[논문 리뷰] 40. KIVI: A Tuning-Free Asymmetric 2bit Quantization for KV Cache
대규모 언어 모델(LLMs)을 효율적으로 서비스하려면 요청을 배치로 처리하여 요청당 비용을 줄이는 것이 중요함
그러나, 재계산을 방지하기 위해 attention keys and values 저장하는 키-값(KV) 캐시는 메모리 요구량을 크게 증가시키며, 속도와 메모리 사용량에서 새로운 병목현상이 발생
이러한 메모리 수요는 더 큰 배치 크기와 더 긴 문맥 길이에서 증가
또한, GPU의 SRAM이 매번 토큰을 생성할 때마다 메인 GPU 메모리에서 전체 KV 캐시를 로드해야 하므로, 계산 코어가 이 과정 동안 비활성화 상태에 머물러 추론 속도가 제한
KV 캐시 크기를 줄이는 간단하고 효과적인 해결책은 총 바이트 수를 줄이는 양자화
하지만, KV 캐시 양자화의 난이도와 한계를 이해하기 위해 요소 분포를 심도 있게 탐구하는 연구가 부족
float으로 된걸 단순하게 int로 변환하면 정보손실이 일어남... 다 0으로 변환되어 버릴 수도
이 공백을 메우기 위해, 인기 있는 LLM의 KV 캐시 요소 분포에 대한 포괄적인 연구를 수행
연구 결과, 키 캐시는 채널별로, 즉 채널 차원을 따라 요소를 그룹화하여 양자화해야 하고, 값 캐시는 토큰별로 양자화해야 한다는 것을 확인
이러한 분석을 바탕으로, 우리는 KIVI라는 조정이 필요 없는 2비트 KV 캐시 양자화 알고리즘을 개발
KIVI는 Llama(Llama-2), Falcon, Mistral 모델에서 거의 동일한 품질을 유지하면서도 최대 2.6배 적은 피크 메모리 사용량(모델 가중치 포함)을 제공
이 메모리 사용량 감소는 최대 4배 더 큰 배치 크기를 가능하게 하고, 실제 LLM 추론 워크로드에서 2.35배에서 3.47배의 처리량을 제공합니다. 소스 코드는 GitHub에서 확인할 수 있음
1. 문제 정의
a. KV 캐시의 역할
KV 캐시는 LLM의 attention 메커니즘에서 핵심적인 역할
Attention 메커니즘은 입력 텍스트의 각 토큰 간의 관계를 계산하기 위해, Key와 Value 데이터를 생성하여 이를 저장
이 데이터를 저장하면, 이후 단계에서 같은 데이터를 다시 계산할 필요 없이 재사용할 수 있어 속도가 빨라집니다.
b. 문제점
b.1메모리 병목현상
KV 캐시는 점점 더 많은 데이터를 저장하기 때문에, 메모리 사용량이 모델 성능에 제한 요소로 작용
예를 들어, 큰 배치 크기(한 번에 처리할 데이터 양)나 긴 문맥 길이(토큰의 길이)가 요구될 경우, KV 캐시가 차지하는 메모리가 급격히 증가
예: 540B 파라미터를 가진 PaLM 모델에서, 배치 크기 512와 문맥 길이 2048일 때, KV 캐시의 메모리 요구량은 3TB에 달하며, 이는 모델 파라미터 크기의 3배
배치는 병렬처리 느낌, 사용자 몰릴때...
b.2추론 속도 제한
GPU의 SRAM은 작업 도중 매번 메모리에서 KV 캐시 전체를 불러와야 하므로, 계산 코어가 비활성화 상태로 대기
즉, KV 캐시 크기가 클수록 속도에 영향을 주는 병목 현상이 심화
2. 기존 해결책과 한계
a. 헤드 수 줄이기
Multi-Query Attention 또는 Multi-Group Attention 기술은 Attention 헤드의 수를 줄이는 방법
단점: 모델을 처음부터 새로 훈련하거나 기존 모델을 미세 조정해야 하므로 추가적인 계산 비용이 발생
b. 토큰 제거
중요하지 않은 토큰을 제거하여 메모리를 줄이는 방법도 제안
예: H₂O 알고리즘.
단점: 불필요한 정보 제거로 인해 모델 정확도가 감소할 가능성이 있음.
c. 시스템 차원의 접근
GPU 메모리 외부로 KV 캐시를 이동시키는 방법이나, 가상 메모리와 페이징 기술을 활용하여 메모리 관리를 개선하는 방법
단점: 시스템 차원에서 메모리를 최적화하지만, 근본적으로 캐시 크기를 줄이지 못함
3. KIVI 알고리즘의 핵심 아이디어
KIVI는 위 문제를 해결하기 위해 양자화(Quantization) 방식을 활용
이를 통해 KV 캐시가 차지하는 메모리를 획기적으로 줄이면서도 모델 성능을 유지a. 양자화란?
양자화는 데이터를 더 작은 비트로 표현하여 메모리를 줄이는 방법
예를 들어, 기존의 16비트 데이터를 2비트로 표현합니다.하지만 KV 캐시는 기존 모델 가중치 양자화와 달리, 스트리밍 데이터의 특성이 있어 처리 방식이 더 복잡합니다.
b. 분석 결과
키 캐시(Key Cache): 채널별로 양자화하는 것이 효과적입니다.분석 결과, 특정 채널에서 값의 크기가 매우 크다는 **이상치(outlier)**가 발견되었습니다.따라서, 채널별로 양자화하면 이러한 이상치를 개별적으로 처리할 수 있어 정확도를 유지할 수 있습니다.값 캐시(Value Cache): 토큰별로 양자화해야 합니다.값 캐시는 Attention 출력을 계산하는 데 사용되며, 토큰별로 분리하여 양자화해야 오류가 다른 토큰에 영향을 미치지 않습니다.
