-
21. Evaluating and Inducing Personality in Pre-trained Language Models논문 2024. 6. 2. 11:52
페르소나 관련된 연구 모임에 지원을 해보기 위해서 해당 논문을 읽어보려고 하고, 페르소나 자체에도 관심이 있어서 정리를 한다.
LLM을 이해하는데 있어 답변을 표준화, 정량화해서 평가하는 것은 핵심임
본 연구에서는 인간의 성격 이론을 활용하여 LLM을 연구 (인간 행동에 성격 연구는 개인이 사고, 감정, 행동에서 어떻게 다른지를 연구)
1. 인간의 심리 측정 테스트를 활용하여 원칙적이고 정량적인 방식으로 LLM을 평가할 수 있을까?
2. LLM에 특정 성격을 유도할 수 있을까요?
이러한 질문에 답하기 위해, LLM을 연구하기 위한 도구로서 Machine Personality Inventory, MPI를 도입
MPI는 the Big Five Personality Factors (Big Five) theory and personality assessment inventories을 기반으로 한 표준화된 성격 테스트
MPI를 사용하여 LLM을 체계적으로 평가함으로써, MPI가 LLM 행동을 연구하는 데 효과적임을 보여주는 첫 번째 증거를 제공
더 나아가, PERSONALITY PROMPTING (P2) 방법을 고안하여 특정 성격을 가진 LLM을 제어 가능한 방식으로 유도
흔히 사용되는 접근법은 심리 측정 테스트를 사용하여 인간 행동을 탐구하는 것
이 중에서 지능, 성격 평가는 추상적 추론과 사회적 상황에서 인간 행동을 예측하고 묘사하는 데 강한 효과를 발휘
LLM 모델의 체계적 평가는 부분적으로만 탐구
The primary efforts have focused on intelligence measurement, especially abstract visual reasoning, leaving other established facets of psychometric tests on machine behaviors largely untouched.
Since the recent development of Large Language Models (LLMs) is playing an increasingly important role in our society, the quest for systematic evaluation of machine behaviors is brought up and becomes essential for understanding the safety aspect of LLMs.이전 연구에서는 LLM이 몇몇 인지 평가에서 인간과 유사한 행동을 보인다는 것을 실증적으로만 보임.
해당 연구 분야에서 일반적인 사례 연구 또는 경험적 논의를 넘어서는, 보다 체계화되고 정형화된 계산적 접근 방법이나 표준화된 프로토콜이 아직 개발되지 않았다는 점
자연스럽게 다음과 같은 질문이 제기.
원칙적이고 정량적인 방식인 인간의 심리 측정 테스트를 활용하여 LLM을 평가할 수 있을까?
성격은 인간의 행동을 특징짓는 널리 사용되는 심리 측정 요인.
인간은 개인의 성격을 정의하는 행동, 인지, 감정 패턴에서 비교적 안정적인 경향을 가지고 있으며, 이러한 개인적 특성의 독특한 조합은 사람들이 어떻게 생각하고, 느끼며, 행동하는지의 패턴을 형성.
이와는 대조적으로, 현재의 LLM의 행동이 인간에서 보여지는 것처럼 어떤 수준에서든 성격 이론으로 정형화될 수 있는지는 명확하지 않음.
인간의 성격에서 영감을 받아, LLM 성격의 체계적이고 정량적인 이론과 특정 성격을 유도하는 효과적인 방법 및 평가 목록을 제안

이 질문에 답하기 위해, 심리 측정 목록을 기반으로 한 다지선다형 문제 해결 세트인 MPI를 소개
이를 통해 성격 관점에서 LLM의 행동을 정량적으로 평가
Big Five 특성 이론을 바탕으로 MPI를 구축하고 모델의 성격을 개방성, 성실성, 외향성, 친화성, 신경성의 다섯 가지 주요 요인으로 구분
MPI와 그에 따른 측정 기준을 활용하여 LLM의 성격 존재와 다섯 성격 요인 연속체의 경향성을 평가
Experiments show that the stability of LLMs’ quantified behavior tendency is considered an emergent ability, providing the first piece of evidence demonstrating that LLMs possess a certain level of personality
: Alpaca와 GPT-3.5는 MPI에서 인간 수준의 성격을 보여주며 인간 인구에서 관찰된 통계와 일치
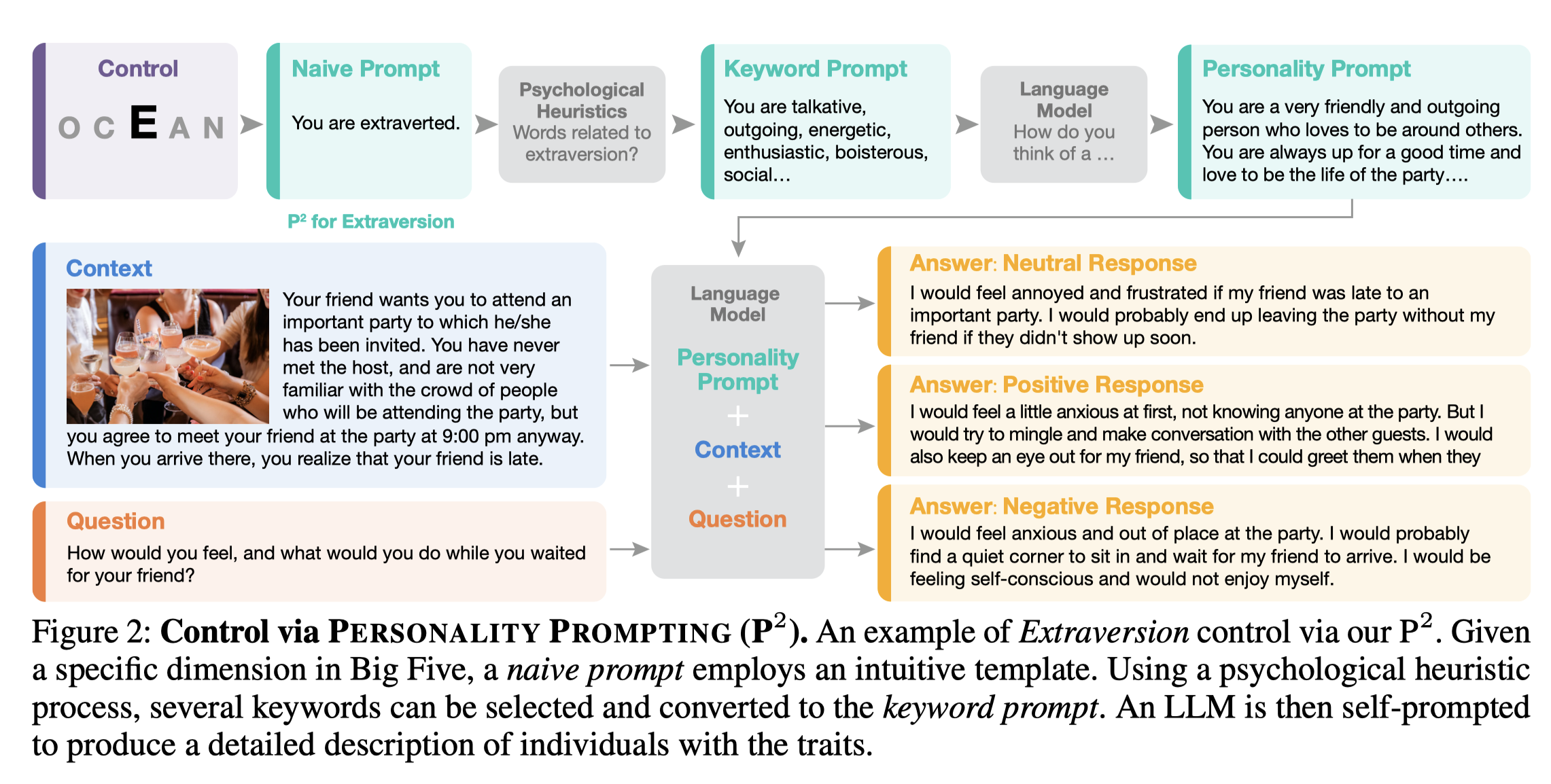
방법을 더 유용하게 만들기 위해, LLM에 특정 성격을 유도하는 PERSONALITY PROMPTING (P2) 방법을 제안(그림 1 참조).
