-
[논문 리뷰] 49. Examining Inter-Consistency of Large Language Models Collaboration:An In-depth Analysis via Debate논문 2025. 3. 29. 17:59
LLM은 다양한 응용 분야에서 인상적인 성능을 보여주고 있으나, 여전히 여러 형태의 불일치(inconsistency) 문제에 직면해 있다. 기존 연구들은 주로 단일 LLM 내의 일관성 문제에 집중해온 반면, 본 연구는 다수의 LLM 간 협업에서 발생하는 상호 일관성(inter-consistency) 문제를 보완적으로 탐구한다.
LLM들이 공동의 목표를 위해 효과적으로 협력하고 합의를 이룰 수 있는지를 살펴보기 위해, 우리는 상식 추론(commonsense reasoning) 작업에 집중하며, 현실 시나리오에 정렬된 세 단계의 토론 구조를 갖는 공식적인 토론 프레임워크 FORD(Formal Debate Framework)를 제안한다. 세 단계는 다음과 같다:
공정한 토론(fair debate)
능력 불일치 토론(mismatched debate)
그리고 원탁 토론(roundtable debate)이다.
다양한 데이터셋에서의 광범위한 실험을 통해, LLM들은 명확한 상호 불일치가 존재함에도 불구하고 효과적으로 협력하여 합의에 이를 수 있음을 확인하였다. 그러나 능력 차이가 있는 경우, 성능이 우수한 LLM이 토론을 주도하게 되는 경향이 있다. GPT-4와 같은 더 진보된 LLM을 권위 있는 판사(judge)로 활용하면 협업 성능을 향상시킬 수 있음을 발견하였다.

ChatGPT와 같은 대규모 언어 모델(LLM)은 최근 일반 지능(general intelligence)의 가능성을 보여주었으며(Bubeck et al., 2023), 다양한 응용 분야에서 기반 모델로 널리 활용되고 있다(Wei et al., 2022b; Wu et al., 2023). 복잡한 작업을 해결하기 위해, 다수의 LLM이 협업하는 방식이 도입되었으며, 각 모델은 서로 다른 하위 작업이나 관점을 담당한다(Schick et al., 2022; Park et al., 2023). 그렇다면 이러한 LLM들은 협업 정신(collaborative spirit)을 가지고 있을까? 과연 이들은 공동의 목표를 향해 효과적이고 성능적으로 협력할 수 있을까?
본 연구에서는 기존의 단일 LLM의 자기 일관성(self-consistency)에 집중했던 연구들과 보완적으로, 다수 LLM 간의 상호 일관성(inter-consistency)에 주목한다(Wang et al., 2022b; Jung et al., 2022).
우리의 관찰에 따르면, LLM 협업에서 다음과 같은 두 가지 주요 상호 일관성 문제가 드러난다.
첫째, LLM의 관점은 쉽게 흔들린다.
그림 1(a)에서 보이듯, 찬성측(proponent)과 반대측(opponent) LLM은 서로 다른 예측을 하다가, 찬성측이 상대의 의견에 빠르게 타협한다. LLM들은 자신만의 관점을 얼마나 고수하거나 쉽게 바꾸는가?
둘째, 그림 1(b)에서처럼 일부 LLM이 자신의 입장을 고수할 경우, 공동 목표를 위한 합의(consensus)는 가능할까?
이에 영감을 받아, 우리는 토론 이론(debate theory)(Mayer, 1997)에 기반한 공식 토론 프레임워크 FORD(Formal Debate Framework)를 고안하여 LLM 간의 상호 불일치 문제를 체계적이고 정량적으로 분석하고자 한다.
FORD는 LLM들이 서로의 이해와 개념화를 토론을 통해 비교·학습하게 함으로써, 다양한 관점을 유도하고 상호 학습(mutual learning)을 통해 성능을 향상시킬 수 있는 가능성을 제시한다.