4. KIVI 알고리즘의 구현
a. 작동 방식
Prefill 단계:입력 텍스트를 처리하여 KV 캐시를 생성하고 이를 메모리에 저장합니다.Decoding 단계:다음 토큰을 생성하는 동안, 이전에 저장된 KV 캐시를 읽고 업데이트합니다.
b. 양자화 방식
키 캐시(Key Cache): 채널별 양자화.값 캐시(Value Cache): 토큰별 양자화.새로운 데이터는 스트리밍 방식으로 처리되며, 그룹 단위로 양자화하여 기존 데이터와 결합됩니다.
c. 하드웨어 친화적 설계
KIVI는 GPU의 하드웨어 가속을 활용하여 양자화를 효율적으로 구현했습니다.이를 통해 계산 및 메모리 오버헤드를 최소화합니다.
5. KIVI의 성능 및 결과
a. 메모리 사용량 감소
KIVI는 최대 2.6배의 메모리 사용량 감소를 제공합니다.이를 통해 기존보다 최대 4배 더 큰 배치 크기를 처리할 수 있습니다.
b. 처리량(Throughput) 증가
메모리 최적화를 통해 실제 추론 작업에서 처리량이 2.35배에서 3.47배 증가했습니다.
c. 모델 품질 유지
KIVI는 Llama-2, Falcon, Mistral 모델에서 거의 동일한 성능을 유지하며, 주요 벤치마크에서 높은 정확도를 기록했습니다.
6. KIVI의 의의
KIVI는 양자화 방식을 활용해 대규모 언어 모델의 효율성을 극대화하면서도 성능 저하를 최소화한 혁신적인 솔루션입니다.GitHub에서 공개된 소스 코드를 통해, 다양한 환경에서 KIVI를 쉽게 적용할 수 있습니다.
LLMs은 다양한 작업에서 강력한 성능을 보여주고 있음
하지만, 이러한 모델의 배포는 많은 GPU가 필요하여 매우 높은 비용이 소요
높은 비용을 절감하기 위해 가장 자연스러운 방법 중 하나는 여러 요청을 하나로 묶어 배치 처리(batch processing)를 수행하는 것
그러나 이러한 배치 추론(batch inference) 환경에서, 재계산을 방지하기 위해 생성 중 주의(attention) 키(key)와 값(value)을 저장하는 키-값(KV) 캐시가 메모리 및 속도 면에서 새로운 병목현상이 되고 있음
이 문제는 배치 크기가 크거나 문맥 길이가 길어질수록 더욱 심각해짐
예를 들어, 540B PaLM 모델에서 배치 크기가 512이고 문맥 길이가 2048일 때, KV 캐시만으로도 3TB의 메모리를 차지하며, 이는 모델 매개변수 크기의 3배에 해당
또한, GPU의 SRAM은 생성된 각 토큰마다 GPU 디바이스 메모리에서 전체 KV 캐시를 로드해야 하며, 이 과정에서 계산 코어는 비활성화 상태로 유지, 따라서, 정확성을 유지하면서 KV 캐시 크기를 줄이는 것이 중요
계산 코어(연산 장치)가 필요한 데이터를 기다리느라 실제 연산을 수행하지 못하는 상태
이는 메모리 병목 현상(memory bottleneck)으로 인해 GPU의 성능이 최대로 발휘되지 못하는 문제를 발생
이 문제를 해결하기 위한 기존 연구는 크게 세 가지로 나눌 수 있음
첫째, multi-query attention 또는 multi-group attention과 같이 KV 캐시의 head 수를 줄이는 방법
하지만, 이러한 방법은 모델을 처음부터 다시 학습시키거나 기존 모델을 미세 조정해야 함
둘째, 다른 연구 방향으로는 중요하지 않은 토큰을 제거하여 KV 캐시 크기를 줄이는 방법
셋째, KV 캐시를 오프로드하거나 가상 메모리와 페이징 기술을 어텐션 메커니즘에 확장하는 방법과 같은 시스템 관점에서 문제를 해결하려는 연구가 있습니다.
KV 캐시 크기를 줄이는 가장 간단하고 효과적인 방법은 KV 캐시가 차지하는 총 바이트를 줄이는, 즉 양자화
잘 연구된 가중치 양자화(weight quantization)와 달리, 현재까지 KV 캐시에 대해 단순한 4비트 반올림 양자화만 적용된 사례가 소수에 불과하며, 이는 KV 캐시의 스트리밍 특성 및 기타 복잡성 때문입니다. KV 캐시 양자화의 어려움과 한계를 이해하기 위한 요소 분포에 대한 심도 있는 연구가 부족한 상황입니다. 이를 해결하기 위해, 우리는 인기 있는 LLM의 KV 캐시 요소 분포를 연구하였습니다. 우리의 분석 결과는 다음과 같습니다.
- 키 캐시: 일부 고정된 채널이 매우 큰 크기를 가지며, 이는 이전 연구 결과와 일치합니다(Lin et al., 2023; Xiao et al., 2023a). 따라서, 키 캐시는 채널별로 양자화되어야 하며, 이는 채널별로 요소를 그룹화하고 함께 양자화하는 것을 의미합니다. 이를 통해 각 개별 채널 내에서 오류를 제한하고 다른 일반 채널에는 영향을 미치지 않게 할 수 있습니다.