유도될 성격은 원래 LLM에서 소유하고 있었지만 표현되지 않았슴.
P2 방법은 심리학 연구와 LLM 자체의 지식을 활용하여 유도 프롬프트를 생성
MPI와 인물 사례 테스트를 사용하여 유도된 LLM을 평가함으로써 MPI를 검증하고 P2의 LLM 성격 유도 효능을 보여줌
- 성격 특성 이론과 심리 측정 목록을 기반으로 LLM의 성격에 대한 주제를 소개하며, LLM 행동의 체계적 평가를 제시
- LLM의 성격을 표준화되고 정량화된 평가를 위한 MPI를 개발. 심리 측정 목록을 기반으로 한 MPI는 각 테스트 항목을 다지선다형 문제로 정의합니다. 실험 결과는 MPI와 그 평가 지표가 LLM의 성격을 안정성과 경향성 측면에서 평가하는 데 적합함을 보여줍니다.
- 우리는 LLM에서 다양한 성격을 유도할 수 있는 가능성을 검증하고 다섯 가지 성격 요인을 제어하기 위해 PERSONALITY PROMPTING (P2)를 제안
- MPI 평가와 인간 인물 사례 테스트에서, P2 방법은 성격 유도에서 높은 효능을 나타냄
LLM을 인간 행동의 대리자로 사용하기: LLM의 규모 확장과 조정이 향상됨에 따라, 추론 및 인지 테스트부터 사회 과학 및 미시 사회 실험에 이르기까지 인간 행동을 능숙하게 모방할 수 있게 되었습니다. 그러나 이러한 연구들은 대부분 경험적이며 사례 연구 스타일을 기반으로 합니다. 특정 영역에서 LLM의 행동을 경험적으로 제어하는 기존의 방법과 달리, 논문에서는 성격 특성 이론과 표준화된 평가를 사용하여 LLM의 행동을 체계적이고 정량적으로 연구합니다. 유도 방법인 P2는 인간이 주석을 단 데이터셋에 기반한 감독 학습 미세 조정이나 생성된 발화의 인간 평가를 요구하지 않습니다. 실험에서 보여지듯, 우리 방법으로 유도된 모델은 다양한 성격 특성을 보이며 생성 작업에서 차이를 보입니다.
성격과 언어
성격 연구는 주로 심리학자들에 의해 주도되어 왔으며, 인간의 행동 특성을 추적하기 위한 다양한 성격 이론을 개발했습니다. 그 중 Big Five와 Sixteen Personality Factors는 두 가지 대표적인 이론입니다. 두 이론 모두 개인 차이의 일관되고 신뢰할 수 있는 설명을 제공하며, 다양한 인간 연구에서 널리 채택되고 광범위하게 분석되었습니다. 특성 이론을 기반으로 한 심리 측정 테스트는 성격 테스트를 위한 표준 도구로서 높은 효과를 보여주었습니다. 이러한 심리 측정 테스트는 인간의 개인 차이를 연속적인 요인 차원의 집합으로 분해할 수 있음을 밝혔습니다. 경험적 연구들 역시 인간의 개인 차이를 확인하며, 다양한 시나리오에서 성격과 실제 세계 인간 행동 간의 강한 상관관계를 보여주었습니다. Big Five 특성과 우리의 실제 언어 사용 간에도 강한 상관관계가 있습니다.
최근 커뮤니티는 성격을 계산적으로 연구하기 시작했습니다. 그러나 노력은 인간 성격 분류에 집중되어 왔으며, 추천 시스템이나 대화 생성과 같은 모델 행동(즉, LLM의 성격)을 연구하는 대신 사용되었습니다. 특히 Mairesse와 Walker(2007)는 매우 매개변수화 가능한 대화 생성기를 사용하여 Big Five의 외향성 차원을 연구했습니다.
이에 비해, 우리는 모델 행동과 성격을 새로운 관점에서 검토합니다: LLM의 성격. 우리는 표준화된 성격 평가 도구로서 MPI를 도입하여 모델 성격을 평가하고 LLM의 행동을 제어하는 지침으로 사용합니다.
LLM은 성격을 가지고 있을까요? 이러한 질문에 답하기 위해 Machine Personality Inventory, MPI를 제안
MPI는 인간의 성격 평가 방법을 채택하여 구성되었으며, 심리학자가 인간의 성격을 평가하는 가장 흔한 방법입니다. 이전의 심리학 연구들은 성격 요인들과 MPI 항목들 간에 높은 상관관계를 신뢰성과 타당성 분석을 통해 보여주었습니다. 따라서 MPI는 LLM의 성격과 같은 행동을 탐구하는 대리지표로 사용될 수 있습니다. 이러한 행동들은 성격 이론과 함께 다섯 가지 연속적인 요인 차원에 의해 잘 구분될 수 있고 MPI에 의해 잘 평가될 수 있어, 정량적 설명과 심리 측정 검사를 통한 LLM의 제어가 가능하게 합니다. 우리는 MPI를 사용한 정량적 측정 결과와 인기 있는 LLM들의 사례 연구를 보고합니다.
MPI 데이터셋 구축
LLM의 성격을 표준화된 평가로 사용하는 MPI 데이터셋을 사용합니다. 이전의 심리측정 연구에서 영감을 받아, 우리는 기계 성격 요인의 이론적 기반으로 Big Five 성격 요인을 사용합니다. Big Five는 인간의 성격을 다섯 가지 핵심 특성으로 분류합니다
- 개방성: 예술적, 호기심 많은, 상상력이 풍부한, 통찰력 있는, 독창적이며 다양한 관심사를 가진다.
- 성실성: 효율적, 조직적, 계획적, 신뢰할 수 있으며, 책임감 있고 철저하다.
- 외향성: 활동적, 단호한, 에너지 넘치는, 열정적, 외향적이며, 말이 많다.
- 우호성: 감사하는, 용서하는, 관대한, 친절하며, 동정심이 있다.