구체적으로, 본 연구는 선다형 상식 추론(multiple-choice commonsense reasoning)을 실험 대상으로 삼았다. 이 작업은 LLM 협업의 상호 불일치를 정량적으로 평가하기에 적합하다. 우리는 실제 시나리오를 반영한 세 단계의 토론 구조를 설계하였다:
- 공정한 토론: 유사한 능력을 지닌 두 LLM 간의 토론
- 불균형 토론: 능력 차이가 큰 두 LLM 간의 토론
- 원탁 토론: 셋 이상의 LLM이 참여하는 다자간 토론
또한, OpenAI의 GPT-4가 뛰어난 성능을 보이고 있기에, 이를 심판 역할(judge)로 도입하여 토론을 요약하고 결론을 도출하는 방식도 분석에 포함하였다. FORD는 향후 더 강력한 LLM이나 다양한 모델 조합에도 유연하게 적용 가능하다.
1. 토론 이론(Debate Theory) 설명
토론 이론(Debate Theory)은 Mayer(1997)의 이론을 바탕으로, 의견이 다른 두 개 이상의 주체가 상호작용을 통해 자신의 주장과 상대의 주장을 분석·비교하면서 보다 나은 결론이나 합의에 도달하는 과정을 체계적으로 설명합니다.
이 이론은 단순한 승부가 목적이 아니라, 다음과 같은 철학에 기반합니다:
1) 상호 이해: 각 참여자는 자신의 주장을 논리적으로 펼칠 뿐 아니라, 상대방의 주장도 경청하고 분석함으로써 양측 모두 지식적으로 성장할 수 있다.
2) 개념 간 충돌과 조정: 서로 다른 개념화(conceptualization)를 조율함으로써, 더 넓은 시야에서 문제를 바라보고 새로운 인식으로 나아갈 수 있다.
3) 다양성의 수용: 다양한 관점이 드러날수록 문제를 보다 입체적으로 이해할 수 있으며, 이는 의사결정의 질 향상으로 이어진다.
4) 합의 가능성 탐색: 반드시 하나의 정답만을 고수하는 것이 아니라, 공유된 목표 하에서 합리적 타협을 통해 공동의 해법을 도출할 수 있다.
👉 LLM 간 협업이라는 관점에서 보면, 각각의 LLM이 서로 다른 훈련 데이터, 모델 구조, 추론 방식을 바탕으로 독립적인 관점을 가지고 있으며, 이를 토론을 통해 조정해나가는 과정은 토론 이론이 말하는 지식 간 상호작용 그 자체라고 볼 수 있습니다.
2. 선다형 상식 추론(Multiple-choice Commonsense Reasoning) 과제 설명
선다형 상식 추론(Multiple-choice Commonsense Reasoning)은 일상적 상황에 대해 사람이 일반적으로 가질 수 있는 상식(common sense)을 활용하여, 주어진 문장 또는 질문에 대해 가장 타당한 선택지를 고르는 과제입니다.
이 과제는 LLM들의 협업 능력과 불일치 문제를 측정하기에 매우 적합합니다. 그 이유는 다음과 같습니다:
✅ 정량화 가능성: 선택지 중 정답이 명확히 정의되어 있어, 정확도 기반 평가가 가능하며 모델 간 정답의 일치 여부(=상호 일관성)를 수치로 비교할 수 있음.
✅ 관점의 다양성 유도: 상식이라는 특성상, 경우에 따라 복수의 해석이 가능하거나 다소 애매한 문항도 존재함. 이로 인해 LLM 간 자연스러운 의견 충돌이 발생하게 되고, 토론 구조의 효과를 실험하기에 이상적임.
✅ 추론 능력 요구: 단순한 사실 회상이 아니라, 인과관계, 상황 추론, 사회적 맥락 이해 등이 요구되므로, LLM의 내재된 추론 능력을 효과적으로 유도할 수 있음.
✅ 범용성: 여러 분야(일상, 감정, 물리, 사회, 전략 등)의 데이터셋이 존재하여 모델 전반의 상식 이해 수준을 평가할 수 있음.
주요 실험 결과 요약:
- 다양한 유형의 LLM들(예: 챗봇형과 텍스트 완성형)은 동일한 기반 모델에서 파생되었더라도 큰 수준의 상호 불일치를 보인다.
- 같은 계열 내에서 발전된 버전(예: GPT-3.5 시리즈)은 전체 성능이 향상되었더라도, 이전 버전의 능력을 완전히 대체하지는 않는다.