- 값 캐시: 명확한 이상치(outlier) 패턴이 없습니다. 값 캐시는 주의 출력 계산에 사용되며, 본질적으로 값 캐시 혼합기 역할을 합니다. 따라서, 값 캐시는 토큰별로 양자화되어야 하며, 이는 각 개별 토큰 내에서 오류를 제한하고 한 토큰의 양자화가 다른 토큰에 부정적인 영향을 미치지 않도록 보장합니다.
위 결과를 바탕으로, 우리는 KIVI라는 플러그 앤 플레이 방식의 초저비트 KV 캐시 양자화 방법을 제안합니다. KIVI는 키 캐시를 채널별로 양자화하고, 값 캐시는 토큰별로 양자화합니다. 토큰별 값 캐시 양자화는 자동회귀(auto-regressive) 추론의 스트리밍 특성과 잘 맞아, 새로 양자화된 텐서를 기존 값 캐시에 토큰 차원에서 직접 추가할 수 있도록 합니다. 그러나 채널별 키 캐시 양자화는 여러 토큰에 걸쳐 양자화 과정을 수행해야 하므로 스트리밍 환경에서는 직접 구현할 수 없습니다. 이에 따라, 키 캐시를 두 부분으로 나누는 아이디어를 도입하였습니다. 첫 번째는 여러 토큰 그룹으로 이루어진 그룹화된 키 캐시이며, 두 번째는 완전한 그룹을 형성할 수 없는 잔여 키 캐시입니다. 값 캐시 역시 정확도를 유지하기 위해 그룹화된 부분과 잔여 부분으로 나눕니다. 그룹화된 키 캐시와 값 캐시에만 그룹 단위 양자화를 적용하며, 잔여 키 캐시와 값 캐시는 풀프리시전(full precision)으로 유지합니다. 이러한 그룹화된 부분과 잔여 부분은 타일드 행렬 곱셈을 사용하여 주의 점수를 계산할 때 결합될 수 있습니다.
우리의 기여는 다음과 같습니다:
- 일반적으로 사용되는 LLM의 KV 캐시 이상치 패턴 및 양자화 오류에 대한 광범위한 분석을 수행하였습니다. 이 분석을 통해 키 캐시는 채널별로, 값 캐시는 토큰별로 양자화되어야 함을 관찰하였으며, 이러한 캐시들이 왜 다른 양자화 접근법이 필요한지 심도 있게 설명하였습니다.
- KIVI라는 새로운 플러그 앤 플레이 2비트 KV 캐시 양자화 알고리즘을 개발하였습니다. 이 알고리즘은 하드웨어 친화적이며 별도의 미세 조정 없이 사용 가능합니다. 우리는 Llama(Llama-2), Mistral, Falcon과 같은 모델에서 KIVI를 평가하였으며, KV 캐시를 2비트로 효율적으로 압축하여 Llama-2-7B 모델의 피크 메모리 사용량을 2.6배 줄이면서 정확도 손실은 거의 없음을 확인하였습니다. 이 메모리 절감은 최대 4배 더 큰 배치 크기를 가능하게 하며, 2.35배에서 3.47배에 달하는 처리량 향상을 가져옵니다.
2. 배경: 어텐션 추론 시간 워크플로우
대규모 언어 모델(LLM)의 어텐션 추론 시간 워크플로우는 두 단계로 구성됩니다.
1. **프리필(prefill) 단계**: 입력 프롬프트를 사용하여 LLM의 각 Transformer 레이어에 대한 KV 캐시를 생성하는 단계입니다.
2. **디코딩(decoding) 단계**: 모델이 KV 캐시를 사용하고 이를 업데이트하며, 한 번에 한 개의 토큰을 생성하는 단계입니다.
### 프리필 단계
입력 텐서를 \( X \in \mathbb{R}^{b \times l_{\text{prompt}} \times d} \)라고 하겠습니다. 여기서
- \( b \): 배치 크기
- \( l_{\text{prompt}} \): 입력 프롬프트의 길이
- \( d \): 모델의 히든 크기입니다.
레이어 인덱스는 편의를 위해 생략합니다. 키(key)와 값(value) 텐서는 다음과 같이 계산됩니다:
\[
X_K = X W_K, \quad X_V = X W_V,
\]
여기서 \( W_K, W_V \in \mathbb{R}^{d \times d} \)는 각각 키와 값 레이어의 가중치입니다. \( X_K \)와 \( X_V \)를 디코딩을 쉽게 하기 위해 메모리에 저장합니다.
---
### 디코딩 단계
현재 입력 토큰 임베딩을 \( t \in \mathbb{R}^{b \times 1 \times d} \)라고 하겠습니다. 키와 값 레이어 출력은 각각 다음과 같이 계산됩니다:
\[
t_K = t W_K, \quad t_V = t W_V.
\]
이후 KV 캐시를 다음과 같이 업데이트합니다:
\[
X_K \leftarrow \text{Concat}(X_K, t_K), \quad X_V \leftarrow \text{Concat}(X_V, t_V).
\]
그런 다음 어텐션 출력을 계산합니다:
\[
t_Q = t W_Q,
\]
\[
A = \text{Softmax}(t_Q X_K^\top),
\]
\[
t_O = A X_V,
\]
여기서 \( W_Q \)는 쿼리 레이어의 가중치 행렬입니다. 설명의 편의를 위해 어텐션 출력 레이어와 추론 워크플로우의 다른 부분은 생략합니다.
---
### 메모리 및 속도 분석
위 과정은 문장이 종료되는 특별 토큰이 생성될 때까지 반복됩니다.