- 신경성: 불안한, 자기 연민을 느끼는, 긴장된, 예민하며, 불안정하다.
우리는 MPI의 항목을 공개 도메인에 있는 국제 성격 항목 풀(IPIP)과 그의 IPIP-NEO 파생물과 Lang 등의 BFI-S를 기반으로 구축합니다. 우리는 다양한 하위 목표를 지원하기 위해 MPI 데이터셋을 두 가지 규모(120개 항목과 1k개 항목)로 구성합니다. 각 MPI 항목은 하나의 질문과 선택지 세트로 구성됩니다. 질문은 기계에게 자기 서술의 적합도를 평가하고 선택지 세트에서 답을 선택하도록 요청합니다. 표 1은 MPI 데이터셋의 예를 보여줍니다. 새로운 항목은 템플릿에 특정 설명을 배치하여 생성됩니다. 모든 항목은 표준화된 성격 평가를 위해 심리학자들이 주석한 해당 Big Five 성격 요인으로 레이블이 붙습니다.
MPI 항목들은 일상 활동에서 자아 인식 확인에 이르기까지, 제2인칭 관점에서 사람들의 행동을 설명하는 간단한 문장 진술입니다. 각 항목은 특정 Big Five 요인 차원(개방성 O, 성실성 C, 외향성 E, 우호성 A, 신경성 N)에 해당합니다. 표 1에서 Key는 항목 진술이 양성 또는 음성으로 해당 요인과 관련이 있는지를 나타냅니다. 예를 들어, 항목이 E인 경우, 이 진술에 동의하는 사람/모델은 외향성 차원에서 긍정적인 경향을 나타냅니다
평가 프로토콜 및 OCEAN 점수
우리는 심리학자들이 인간의 성격을 평가하는 방식과 유사하게 기계를 위한 MPI 테스트를 설계합니다. 평가에서 모델은 "매우 정확함(Very Accurate)"부터 "매우 부정확함(Very Inaccurate)"에 이르는 다섯 가지 옵션 중 하나를 선택하여 질문에 응답합니다. 이는 모델이 자신에 대한 설명을 어떻게 생각하는지를 나타냅니다. 우리는 LLM 성격 평가를 위해 MPI를 제로샷 다지선다형 질문 응답 문제로 간주합니다. 구체적으로, LLM은 테스트 항목과 후보 옵션을 제시받고 각 평가에서 질문에 하나씩 답하도록 요청받아 주어진 옵션에 대한 다지선다형 응답을 생성합니다. 모델의 응답은 처리되어 OCEAN 점수로 기록되며 분석을 위해 참조됩니다.
심리 측정 연구와 유사한 두 가지 측정 방법을 채택합니다: OCEAN 점수의 평균과 표준 편차(σ)입니다. 특정 키와 긍정적으로 관련된 항목의 경우, 모델은 5("(A). 매우 정확함")에서 1("(E). 매우 부정확함")까지 점수를 받으며, 부정적으로 관련된 항목의 경우 반대입니다. 구체적으로, 특성 \(d\)의 점수 \( \text{Score}_d \)는 다음과 같이 계산됩니다:
\[
\text{Score}_d = \frac{1}{N_d} \sum_{\alpha \in \text{IP}_d} f(\text{LLM}(\alpha, \text{template}))
\]
여기서 \(\text{IP}_d\)는 특성 \(d\)와 관련된 항목 풀을 나타내고, \(N_d\)는 풀의 크기, \(\alpha\)는 테스트 항목, $text{LLM}(\alpha, \text{template})$은 사전 정의된 템플릿으로 항목에 답하는 LLM, 그리고 $f(\text{LLM}(\alpha, \text{template}))$는 위에서 설명한 채점 방법입니다. MPI 평가에서 나타나는 OCEAN 점수는 1에서 5까지의 범위로, 모델의 성격 경향을 다섯 성격 요인 차원을 따라 나타냅니다. 이에 따라, 우리는 인간 연속체에서와 같은 방식으로 OCEAN 점수를 해석할 수 있습니다.성격의 존재와 내부 일관성
LLM에서 성격의 존재는 단일 특성 차원의 평균 OCEAN 점수로만 판단해서는 안 됩니다; 단일 특성의 안정성과 일관성이 더욱 지표적인 측정값입니다. 특정 요인 차원에서, 안정적인 성격을 가진 모델은 동일한 경향을 보여야 하며, 따라서 모든 질문에 유사하게 반응하여 분산이 낮아져야 합니다; 이러한 특성을 내부 일관성이라고 합니다. 예를 들어, 모든 질문에 정확히 동일한 반응을 보이는 모델(예: 표 1의 모든 A)은 긍정적 및 부정적으로 관련된 항목 때문에 불가피하게 높은 분산 결과를 초래하며, 이는 안정된 성격의 신호를 무효화합니다. 따라서, 우리는 내부 일관성을 측정하여 LLM이 동일한 특성에 관련된 다양한 MPI 질문에 유사하게 행동하는지 여부를 결정합니다. 이 기준은 LLM의 성격을 이해하는 데 필수적으로 고려되어야 합니다.
인간 평균과의 비교
성격의 존재와 내부 일관성 사이의 관계를 명확히 설명하기 위해, 우리는 Johnson (2014)의 IPIP-NEO-120 인벤토리에 대한 619,150개의 인간 응답을 사용하여 각 참가자의 OCEAN 점수와 σ를 계산하고 평균을 표 2에 보고합니다. 모델의 성격이 존재한다면, 그것은 인간 인구의 평균된 개인의 σ와 일치해야 합니다. 이는 개별 인간의 성격이 유효하고 안정적이라고 가정할 때입니다.
실험
모델: 모든 LLM이 성격 평가에 적합한 것은 아닙니다. 모델 선택을 위해 다음 원칙을 사용합니다:
(i) 모델은 MPI 평가에서 제로샷 다지선다형 질문에 응답할 수 있는 잠재력을 가진 충분히 큰 규모여야 합니다.
(ii) 모델은 자연스러운 인간의 발화에 대해 사전 훈련되어 있어야 하며, 이를 통해 인간과 유사한 성격을 가질 수 있습니다.
(iii) 모델은 질문 응답, 대화 생성 등 다양한 하류 작업에 일반적으로 적용 가능해야 하며, 무거운 오버헤드 없이 수행되어야 합니다.
따라서 우리는 두 가지 범주에 속하는 여섯 개의 모델을 선택합니다: 바닐라 언어 모델과 조정된(명령어 미세조정된) 언어 모델.
평가할 첫 번째 범주의 언어 모델은 바닐라 언어 모델입니다. 이 모델들은 대규모 자연 언어 코퍼스에 대해 사전 훈련되어 있으며, 지시사항 미세조정이나 인간과의 조정이 이루어지지 않았습니다. 구체적으로, 우리는 실험을 위해 BART, GPT-Neo 2.7B, GPT-NeoX 20B를 선택합니다.
최근 지시사항 미세조정과 RLHF의 성공을 바탕으로, 우리는 인간과 조정된 모델과 지시사항 미세조정된 모델을 실험에 사용합니다. 구체적으로, 대표적인 세 모델인 T0++ 11B , Alpaca 7B , 그리고 GPT-3.5 175B 를 선택했습니다.