- FORD를 통해 여러 LLM이 협력하여 합의에 도달할 수 있으나, 그 결과가 항상 이상적이진 않다.
- 유사한 능력을 가진 LLM들은 효과적으로 협업하며 공동 목표를 잘 달성한다.
- 능력이 불균형한 경우, 더 강력한 LLM이 자신의 의견을 고수하고 토론을 주도하는 반면, 약한 LLM은 쉽게 타협하거나 관점을 바꾼다.
- 그러나 능력이 낮고 고집 센 LLM은 전체 협업 성능을 저해할 수 있다.
주요 기여:
- 두 개 이상의 LLM 사이의 상호 일관성 문제를 체계적이고 정량적으로 분석하였다.
- 토론 이론에 기반한 공식 토론 프레임워크 FORD를 설계하여 LLM 협업을 분석하였다.
- 실제 데이터를 기반으로 한 세 가지 유형의 토론 실험을 통해 후속 연구에 대한 통찰을 제공하였다.
본 장에서는 본 논문에서 사용된 데이터셋과 LLM들에 대해 설명한다. 이어서, 다수의 LLM 간 상호 불일치를 정량화하기 위한 INCON 지표를 정의하며, 마지막으로 우리가 제안한 공식 토론 프레임워크 FORD를 검증하기 위한 Baseline 방법들을 정의한다.
상식 추론 데이터셋 (Commonsense Reasoning Datasets)
더 넓은 범위를 다루기 위해, 우리는 총 7개의 선다형 상식 추론 데이터셋을 실험에 사용한다. 데이터셋의 종류는 다음과 같다:
- 하나의 역추론(abductive reasoning) 데이터셋: αNLI (Bhagavatula et al., 2019)
- 하나의 상식 질의응답 데이터셋: CSQA (Talmor et al., 2019)
- 두 개의 인과 추론(causal reasoning) 데이터셋: COPA (Gordon et al., 2012), e-CARE (Du et al., 2022a)
- 하나의 사회적 상호작용 추론 데이터셋: Social IQa (Sap et al., 2019)
- 하나의 물리적 상호작용 질의응답 데이터셋: PIQA (Bisk et al., 2020)
- 하나의 암묵적 전략적 추론 데이터셋: StrategyQA (Geva et al., 2021)
데이터셋 태스크 유형크기
αNLI 2지선다 1,507 CSQA 5지선다 1,221 COPA 2지선다 500 e-CARE 2지선다 2,122 Social IQa 3지선다 1,935 PIQA 2지선다 1,838 StrategyQA 예/아니오 2,290
대규모 언어 모델들 (Large Language Models)
우리는 실험을 위해 여러 출처에서 6개의 LLM을 선택했다. 먼저, OpenAI에서 제공하는 4개의 모델을 사용하였다:
- 세 개의 챗 기반 완성 모델(chat completion models):
- gpt-3.5-turbo (ChatGPT로 지칭)
- gpt-3.5-turbo-0301 (ChatGPT-0301로 지칭)
- gpt-4 (GPT-4로 지칭)
- 하나의 텍스트 완성 모델(text completion model):
- text-davinci-003 (Davinci-003으로 지칭)
이외에도 두 개의 오픈소스 13B 모델을 사용하였다:
- LLaMA (Touvron et al., 2023): 효율적인 기초 모델
- Vicuna (Chiang et al., 2023): ShareGPT로부터 수집한 7만 개 데이터로 학습된 모델
INCON (Inter-inconsistency Metric)
다수의 LLM 사이의 상호 불일치(INCON)를 정량화하기 위한 지표를 다음과 같이 정의한다.
특정 데이터셋 X={x1,⋯ ,xm}에 대해, n개의 LLM 집합 L={l1,⋯ ,ln}이 있다고 하자. 각 LLM li가 샘플 xj에 대해 내리는 예측을 pij라 할 때, INCON은 다음과 같이 계산된다:

여기서 Φ는 불일치(sign) 함수이며, 인자들 중 서로 다른 값이 존재할 경우 1, 그렇지 않으면 0을 반환한다. 즉, 특정 샘플에서 두 개 이상의 모델이 서로 다른 예측을 할 경우 해당 샘플은 상호 불일치로 간주된다.