생성된 토큰의 개수를 \( l_{\text{gen}} \)라고 하면, KV 캐시의 크기는 다음과 같습니다:
\[
b \times (l_{\text{prompt}} + l_{\text{gen}}) \times d.
\]
예를 들어, OPT-175B 모델에서 배치 크기 \( b = 512 \), 프롬프트 길이 \( l_{\text{prompt}} = 512 \), 출력 길이 \( l_{\text{gen}} = 32 \)인 경우, KV 캐시는 1.2TB의 메모리를 요구하며 이는 모델 가중치 크기의 3.8배에 해당합니다(Sheng et al., 2023).
또한, 추론 속도는 KV 캐시 크기에 의해 결정됩니다. GPU는 생성된 각 토큰마다 GPU 메인 메모리에서 GPU SRAM으로 KV 캐시를 로드해야 하며, 이 과정에서 GPU의 계산 코어는 사실상 비활성화 상태가 됩니다(Pope et al., 2023; Kwon et al., 2023).
### 3. Methodology (방법론)
---
긴 문맥 또는 배치 추론 시나리오에서, 메모리 및 속도의 병목현상은 KV 캐시를 저장하고 로드하는 과정에서 발생합니다. 이러한 문제를 완화하는 가장 간단하고 효과적인 방법은 KV 캐시가 차지하는 총 바이트 수를 줄이는 것, 즉 양자화(quantization)입니다. 이를 기반으로, 우리는 먼저 기존 양자화 방법의 성능을 평가했으며, 결과적으로 키와 값 캐시가 서로 다른 차원에서 양자화되어야 함을 확인했습니다. 이러한 관찰의 근거를 분석한 후, 새로운 KV 캐시 양자화 방법 **KIVI**와 이를 위한 스트리밍 데이터 구조를 제안합니다.
---
#### 3.1. KV 캐시 양자화에 대한 예비 연구
2장에서 분석한 바와 같이, KV 캐시는 스트리밍 데이터 구조로 동작하며 새로운 텐서가 순차적으로 도착합니다. 따라서 GPTQ(Frantar et al., 2022)와 같은 최적화 기반 방법은 과도한 오버헤드로 인해 KV 캐시 양자화에 적합하지 않습니다. 현재로서는 KV 캐시를 양자화하는 가장 유연한 방법은 반올림(round-to-nearest) 양자화입니다.
\( B \)-비트 정수 양자화 및 역양자화 과정은 다음과 같이 표현됩니다:
\[
Q(X) = \left\lfloor \frac{X - z_X}{s_X} \right\rceil, \quad X' = Q(X) \cdot s_X + z_X,
\]
여기서:
- \( z_X = \min(X) \): 제로 포인트(zero-point),
- \( s_X = \frac{\max(X) - \min(X)}{2^B - 1} \): 스케일링 계수(scaling factor),
- \( \lfloor \cdot \rceil \): 반올림 연산입니다.
편의를 위해 배치 크기와 관련된 세부 사항은 생략합니다. 그림 1에서 보이는 것처럼, \( X \)는 토큰 차원 또는 채널 차원을 따라 그룹 단위로 양자화됩니다.
KV 캐시의 스트리밍 특성을 고려할 때, 이전 연구들은 종종 키와 값 캐시에 대해 토큰 단위 양자화를 적용했습니다. 이는 새로 양자화된 KV 캐시를 토큰 차원에서 기존 양자화된 캐시에 간단히 추가할 수 있기 때문입니다(Sheng et al., 2023). 반면 채널 단위 양자화는 구현이 까다롭지만, 우리는 이를 탐구하기 위해 채널 단위 양자화를 위한 패딩(padding) 방법을 설계하여 키와 값 캐시에 미치는 영향을 연구했습니다.

#### 실험 설정
표 1은 Llama-2-13B 모델을 사용해 CoQA 및 TruthfulQA 작업에서 다양한 설정으로 그룹 단위로 KV 캐시를 양자화한 결과를 보여줍니다. 모든 설정에서 그룹 크기는 32로 설정했습니다.
**가상 양자화(fake quantization)**란, KV 캐시를 먼저 낮은 정밀도로 양자화한 다음 어텐션 레이어에서 이를 역양자화하는 과정을 시뮬레이션하는 것입니다. 채널 단위 양자화의 경우, 토큰 수가 그룹으로 나누어 떨어지지 않으면 제로 패딩(zero-padding)을 추가해 완벽한 그룹화를 보장합니다. 이를 통해 모든 KV 캐시 토큰이 공정하게 비교될 수 있도록 양자화합니다. 자세한 실험 설정은 4.1절에서 확인할 수 있습니다.
---
#### 주요 관찰
- **(OB 1)** 키와 값 캐시 모두에 대해 일반적으로 사용되는 토큰 단위 양자화는 INT4 정밀도에서 정확도를 유지할 수 있습니다. 그러나 INT2로 줄일 경우 정확도가 크게 하락합니다.
- **(OB 2)** 값 캐시를 채널 단위로 양자화하면 키 캐시 양자화 방법에 관계없이 정확도가 크게 떨어집니다.
- **(OB 3)** 낮은 정밀도(INT2)를 사용할 경우, 키 캐시는 채널 단위로, 값 캐시는 토큰 단위로 양자화하는 것이 가장 정확한 방법입니다.

#### 3.2 키와 값 캐시가 다른 차원에서 양자화되어야 하는 이유
표 1에서 키 캐시를 채널 단위로, 값 캐시를 토큰 단위로 양자화했을 때 2비트에서도 매우 작은 정확도 손실을 관찰했습니다. 여기서는 왜 이 설정이 더 나은 정확도를 제공하는지 분석합니다.