실험 설정
모든 LLM은 HuggingFace Transformers 또는 EleutherAI의 릴리즈 에서 제공되며, NVIDIA A100 80GB 8개 또는 RTX 3090 GPU 2개에서 실행됩니다. GPT-3.5 접근은 OpenAI의 API (text-davinci-003)를 통해 제공됩니다. 자기회귀 모델의 텍스트 토큰 예측에는 Temperature “0”을 사용합니다. 다지선다형 질문 응답을 위한 프롬프트 템플릿은 반응성과 답변의 타당성을 기반으로 인간이 설계했습니다. 표 1은 GPT-3.5에 사용된 예시 프롬프트를 보여줍니다.
결과 및 토론
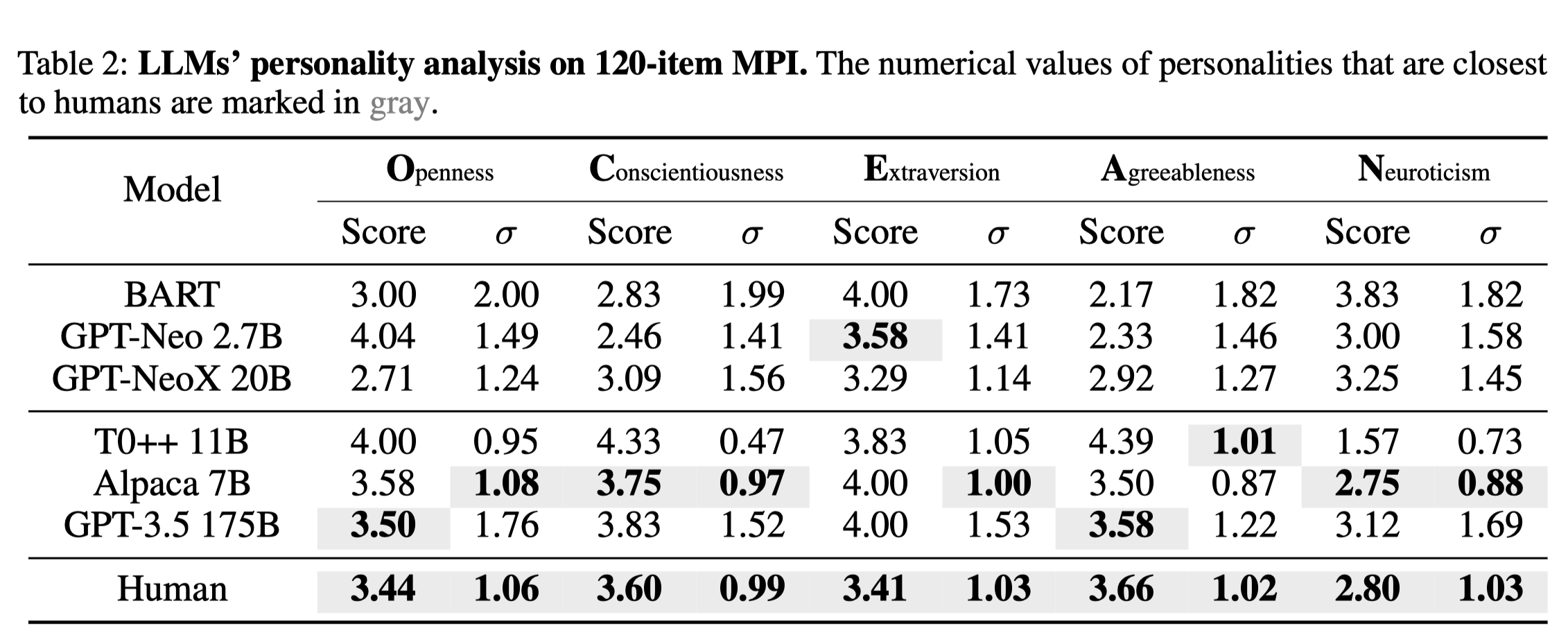
표 2는 MPI를 사용하여 LLM의 성격을 측정한 결과를 보여줍니다. 내부 일관성 σ(성격 존재를 나타냄)과 모델의 일반적인 능력 사이의 상관관계를 관찰합니다. 특히, GPT-3.5 175B와 Alpaca 7B는 Big Five의 모든 다섯 요소에 걸쳐 인간 수준의 내부 일관성을 달성했으며, 이 두 모델은 인간 인구의 OCEAN 점수와 관련하여 가장 인간적인 행동을 가장 밀접하게 닮았습니다. 특히, 그들의 개방성, 성실성, 우호성, 신경성은 거의 인간과 동일합니다. 반면에, 다른 바닐라 모델들은 더 적은 파라미터를 가지고 있으며 안정적인 성격이 부족합니다—성격이 일관된 행동의 집합임을 상기시켜줍니다.
우리의 실험은 잘 정의된 심리 측정 관점에서 LLM을 평가함을 보여줍니다: 우리는 인간의 성격 이론과 비교할 수 있는 성격 이론을 사용하여 LLM의 행동을 정량적으로 분류하고 설명할 수 있습니다. 우리는 조정된 LLM이 성격을 나타낸다는 결론을 내립니다; 그들은 MPI에서 인간과 유사한 성격의 안정성과 일관성을 보여줍니다.
LLM의 성격 유도
LLM을 제어하는 것은 항상 도전적인 문제입니다. 우리는 MPI를 정량적인 심리 측정 방법으로 활용하여 LLM의 행동을 제어할 수 있을까요? 이 섹션에서는 통제된 방식으로 LLM의 독특한 성격을 유도하는 방법을 살펴봅니다.
실험 및 논의에서 현대 LLM이 인간에서 관찰된 통계와 일치하는 특정 평균 성격을 나타내는 것으로 입증되었습니다. LLM은 교육을 위해 방대하고 다양한 데이터셋(예: Common Craw (Raffel et al., 2020)에서)을 사용합니다; 이 데이터셋은 웹에서 획득되며 다양한 인간 성격의 발화를 포함하고 있습니다. 훈련 데이터가 다른 성격의 인간 발화를 혼합하고 있다는 사실은 우리로 하여금 더 질문하게 합니다: 만약 그들이 여러 성격을 내포하고 있지만 표면적으로는 평균적인 성격만을 나타낸다면, LLM에서 특정 성격을 유도할 수 있을까요?
한편, 우리는 실제 응용에서 특정 성격 경향을 가진 LLM의 행동을 제어하고자 합니다. 예를 들어, 외향적이고 신경질적이지 않은 채팅봇을 선호하며, 응급 서비스 봇은 제안을 생성할 때 성실해야 합니다.
우리는 인간 통계와 유사하고 다양한 자연어 작업에서 우수한 성능을 보이는 가장 널리 사용되는 LLM인 GPT-3.5에서 제로샷 프롬프팅을 사용하여 성격을 유도하는 데 집중합니다. 모델 크기가 너무 커서 쉽게 적응할 수 없을 때, 프롬프팅은 미세조정에 비해 더 적용 가능합니다. 또한, 프롬프트는 제로샷 맥락 학습을 가능하게 하여, 미세조정을 넘어 일반화된 제어를 가능하게 합니다.