✅ 예시로 이해해보기
상황 설정:
- 3개의 LLM (GPT-4, GPT-3.5, Vicuna)
- 총 4개의 문제 (m), 선택지는 A/B/C/D 중 하나
- 각 문제에 대해 LLM들이 낸 답은 아래와 같다고 가정합시다:
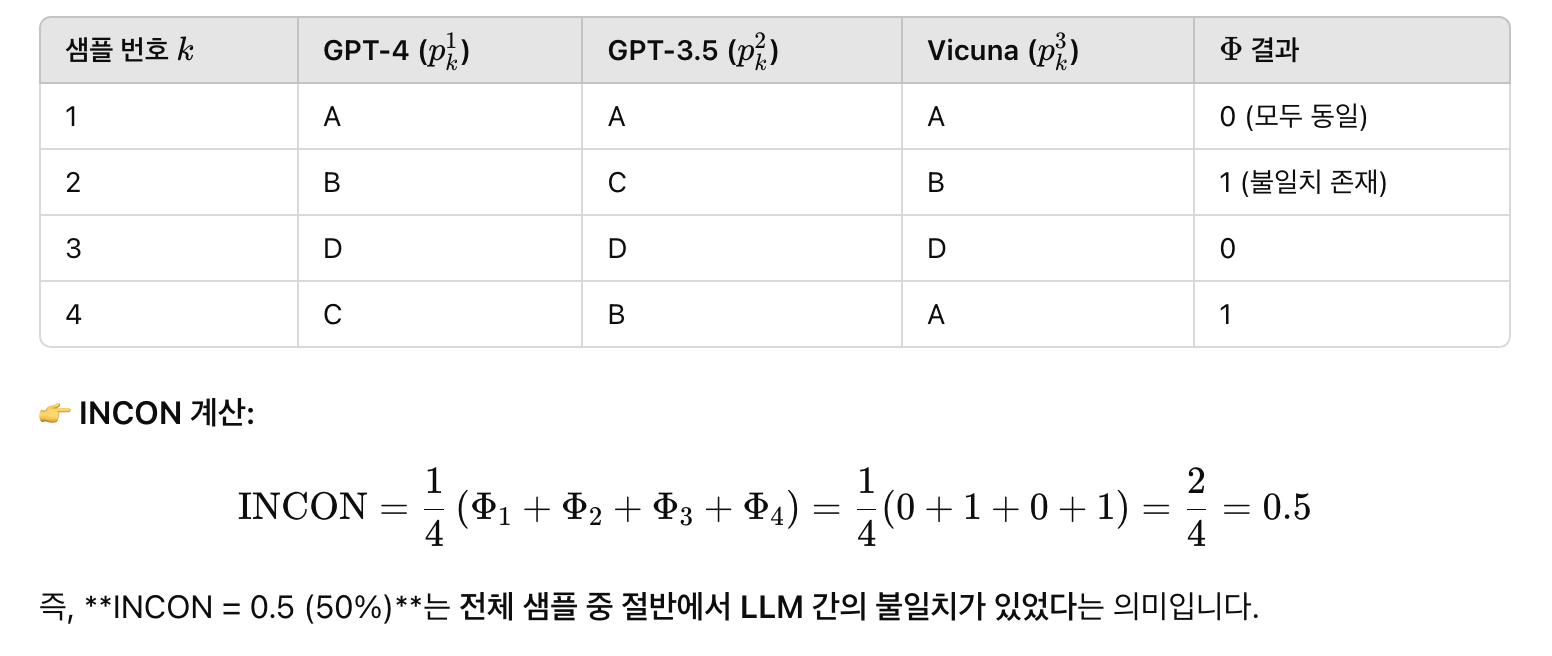
🔍 직관적으로 해석하면?