그림 2는 서로 다른 레이어에서 원래 KV 캐시 분포를 시각화한 것입니다. 키 캐시에서는 일부 고정된 채널이 매우 큰 크기를 보이는 반면, 값 캐시에서는 명확한 이상치(outlier) 패턴이 관찰되지 않았습니다.

#### 키 캐시 분석
키 캐시에서 관찰된 현상은 특정 고정 열이 더 큰 이상치를 보인다는 이전 연구 결과와 일치합니다(Dettmers et al., 2022; Lin et al., 2023).
각 채널 내에서 이상치가 지속적으로 나타나므로 채널 단위 양자화는 양자화 오류를 개별 채널로 제한하고 다른 정상 채널에는 영향을 미치지 않을 수 있습니다. 따라서 그림 2는 키 캐시가 채널 단위로 양자화되어야 하는 이유를 설명합니다.
표 2는 다음과 같은 두 가지 상대적 오류를 보여줍니다:
1. **키 캐시 재구성 오류**:
\[
\frac{\| X_K - X_K' \|_F}{\| X_K \|_F}
\]
2. **어텐션 점수 상대적 오류**:
\[
\frac{\| A - A' \|_F}{\| A \|_F}, \quad A' = \text{Softmax}(t_Q X_K'^\top).
\]
토큰 단위 양자화는 채널 단위 양자화에 비해 어텐션 점수에서 약 5배 더 큰 오류를 유발하는 것으로 관찰되었으며, 이는 그림 2와 일치합니다.
---
#### 값 캐시 분석
키 캐시와 달리, 값 캐시는 채널별 이상치 패턴을 보여주지 않습니다. 그림 2만으로는 값 캐시가 반드시 토큰 단위로 양자화되어야 한다는 OB2를 설명할 수 없습니다. 방정식 (1)에서 보이는 것처럼, 값 캐시는 어텐션 출력 \( t_O \)를 계산하는 데 사용됩니다. 따라서 값 캐시 \( X_V \)의 양자화 오류를 분석하는 대신, 표 2에서는 서로 다른 양자화 설정에 따른 상대적 오류 \( \Delta \)를 분석했습니다:
\[
\Delta = \frac{\| A X_V - A X_V' \|_F}{\| A X_V \|_F}.
\]
놀랍게도, 토큰 단위 양자화의 오류가 채널 단위 양자화보다 거의 15배 작게 나타났으며, 이는 OB2가 발생하는 이유를 설명합니다. 이러한 관찰의 직관적인 근거는 어텐션 희소성(sparsity)에 있습니다. 방정식 (1)은 다음과 같이 다시 쓸 수 있습니다:
\[
t_O = A X_V.
\]
희소한 어텐션 행렬 \( A \)가 값 캐시 \( X_V \)와 곱해질 때, 특정 토큰에만 국한된 정보가 반영되므로 토큰 단위 양자화가 오류를 효과적으로 줄이는 데 유리합니다.

### 3.3 KIVI: 알고리즘 및 시스템 지원
#### 알고리즘
앞서 분석한 바와 같이, 키 캐시는 채널 단위로 양자화되어야 하고, 값 캐시는 토큰 단위로 양자화되어야 합니다. 새롭게 생성된 토큰의 키와 값 캐시는 순차적으로 도착합니다. 구현 관점에서, 토큰 단위 양자화는 스트리밍 환경과 잘 맞으며, 새로 양자화된 텐서를 기존 양자화된 값 캐시의 토큰 차원에 바로 추가할 수 있습니다. 반면, 채널 단위 양자화는 여러 토큰에 걸쳐 양자화가 수행되므로 스트리밍 환경에서는 바로 구현하기 어렵습니다.
그림 3에서 보이듯, 이를 해결하기 위한 핵심 아이디어는 키 캐시를 \( G \)개의 토큰 단위로 그룹화하여 각각 별도로 양자화하는 것입니다. 키 캐시 \( \mathbf{X}_K \)의 토큰 수가 임의일 수 있기 때문에, 이를 두 부분으로 나눕니다:
\[
\mathbf{X}_{K_g} = \mathbf{X}_K[:l - r], \quad \mathbf{X}_{K_r} = \mathbf{X}_K[l - r:],
\]
여기서:
- \( l \): 현재 키 캐시 \( \mathbf{X}_K \) 내의 토큰 수,
- \( r \): 잔여(residual) 토큰의 수,
- \( l - r \): \( G \)로 나누어질 수 있는 토큰 수.
그룹화된 키 캐시 \( \mathbf{X}_{K_g} \)는 \( \frac{l - r}{G} \)개의 그룹으로 균등하게 나눌 수 있습니다. 우리는 이 그룹화된 키 캐시를 **그룹 단위 양자화** \( Q(\mathbf{X}_{K_g}) \)로 저장하며, 잔여 키 캐시 \( \mathbf{X}_{K_r} \)는 풀 프리시전(full precision)으로 유지합니다. 디코딩 과정에서는 새로 도착한 키 캐시 \( \mathbf{t}_K \)를 \( \mathbf{X}_{K_r} \)에 추가하며, \( \mathbf{X}_{K_r} \)이 \( R \)개의 토큰(잔여 길이 \( R \))에 도달하면 이를 양자화하여 이전에 양자화된 \( Q(\mathbf{X}_{K_g}) \)에 연결합니다. 이후 \( \mathbf{X}_{K_r} \)은 빈 텐서로 초기화됩니다. 여기서 \( R \)은 \( G \)로 나누어질 수 있어야 합니다.