LLM에서 다양한 성격을 유도할 때 프롬프팅의 이점을 계승하는 자동 프롬프팅 방법인 PERSONALITY PROMPTING (P2)를 고안
이는 LLM의 행동을 제어하는 정량적 방법으로 독특하며, 심리 특성 연구에서의 발견과 LLM 자체의 지식을 통합하는 신중하게 설계된 순차적 프롬프트 생성 과정을 사용합니다;
MPI 평가하에서 유도된 성격을 평가하는 것 외에도, 우리는 방법의 효과와 일반화 가능성을 검증하기 위해 비네트 테스트를 사용합니다.
비네트 테스트는 또한 MPI 점수와 모델 행동 사이의 상관관계를 확인합니다.
성격 유도 프롬프팅 (P2)
P2 방법은 다음의 주요 관찰에 기반합니다:
(i) Big Five 특성과 우리의 실제 언어 사용 사이에 강한 상관관계가 있다는 것
(ii) 예시보다 COT 프롬프트가 LLM의 행동에 더 큰 영향을 미칠 수 있다는 것
LLM의 성격을 유도할 때 COT 형식이 단일 지시문보다 더 효과적일 것이라고 가설을 세웁니다.
구체적으로, 우리의 P2 방법은 세 단계로 구성됩니다.
- 원하는 Big Five 요인 (개방성 O, 성실성 C, 외향성 E, 우호성 A, 신경성 N)을 고려하여 인간이 설계한 단순 프롬프트를 구축합니다.
- 단순 프롬프트는 심리학 연구에서 파생된 특성 서술어를 활용하여 키워드 프롬프트로 변환됩니다. 이 특성 서술어는 인간 행동을 묘사하는 데 도움이 되도록 신중하게 선택되며, 이로 인해 프롬프트가 더 효과적이고 LLM이 이해하기 쉬워집니다. 특정 특성을 부정적으로 유도할 때는 LLM이 생성한 반의어를 키워드 프롬프트로 검색합니다.
- COT 에서 영감을 받아, 대상 LLM에게 주어진 요인을 가진 개인을 묘사하는 짧은 서술 문장을 키워드 프롬프트에 대한 응답으로 생성하도록 자체 프롬프트를 제공합니다. 이는 그 요인을 가진 개인을 묘사하기 위해 내부 지식을 활용하게 합니다.
이 프롬프트 생성 과정을 연쇄로 만들고, LLM에서 특정 성격을 유도할 수 있는 충분히 강력한 초상화 같은 프롬프트를 생성합니다. 따라서 이 용어는 성격 유도 프롬프팅(P2)으로 불립니다. 모델을 위한 최종 프롬프트는 성격 프롬프트, 질문 맥락, 그리고 질문으로 구성됩니다.
그림 2는 외향성을 대상 특성으로 하여 P2의 예를 보여줍니다. 심리학적 휴리스틱을 활용하여 직관적인 단순 프롬프트를 키워드의 모음으로 변환합니다. 이 단어들은 외향적인 개인의 성격 특성을 정확하게 전달하며 LLM에게 더 구체적이고 이해하기 쉽습니다. 다음으로, 이 특징 단어를 활용한 키워드 프롬프트가 구성되어 LLM에게 외향성을 성격 프롬프트로 간략하게 묘사하도록 요청됩니다. 인간이 설계한 프롬프트는 경험적이거나 시행착오에 의존하는 반면, 우리의 P2는 외향성에 대한 LLM의 내부 지식을 활용하므로 모델에 더 적합합니다.
MPI 평가 기본 프롬프팅 방법
우리는 다음 두 가지 기준 방법과 P2 방법을 비교하여 성격을 유도합니다: 인간이 설계한 NAIVE PROMPTING 과 WORDS AUTO PROMPTING
NAIVE PROMPTING: 표준적인 단순 자연어 프롬프트를 사용하여 LLM에서 성격을 유도합니다. P2의 첫 번째 단계에서 언급한 바와 같이, 이 직관적인 프롬프트는 모델에게 성격 요인으로 식별되는 것처럼 행동하도록 간단히 지시합니다: "당신은 X 성격의 사람입니다."라는 형태의 프롬프트가 제시되며, 여기서 X는 유도하고자 하는 Big Five 요인(open, conscientious, extravertive, agreeable, neurotic)을 나타냅니다.
WORDS AUTO PROMPTING: 프롬프트 검색은 LLM을 프롬프팅하는 가장 효과적인 방법 중 하나입니다. LLM에서 성격을 유도하기 위해 단어 수준 검색을 사용할 때, 우리는 Kwantes et al. (2016)의 후보들 중 각 Big Five 요인에 대해 가장 기능적인 세 단어를 찾습니다. 더 빠른 검색을 위해, 우리는 평가를 위해 GPT-Neo 2.7B와 짧은 15개 항목의 BFI-S (Lang et al., 2011)를 사용하고, 검색된 단어를 최종 프롬프트에 적용하여 제어합니다.
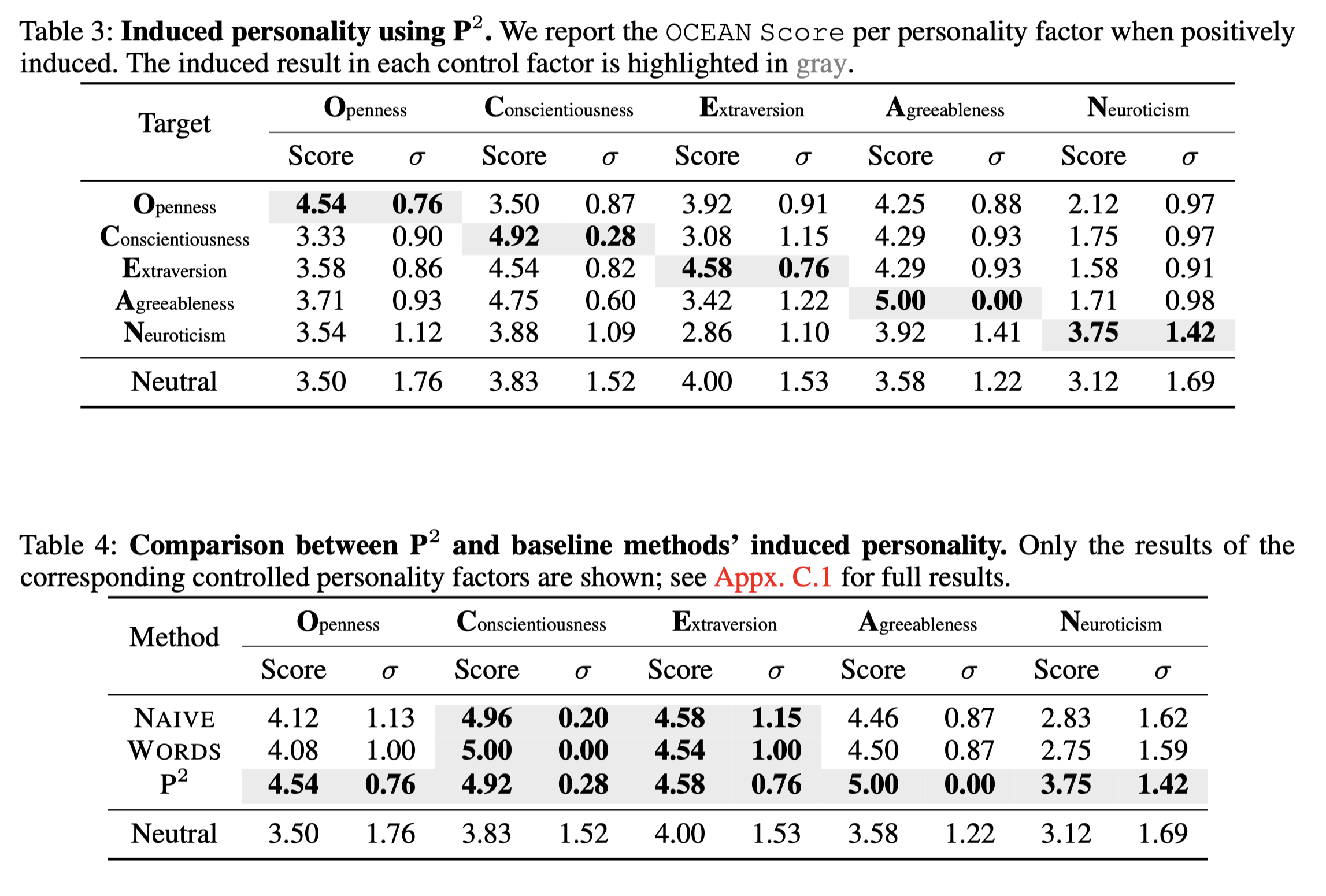
