰 배치와 유사한 업데이트 효과를 낼 수 있게 합니다.
- 파라미터 조정: 학습률(learning rate)이나 온도 매개변수(temperature parameter)와 같은 학습 파라미터를 조정하여, 작은 배치 사이즈에 맞게 모델이 더 효율적으로 학습하도록 만듭니다.
SwAV 방법론에서 "Multi-crop" 기법은 이미지 증강을 위한 전략 중 하나입니다. 이 기법은 큰 이미지 뷰와 함께 더 작은 이미지 뷰들을 사용하여 학습에 다양성을 더하는 방식입니다. 크고 작은 다양한 크기의 이미지 크롭(crops)을 사용함으로써 모델은 이미지의 다양한 해상도와 세부적인 특징을 함께 학습할 수 있게 됩니다.
Multi-crop의 작동 원리:
- 다양한 해상도: 원본 이미지로부터 여러 크기의 크롭을 생성합니다. 이는 대형 크롭이 이미지의 전반적인 구조와 컨텍스트를 잡아내는 데 유리한 반면, 소형 크롭은 이미지의 미세한 세부 사항과 패턴을 포착하는 데 도움이 됩니다.
- 세부 특성 학습: 더 작은 크롭을 사용하면 모델이 지역적인 특징과 질감에 더 집중하도록 유도할 수 있습니다. 이는 특히 질감이나 패턴 인식과 같이 세부적인 정보가 중요한 시각적 태스크에 도움이 됩니다.
- 일관된 클러스터 할당: 여러 크기의 크롭을 사용하면, 모델은 서로 다른 해상도에서도 일관된 클러스터 할당을 유지하는 방법을 학습해야 합니다. 이는 전체 이미지와 그것의 일부분이 동일한 개념을 표현할 수 있음을 의미합니다.
- 학습 효율성 증가: 다양한 크기의 이미지 뷰를 통합하여 사용함으로써, 모델은 한 번의 학습 반복(iteration)에서 더 많은 샘플과 시나리오를 경험하게 되고, 결과적으로 학습 과정이 더 효율적이고 효과적이 됩니다.
- 보다 강력한 특성 추출: 이 방법을 통해 모델은 단순히 전역적인 패턴만이 아니라 지역적인 패턴까지도 인식할 수 있는 강력한 특성 추출기를 개발할 수 있습니다. 이는 특히 자기지도 학습 방법론에서 중요하며, 다운스트림 태스크(예: 객체 감지, 분류 등)의 성능을 향상시킬 수 있습니다.
Multi-crop 기법은 SwAV를 비롯한 다양한 자기지도 학습 방법론에서 데이터 증강 전략으로 활용되며, 복잡하고 다양한 실세계 이미지 데이터에 대한 모델의 일반화 및 추론 능력을 강화하는 데 기여합니다.



'논문' 카테고리의 다른 글
9. Attention Is All You Need (0) 2024.03.31 8. MULTI-TASK INFERENCE:Can Large Language Models Follow Multiple Instructions at Once? (0) 2024.03.26 6. Bootstrap Your Own Latent A New Approach to Self-Supervised Learning (0) 2024.03.23 5. A Simple Framework for Contrastive Learning of Visual Representations (2) 2024.03.22 4. GAUSSIAN ERROR LINEAR UNITS (GELUS) (0) 2024.03.21