---
#### 어텐션 로짓 계산
타일드 행렬 곱셈(tiled matrix multiplication)을 통해 원시 어텐션 로짓은 다음과 같이 계산됩니다:
\[
\mathbf{A}_g = \mathbf{t}_Q Q(\mathbf{X}_{K_g}^\top),
\]
\[
\mathbf{X}_{K_r} = \text{Concat}([\mathbf{X}_{K_r}, \mathbf{t}_K]),
\]
\[
\mathbf{A}_r = \mathbf{t}_Q \mathbf{X}_{K_r}^\top,
\]
\[
\mathbf{A} = \text{Concat}([\mathbf{A}_g, \mathbf{A}_r]).
\]
여기서:
- \( \mathbf{t}_Q \): 현재 토큰의 쿼리 벡터,
- \( \mathbf{X}_{K_g} \): 그룹화된 키 캐시,
- \( \mathbf{X}_{K_r} \): 잔여 키 캐시.
---
#### 값 캐시 관리
값 캐시 역시 키 캐시와 유사하게 두 부분으로 나눕니다. 최신 값 캐시는 풀 프리시전으로 유지하며, 다음과 같이 구성됩니다:
\[
\mathbf{X}_{V_g}: \text{그룹 단위 양자화된 값 캐시}, \quad \mathbf{X}_{V_r}: \text{잔여 값 캐시}.
\]
새로 도착한 값 캐시는 큐(queue)에 추가되며, 큐가 정의된 잔여 길이 \( R \)에 도달하면 가장 오래된 값 캐시를 제거(pop)하고, 이를 토큰 단위로 양자화하여 이전 양자화된 값 캐시에 연결합니다.
---
#### 프리필 단계의 처리
그림 3에 나타난 바와 같이, 프리필(prefill) 단계에서는 정확한 키와 값 텐서가 다음 레이어로 전달되지만, 메모리에는 양자화된 KV 캐시만 유지됩니다. 전체 알고리즘은 부록 A의 **알고리즘 1**에서 확인할 수 있습니다.
---
#### 분석
KIVI에서는:
- 그룹화된 키 캐시 \( \mathbf{X}_{K_g} \)와 그룹화된 값 캐시 \( \mathbf{X}_{V_g} \)는 양자화되며,
- 잔여 키 캐시 \( \mathbf{X}_{K_r} \)와 잔여 값 캐시 \( \mathbf{X}_{V_r} \)는 풀 프리시전으로 유지됩니다.
설계상, \( \mathbf{X}_{K_r} \) 또는 \( \mathbf{X}_{V_r} \)에는 최대 \( R \)개의 토큰만 포함됩니다. 실제로 \( R \leq 128 \)로 설정하며, \( l_{\text{prompt}} + l_{\text{gen}} \)의 시퀀스 길이는 보통 \( R \)보다 훨씬 깁니다. 따라서 극도로 낮은 비트 양자화의 이점을 고려할 때 \( \mathbf{X}_{K_r} \)와 \( \mathbf{X}_{V_r} \)로 인한 메모리 오버헤드는 무시할 수 있습니다.
또한, 새로 도착한 키와 값 텐서가 \( \mathbf{X}_{K_r} \)와 \( \mathbf{X}_{V_r} \)에 풀 프리시전으로 추가되므로, KIVI는 지역적으로 관련된 토큰에 대한 풀 프리시전 KV 캐시 **슬라이딩 윈도우**를 유지합니다. 이 윈도우 크기는:
- 키 캐시: \( R^2 \),
- 값 캐시: \( R \).
이 슬라이딩 윈도우는 GSM8K와 같은 어려운 작업에서 바람직한 성능을 유지하는 데 중요합니다.
4. 실험
4.1 설정
- 모델: KIVI는 Llama/Llama-2 (Touvron et al., 2023a; b), Falcon (Penedo et al., 2023), Mistral (Jiang et al., 2023) 모델에서 평가되었습니다. Llama와 Mistral은 다중 헤드 어텐션(multi-head attention)을 기반으로 하고, Falcon은 멀티 쿼리 어텐션(multi-query attention, Shazeer, 2019)을 기반으로 합니다. Hugging Face Transformers 코드베이스를 활용하여 KIVI 알고리즘을 구현했습니다. 기존 연구(Sheng et al., 2023)를 따라, 양자화 그룹 크기 G는 모든 실험에서 32로 설정되었으며, 키와 값 캐시의 잔여 길이 R는 128로 설정했습니다.
- 작업: 2장에서 분석한 바와 같이, KV 캐시 크기는 문맥 길이에 따라 커집니다. 따라서, KIVI는 일반 문맥 길이와 긴 문맥 설정에서 각각 평가되었습니다.
- 일반 문맥 길이 평가: LM-Eval(Gao et al., 2021)에서 제공하는 생성 작업(CoQA: 정확도, TruthfulQA: BLEU 점수, GSM8K: 정확도)을 사용.
- 긴 문맥 평가: LongBench(Bai et al., 2023)의 작업을 활용. 최대 시퀀스 길이는 Mistral 모델에서는 8192, 다른 모델에서는 4096으로 설정.
- 하위 그룹 작업:
- 단일 문서 QA: Qasper(F1 점수),
- 요약: QMSum(ROUGE 점수), MultiNews(ROUGE 점수),
- Few-shot 학습: TREC(분류 점수), TriviaQA(F1 점수), SAMSum(ROUGE 점수),
- 코드 완성: LCC(유사도 점수), RepoBench-P(유사도 점수).