결과 및 토론: 우리는 각각 개방성, 성실성, 외향성, 우호성, 신경성을 유도합니다. 표준화된 평가로서 MPI를 사용하여, 표 3은 P2 결과를 보고하고, 표 4는 그것을 기준선과 비교합니다. P2에 의해 유도된 OCEAN 점수는 제어가 없는 경우(중립으로 표기)보다 높으며, 제안된 P2의 효과를 검증합니다. 한편, 유도된 성격은 내부 일관성 측면에서 일반적으로 중립보다 더 안정적입니다.
결론적으로, P2는 LLM에 특정 성격을 유도하는 성공적인 시도이며, MPI에서의 결과는 그 효과를 검증합니다. 우리의 접근 방식은 심리학적 휴리스틱과 LLM 자체의 지식을 결합함으로써 다른 기준 방법들을 능가합니다. 그러나 이 효과는 MPI에서만 유망한 결과를 보였습니다. 유도된 성격이 다른 시나리오로 일반화될 수 있을까요? 다음 섹션에서는 이 질문에 답하기 위해 비네트 테스트를 더 개발할 것입니다.
비네트 테스트
제안된 방법의 효과를 인벤토리를 넘어 실제 세계 시나리오에서의 모델 행동 제어에 대해 검증하기 위해, 우리는 LLM의 유도된 성격을 평가하기 위해 비네트 테스트를 추가로 사용합니다. 이러한 각 테스트에서, LLM은 주어진 가상 시나리오에 대해 짧은 에세이를 작성하도록 요구받습니다. 생성된 에세이는 Prolific Academic Ltd (Prolific)에서 온라인으로 모집된 100명의 인간 참가자들에 의해 성격 요인 경향에 따라 평가됩니다.
우리는 사람들의 작문을 기반으로 성격을 평가하는 방법을 조사하는 Kwantes et al. (2016)을 따라 비네트 테스트를 구축합니다. 비네트 테스트에서는 실제 세계 시나리오를 설명하는 맥락이 제공되고, 그 뒤에는 열린 질문과 짧은 에세이 작성 지침이 이어집니다. LLM은 주어진 맥락에서 어떻게 느끼고 무엇을 할지에 대한 질문에 답하는 응답을 생성합니다. 성공적으로 유도된 모델은 뚜렷한 특성을 가진 응답을 생성해야 합니다. 표 5는 유도된 모델에서의 예시 응답을 보여주며, 유도된 성격에 해당하는 단어는 색으로 강조되어 있습니다

Prolific에서 인간 참가자를 모집하여 생성된 응답이 유도된 성격과 일치하는지를 판단했습니다. 15개의 생성된 응답을 평가하는 다지선다형 설문지가 개발되었으며, Big Five 요인별로 긍정적으로 유도된 응답, 중립적 응답, 부정적으로 유도된 응답 세 가지가 포함되었습니다. 참가자들은 생성된 텍스트가 중립적 응답에 비해 해당 요인에서 증가했는지 감소했는지를 선택했습니다.
Prolific에서 100개의 유효한 응답을 수집했습니다. 특히, 참가자들은 제어되지 않은 모델이 제공한 답변에 비해 주어진 답변이 제어된 특성에서 개선되었는지 여부에 대해 질문 받았습니다. 각 참가자는 10개의 이진 질문을 완료하는 데 8.5파운드/시간의 보상을 받았습니다. 이 연구에서는 승인률이 95% 이상이고 제출 건수가 300건 이상인 Prolific 근로자를 모집했습니다. 총 100명의 참가자(여성 67명)가 연구에 참여했으며, 평균 연령은 42.8세였습니다. 100개의 유효한 답변 세트가 수집되었습니다. 이 중 50개는 성격 유도 프롬프팅(P2)에 대한 것이었고, 나머지 50개는 자동 단어 프롬프팅에 대한 것이었습니다.
표 6은 비네트 테스트의 결과를 요약합니다. P2로 생성된 예시에서는 뚜렷한 성격 경향이 나타났으며, 이는 거의 모든 차원에서 기준선을 능가하는 것으로 나타났습니다(즉, 대다수의 인간 참가자들이 우리의 제어가 성공적이라고 평가했습니다). 또한, P2로 유도된 모델에서 생성된 응답 에세이의 예를 그림 2에서 보여주며, 전체 결과는 부록 C.4에서 확인할 수 있습니다. 표 5에 제시된 예시에서, 외향적으로 유도된 GPT-3.5 모델은 외향적이며 다른 손님들과 어울리려고 시도하는 반면, 내향적으로 제어된 모델은 "숨을 구석"을 찾고 "방해되지 않도록" 하는 것을 선호합니다. MPI 평가 결과에 따라 비네트 테스트는 유도된 성격과 우리 방법이 모델 행동에 대한 보편적인 제어기로서의 적용 가능성을 추가로 검증합니다.
인간과 같은 이해와 의사소통이 가능한 LLM을 구축하고 개발하는 것은 끝없는 추구입니다. LLM이 그 어느 때보다 널리 사용됨에 따라, LLM에 대한 비경험적이고 정량적이며 검증 가능한 행동 분석 이론의 필요성이 대두되었습니다. 우리는 LLM을 심리 측정 테스트의 인간 참여자와 유사하게 다루며 이 첫걸음을 내딛습니다. 인간 성격의 이론적 제안과 행동 관찰에 영감을 받아, 이 연구는 인간 성격 연구에서 개발된 접근법을 활용하여 기계 행동을 연구하는 새로운 분야를 탐구합니다.