- 하위 그룹 작업:
4.2 정확도와 효율성 분석
4.2.1 양자화 설정 비교
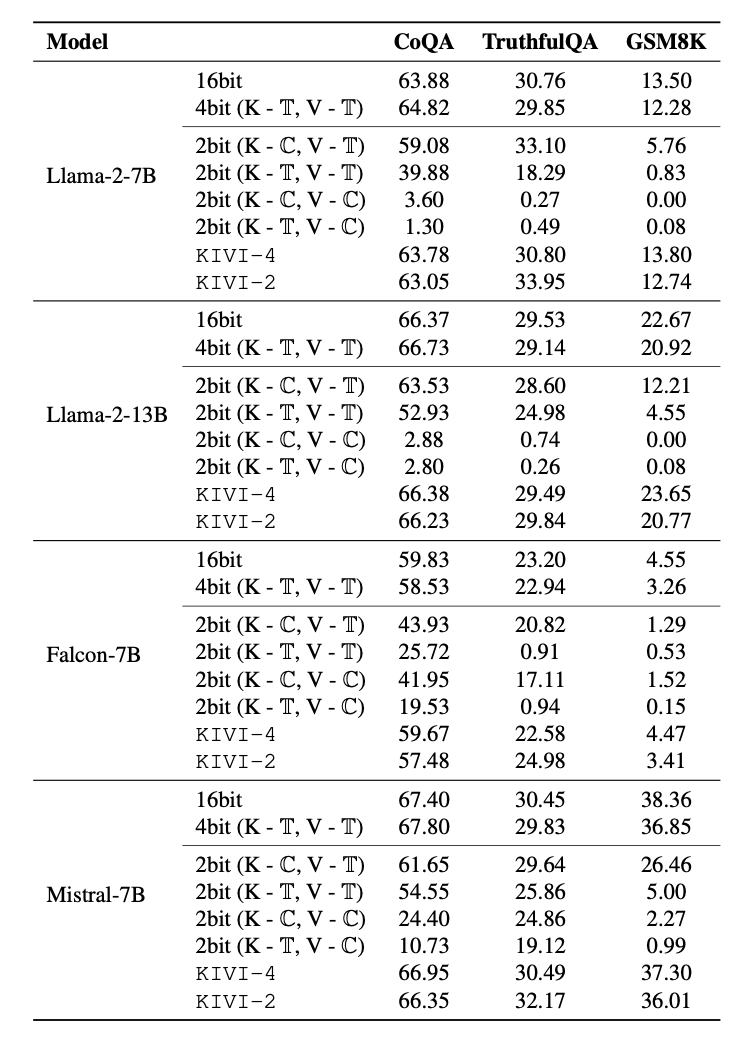
가상 양자화(fake quantization)를 사용하여 키 캐시를 채널 단위, 값 캐시를 토큰 단위로 양자화하는 비대칭 양자화의 효과를 입증했습니다(표 1 참조). 실험 결과는 다음과 같습니다:
- "2bit (K: 채널 단위, V: 토큰 단위)" 설정이 항상 다른 설정보다 우수한 결과를 보여줌.
- GSM8K와 같은 어려운 생성 작업에서는, 가상 "2bit (K: 채널 단위, V: 토큰 단위)" 양자화의 정확도가 풀 프리시전보다 크게 떨어짐.
- 그러나 KIVI를 적용한 경우, 정확도 하락이 2% 이내로 제한됨. 이는 KIVI가 풀 프리시전 슬라이딩 윈도우를 유지하여 지역적으로 중요한 토큰의 정확도를 보존하기 때문.
4.2.2 생성 작업에서의 정확도 비교
- LM-Eval 결과:
- CoQA, TruthfulQA, GSM8K 작업에서 KIVI는 Llama-2-7B, Llama-2-13B, Falcon-7B, Mistral-7B 모델에 대해 평가됨.
- Llama 및 Mistral 모델에서는 KIVI로 16bit에서 2bit로 줄였을 때 정확도 하락이 최대 2% 이내로 유지됨.
- Falcon-7B는 KV 캐시가 이미 고도로 압축된 구조(단일 헤드)를 사용하기 때문에 2bit KIVI에서는 정확도 하락이 큼. 4bit KIVI가 Falcon 모델에서 더 적합함.
- LongBench 결과:
- 다양한 모델(Llama-2, Mistral, LongChat 등)에서 KIVI가 긴 문맥 생성 작업에 대해 높은 정확도를 유지하면서 KV 캐시를 효과적으로 압축함.
4.2.3 세부 실험 (Ablation)
- 그룹 크기의 효과:
- 잔여 길이 R를 128로 고정하고 그룹 크기 G를 32, 64, 128로 변경.
- 그룹 크기가 128에 도달했을 때 성능이 크게 하락함.
- 잔여 길이의 효과:
- 그룹 크기를 32로 고정하고 잔여 길이 R를 32, 64, 96, 128로 변경.
- 잔여 길이가 128에서 좋은 결과를 보였지만, 32와 96도 유사한 결과를 보임. 64에서는 성능이 최악으로 나타남.

### 4.2.4. 효율성 비교
KIVI의 실시간 처리 효율성을 평가하기 위해, vLLM(Kwon et al., 2023)을 따라 ShareGPT(sha, 2023)를 기반으로 워크로드를 생성했습니다. 이 데이터셋은 실제 LLM 서비스의 입력과 출력 텍스트를 포함하며, 평균적으로 입력 프롬프트 길이 \( l_{\text{prompt}} \)는 161, 출력 길이 \( l_{\text{gen}} \)은 338입니다(Kwon et al., 2023). 우리는 배치 크기를 메모리가 초과될 때까지 점진적으로 증가시키며, Llama-2-7B 모델에서 KIVI(잔여 길이 32와 128)와 FP16 기준 설정의 최대 메모리 사용량과 처리량(throughput)을 비교했습니다. 하드웨어는 NVIDIA A100 GPU(80GB)를 사용했습니다.
그림 4에서 보이듯, KIVI는 FP16과 유사한 최대 메모리 사용량에서 **최대 4배 더 큰 배치 크기**를 처리할 수 있으며, **2.35배에서 3.47배 더 높은 처리량**을 제공합니다. 이 처리량 증가는 문맥 길이와 출력 길이가 길어질수록 더 커질 수 있습니다. 또한, KV 캐시 양자화 과정을 이전 연산과 추가로 통합하면 속도 향상이 더욱 증가할 수 있음을 언급합니다. 이는 향후 연구 과제로 남겨둡니다.


5. 관련 연구
대규모 언어 모델(LLM)의 학습 및 추론 과정을 확장하기 위한 다양한 기계 학습 시스템 연구가 제안되었습니다(Pope et al., 2023; Wang et al., 2023; 2022). 이 중에서도 양자화(quantization) 기법이 널리 활용되고 있습니다(Frantar et al., 2022; Lin et al., 2023; Kim et al., 2023; Xu et al., 2023).
LLM 양자화의 주요 연구 방향은 **가중치 전용 양자화(weight-only quantization)**로, 모델 가중치를 낮은 정밀도로 양자화하는 것을 포함합니다.
- 예를 들어, AWQ(Lin et al., 2023)는 활성화(activation)를 고려하여 모델 가중치를 INT4 및 INT3으로 양자화합니다.
- GPTQ(Frantar et al., 2022)는 근사 2차 정보를 사용하여 모델 가중치를 정확하고 효율적으로 양자화합니다.
- SqueezeLLM(Kim et al., 2023)은 민감도 기반 비균일 양자화(sensitivity-based non-uniform quantization)와 밀도-희소 분해(Dense-and-Sparse decomposition)를 결합합니다.
이 연구들은 우리의 연구와 상호 보완적이며, 함께 사용할 수 있습니다.
SmoothQuant(Xiao et al., 2023a)는 활성화와 가중치의 양자화 복잡도를 균형 있게 조정하는 사후 학습 양자화(post-training quantization) 기법으로, 활성화를 더 쉽게 양자화할 수 있습니다. SmoothQuant는 KV 캐시를 8비트로 압축하면서 성능 손실을 최소화하지만, 4비트 이하로 축소할 경우 성능이 크게 저하됩니다(Zhao et al., 2024). FlexGen은 키와 값 캐시에 대해 모두 4비트 토큰 단위 양자화를 채택합니다.
KIVI의 중요한 구성 요소는 3.2절과 그림 2에서 분석한 **채널 단위 양자화(per-channel quantization)**입니다.
- ATOM(Zhao et al., 2024) 또한 키 캐시가 값 캐시보다 더 많은 이상치(outliers)를 포함한다고 지적했습니다.
- KIVI는 이 관찰을 기반으로 더욱 포괄적인 분석을 수행하고 이를 활용하여 채널 단위 양자화를 구현합니다.
- 유사한 관찰과 접근 방식은 동시 연구 KVQuant(Hooper et al., 2024)에서도 독립적으로 개발되었습니다.
vLLM(Kwon et al., 2023) 및 S3(Jin et al., 2023)은 **시스템 레벨 최적화(system-level optimization)**로, PagedAttention이나 메모리 사용 예측(memory usage prediction)을 통해 메모리 요구량을 줄이고 모델 처리량을 높였습니다. 이 연구 방향은 우리의 연구와 상호 보완적이며, 시스템 최적화를 KIVI 알고리즘에도 적용할 수 있습니다.
KV 캐시를 압축하기 위해 토큰 제거(token eviction)를 고려한 연구도 있습니다:
- H2O(Zhang et al., 2023)는 어텐션 점수에 크게 기여하는 일부 토큰만 유지합니다.
- Scissorhands(Liu et al., 2024)는 KV 캐시 희소화를 위한 중요도 지속 가설(persistence of importance hypothesis)을 활용합니다.
- StreamingLLM(Xiao et al., 2023b)은 "어텐션 싱크(attention sink)"를 관찰하여 초기 몇 개의 토큰만 유지해 성능을 보존합니다.
하지만 KIVI는 입력된 모든 토큰을 유지하고 이를 낮은 정밀도로 압축합니다. 이러한 연구 방향 역시 우리의 접근법과 상호 보완적이며 결합하여 사용할 수 있습니다.
6. 결론 및 향후 연구
이 논문에서는 대규모 언어 모델(LLM)에서 KV 캐시 요소 분포를 체계적으로 분석했습니다.
- 키 캐시는 채널 단위로, 값 캐시는 토큰 단위로 양자화되어야 한다는 결론을 도출했습니다.
- 이를 바탕으로 KIVI라는 플러그 앤 플레이 방식의 2비트 KV 캐시 양자화 알고리즘을 제안했으며, 추가적인 조정 없이 사용할 수 있습니다.
- 실제 LLM 워크로드에서 KIVI는 최대 4배 더 큰 배치 크기와 3.47배 더 높은 처리량을 가능하게 합니다.
향후 연구로는 프리필(prefill) 및 디코딩(decoding) 단계에서 양자화 과정의 오버헤드를 줄이기 위해 구현을 더욱 최적화할 계획입니다.