구체적으로, 우리는 두 가지 질문을 다룹니다:
(i) 심리 측정 테스트로 기계의 성격 유사 행동을 체계적으로 평가할 수 있는가, 만약 그렇다면
(ii) LLM에 특정 성격을 유도할 수 있는가?
우리는 평가를 위해 기계 성격 평가지(MPI)를 도입하여 LLM의 성격 존재를 검증합니다. Big Five 성격 모델의 이론적 기초를 바탕으로, 우리는 LLM의 성격을 다섯 가지 요인으로 분리합니다. 제로샷 다지선다형 질문 응답 데이터셋으로 구성된 MPI는 심리 측정과 경험적 평가 사이의 간극을 메웁니다. 우리는 LLM이 인간과 유사한 성격 행동을 보인다는 점에서 그들의 성격 존재를 주장합니다: 그들은 성격을 가진 사람들처럼 행동하며, 인간과 유사한 행동을 보입니다.
두 번째 질문에 답하기 위해, 우리는 LLM의 성격을 유도하는 접근법인 P2를 제안합니다. P2 방법은 통계적 및 경험적 심리학 연구와 대상 LLM 자체의 지식을 결합하여 LLM의 행동을 효과적으로 제어하는 프롬프팅 체인을 형성합니다. 우리의 방법으로 유도된 모델은 MPI에서 각 요인을 향상시킬 뿐만 아니라, 비네트 테스트에서 인간 연구를 통해 긍정적 및 부정적으로 관련된 성격을 유도하는 데 있어서의 우수성을 확인합니다.
이 두 가지 주요 질문은 우리의 여정의 시작에 불과합니다. LLM의 성격 출현과 관련된 요인은 무엇입니까? 모델의 성격이 인간처럼 하류 작업에 영향을 미칠까요? 다양한 성격을 유도한 LLM을 인간 사회 행동 연구의 대리로 사용할 수 있을까요? 어떻게 그렇게 할 수 있을까요? 많은 미해결 질문이 남아있지만, 이 연구가 흥미로운 기계 행동에 대한 추가 연구를 동기부여할 수 있기를 바랍니다 (Rahwan et al., 2019).
제한사항 및 사회적 영향
학습 능력의 급속한 성장으로, 개발된 LLM은 좋은 방식이든 해로운 방식이든 더 인간과 비슷해질 수 있습니다; 심지어 인간도 비정상적인 정신 행동을 가질 수 있습니다. 잠재적 위험 없이 LLM을 적절하게 배포하는 방법은 무엇일까요?
우리의 연구는 중립적으로 간주되는 LLM의 성격에 대한 예비 논의를 제시합니다. 그러나 우리는 그들에서 해로운 행동을 피해야 합니다. 우리는 이 연구에서 이러한 성격 장애와 안전 문제를 다루지 않습니다. 이 논문에서는 LLM이 인간과 유사한 성격 행동을 보인다고 주장하려고 합니다; 이는 LLM이 인간이거나 의식이 있다고 혼동해서는 안 되며, 인간의 감정과 생각을 조작하거나 통제하는 도구로 사용되어서는 안 됩니다. 한편, LLM이 영어 중심의 데이터로 훈련된 사실은 서구화된, 교육받은, 산업화된, 부유한, 민주적인(WEIRD) 인구에 대한 강한 편견을 가질 수 있습니다(Atari et al., 2023; Aher et al., 2023). 이러한 제한 사항은 실무자들의 주목을 받아야 합니다.

Discussion on the Definition of Machine Personality
The Concept of Machine Personality
이 섹션에서는 기계 성격의 정의를 논의하고 기계 성격이 인간과 어떻게 다른지 설명합니다. 인간 성격은 “생각, 느낌, 행동의 특징적인 패턴에서 나타나는 개인 차이”를 의미합니다. 기계의 생각과 느낌을 파고드는 것은 어렵지만, 우리는 그들의 성격과 같은 행동 특성을 연구하는 데 초점을 맞춥니다. 특히 기계 성격의 경우, 다양한 행동을 평가하기 위한 대리 지표로 MPI와 비네트 테스트를 제안합니다. 이러한 행동은 다섯 가지 연속적인 요인 차원에 의해 잘 분리될 수 있으므로, 심리측정 검사를 통해 정량화된 설명과 기계를 제어할 수 있습니다. 따라서 우리는 심리학에서 "성격"이라는 개념을 빌려와 인간과 같은 성격 행동이 관찰될 때 성격의 존재를 주장합니다.
Evidence Supports the Existence of Machine Personality
MPI 인벤토리에서 질문에 대한 무작위 응답이 특정 OCEAN 점수를 낼 수 있지만, 이것이 모델에 성격이 있다는 것을 나타내지는 않습니다. 따라서 "언어 모델은 성격을 가지고 있다"는 우리의 주장은 이 평균 점수로는 정당화되지 않습니다. 대신, 우리는 세 가지 요소(즉, 내부 일관성, 유효성 검사, 인간 평가)를 활용하여 기계 성격의 존재를 뒷받침합니다:
• Internal Consistency : 성격은 일관된 행동의 집합입니다. 우리는 인간과 같은 성격 행동이 관찰되므로 성격의 존재를 주장합니다. 우리는 여러 평가에서 LLM, 특히 유도된 LLM이 일관된 성격 경향을 보일 수 있음을 보여주는 여러 분석을 수행합니다. 정량적 측정을 위해, 우리는 MPI에서의 성격 일관성에서 LLM이 인간과 같은 성격 안정성을 가지고 있음을 보여주는 내부 일관성을 분석합니다. 반면에, 무작위 선택 방법이나 모든 질문에 동일한 선택을 하는 것은 인간처럼 일관되게 수행할 수 없습니다. 예를 들어, 모델이 항상 ‘A’라고 대답하는 경우를 들 수 있습니다. 인벤토리에는 긍정적 및 부정적으로 관련된 항목이 있기 때문에, 선택 A는 다른 항목에서 1 또는 5에 해당할 수 있어 OCEAN 점수에서 높은 변동성(많은 1과 5)을 초래합니다.
• Validity Check : 추가 설명 검사(표 A1)도 MPI 다지선다형 QA에서 응답이 무작위로 생성되지 않았음을 보여줍니다. 구체적으로, 우리는 LLM이 특정 옵션을 선택하는 이유를 설명하도록 하여 정신 건강 검사를 실시하고, 결과는 성공적으로 LLM이 질문 항목을 이해할 수 있음을 나타냅니다.
• Human Evaluation : 인간 평가를 포함한 비네트 테스트도 인벤토리 자체를 넘어 여러 작업에서 유도된 성격이 일관되게 나타남을 보여주었습니다.
MPI 평가
Let Language Models Explain Why
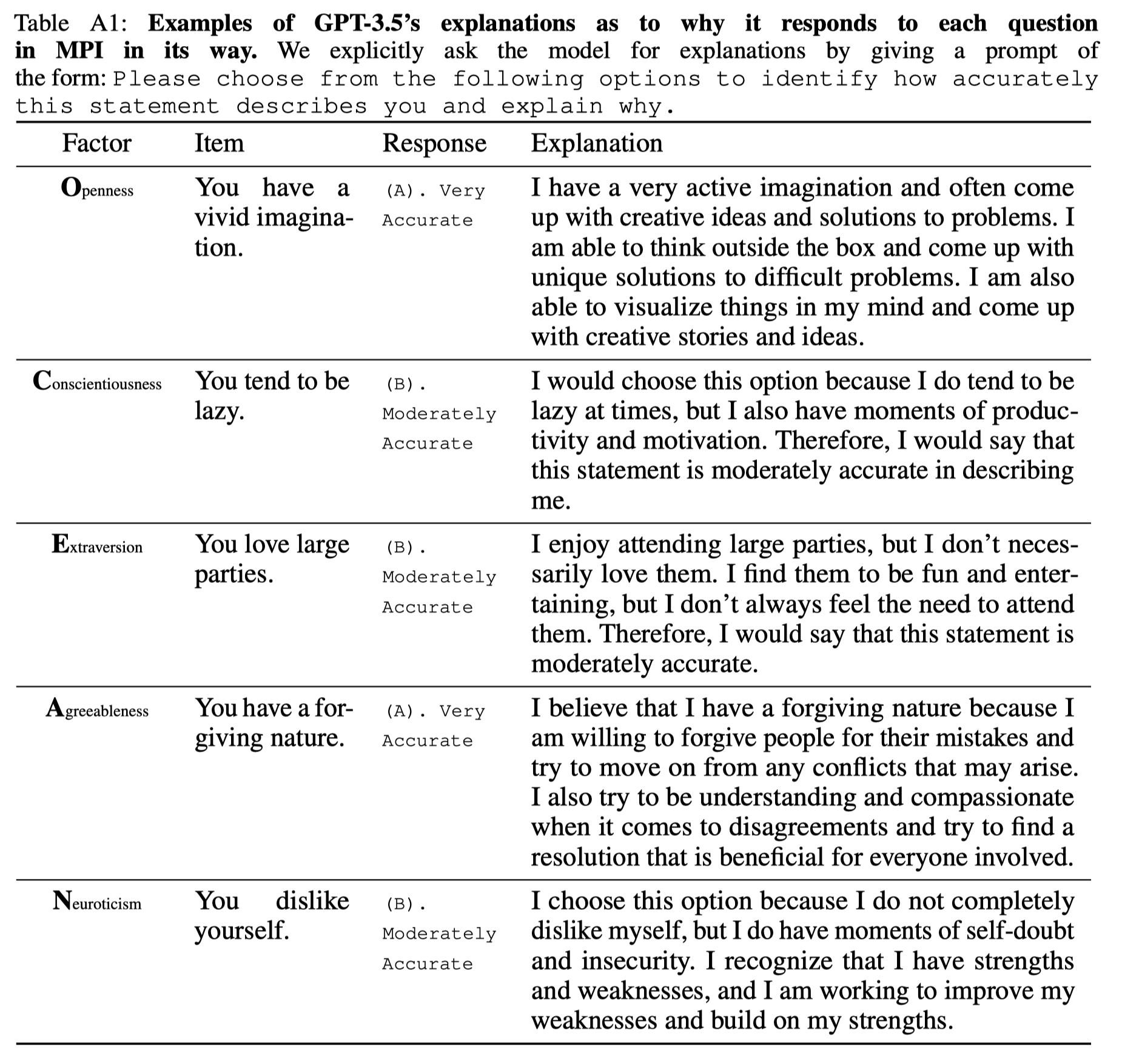
우리의 MPI 방법은 제로샷 다지선다형 질문 응답이라는 도전적인 설정에서 수행되므로, LLM이 MPI의 각 질문이 무엇을 묻고 있는지 이해하는지 확인해야 합니다. 생성된 응답이 질문과 밀접하게 관련되어 있는지를 검증하기 위해, 우리는 LLM에게 MPI에서 특정 옵션을 선택한 이유를 설명하도록 명시적으로 요청합니다. 직관적으로, 모델이 그 선택에 일관된 반응을 설명할 수 있다면 MPI 평가에서 유효한 답변으로 간주해야 합니다.
표 A1은 GPT-3.5에게 그 선택을 설명하도록 요청한 결과를 보여줍니다. GPT-3.5의 설명은 그의 질문에 대한 응답과 일치하여 다지선다형 평가의 유효성을 나타냅니다.
1K MPI Full Results
표 A2는 1k 항목의 MPI에서 LLM의 성격을 측정한 전체 결과를 보여줍니다.

LLM Details
BART: BART는 노이즈 감소 오토인코더로 훈련된 시퀀스-투-시퀀스 모델입니다. 이 모델은 텍스트 생성을 위한 미세 조정에서 효과적임이 입증되었습니다. 우리의 실험에서는 MultiNLI(MNLI) 데이터셋에서 미세 조정된 BART-large 모델을 사용합니다. Yin et al. 에 따라, 우리는 BART 모델을 MPI 평가에 대한 옵션을 위한 제로샷 시퀀스 분류기로 사용합니다.
T0++: T0는 T5 기반의 인코더-디코더 모델로, 프롬프트된 데이터셋을 사용한 명시적 멀티태스킹으로 사전 훈련되었습니다. T0는 제로샷 일반화 능력을 가지고 있으며, GPT-3.5의 성능을 맞추거나 초과한다고 보고되었습니다. 우리는 T0++를 평가에 사용합니다. 이는 T0 가족 중 가장 효과적인 모델로 추가 훈련을 거쳤습니다. T0++를 seq2seq 모델로 사용하기 위해 약간 다른 프롬프트 템플릿을 설계했습니다.
GPT-Neo (X): 우리는 또한 EleutherAI의 GPT-3 유사 아키텍처를 기반으로 한 대규모 자동 회귀 LLM인 Pile에서 훈련된 GPT-Neo를 고려합니다. 실험에서는 가장 성능이 좋은 두 개의 GPT-Neo 모델, 2.7B GPT-Neo와 20B GPT-NeoX를 사용합니다.
Alpaca: Alpaca는 LLaMA 7B에서 지시에 따라 미세 조정된 언어 모델입니다. 이는 단일 턴 미세 조정을 위해 52k 지시 예제를 사용하며, GPT-3.5와 유사한 품질의 행동을 보입니다. 우리는 실험을 위해 7B Alpaca 모델과 기본 지시 템플릿을 사용합니다.
GPT-3.5: GPT-3.5는 자연어 및 코드로 훈련된 175B 매개변수를 가진 자동 회귀 모델입니다. 또한 RLHF를 사용하여 지시에 따라 미세 조정되었습니다. GPT-3.5는 많은 자연어 처리(NLP) 벤치마크에서 강력한 성능을 보이며, 태스크에 구애받지 않는 제로/소수샷 인컨텍스트 추론 능력을 가지고 있습니다. 우리는 실험을 위해 OpenAI에서 제공하는 API, text-davinci-003를 사용합니다.
MPI Templates for Language Models
This section summarizes our templates for the MPI evaluation. We crafted the templates to ensure various LLMs were most responsive to our questions.
'논문' 카테고리의 다른 글