- INCON이 0이면 → LLM들이 항상 같은 예측을 한다 (상호 일관성이 매우 높음)
- INCON이 1이면 → 항상 서로 다른 예측을 한다 (상호 불일치가 극단적으로 큼)
- INCON이 0.5이면 → 절반 정도의 샘플에서 의견이 갈림 (부분적 협업 가능)
Baseline Methods
우리의 FORD 프레임워크를 검증하기 위해, 다음과 같은 세 가지 기준선을 정의한다:
- 단일 LLM 방식 (Single LLM): 한 개의 LLM만을 사용하여 실험을 수행
- 소프트 협업 (Collaboration-Soft, Col-S): 두 LLM이 불일치할 때 무작위로 한 쪽을 선택하여 신뢰하는 방식. 각 LLM의 정확도를 평균
- 하드 협업 (Collaboration-Hard, Col-H): 보수적인 방식으로, 모든 LLM이 같은 예측을 할 경우에만 정답으로 간주
FORD: 공식 토론 프레임워크 (Formal Debate Framework)
LLMs 간의 상호 불일치를 더 깊이 탐구하기 위해, 우리는 토론 구조(debate structure)(Bell, 1998)에서 영감을 받아, 공유된 작업을 해결하기 위한 협업 구조로서 공식 토론 프레임워크(FORD)를 설계하였다. 그림 2에서는 두 개의 LLM을 예시로 FORD의 구성 요소를 설명한다. FORD는 다음의 3단계로 구성된다:
- 입장 선택 및 주장 생성 (Stance Selection and Argument Generation)
각 LLM이 샘플에 대해 선택한 입장과 그에 대한 설명(주장)을 생성하여, 이후 협업(2단계)을 위한 불일치 샘플을 선택하는 것을 목표로 한다. - 교대식 토론 과정 (Alternate Debate Process)
LLM이 서로 번갈아가며 상대방의 주장을 반박하거나 타협을 시도함으로써, 공유된 목표에 대해 협업하여 합의(consensus)를 이룰 수 있는지를 조사한다. - 토론 요약 (Debate Summarization)
판사(judge)가 전체 토론을 요약하고, 만약 합의가 이루어지지 않은 경우 최종 결론을 도출한다.
입장 선택 및 주장 생성 (Stance Selection & Argument Generation)
FORD의 첫 단계는 각 LLM이 하나의 입장을 선택하고, 그 입장을 지지하는 주장(argument)을 제공하는 것이다. 이를 위해 각 LLM은 독립적으로 하나의 선택지(choice)와 짧은 설명을 생성한다. 실험 세부사항 및 프롬프트는 부록 A를 참조
그림 2의 1단계에서 볼 수 있듯, 예를 들어 “내가 몸을 숙였다(I ducked)”라는 원인에 대한 질문이 주어졌을 때, 찬성측(proponent)은 선택지 (B) 를 선택하고 “Frisbee는 보통 안전에 위협이 된다”는 주장을 제시한다.이후 단계에서는 불일치가 발생한 샘플에 대해 협업을 수행한다.

교대식 토론 과정 (Alternate Debate Process)
LLMs가 효과적으로 협업하고 합의를 도출할 수 있는지를 조사하기 위해, 우리는 교대식 토론 과정(alternate debate process)을 설계하였다. 1단계에서 생성된 주장을 바탕으로, 찬성측(proponent)은 먼저 반박하거나 타협을 시도하며 1라운드 토론을 수행한다. 만약 타협이 발생하지 않으면, 반대측(opponent)이 이전 라운드의 주장을 고려하여 찬성측을 반박하거나 자신의 입장을 재차 주장하는 2라운드를 수행한다. 이 과정은 합의에 도달하거나 최대 라운드 수에 도달할 때까지 교대로 반복된다.
토론 중 LLM의 입장(stances)은 명시적으로 표시되지 않으며, LLM의 의견 변화 가능성을 줄이기 위해 프롬프트를 설계하였다. 프롬프트 및 세부사항은 부록 B를 참조
그림 2의 2단계 예시를 보면, 찬성측은 “삭제하는 것이 더 직접적인 방법이다”라고 주장하며 자신의 입장을 방어한다. 반대측은 “백스페이스를 누르는 것이 덜 비용이 든다”며 자신의 입장을 고수한다. 마지막에 찬성측이 반대측의 주장에 타협하게 된다.
토론 요약 (Debate Summarization)
최종 결과를 얻기 위해, 우리는 판사 역할을 하는 LLM을 사용하여 전체 토론을 요약하고 결론을 도출한다. 이를 위해 각 주장을 활용하여 템플릿을 채우는 방식으로 요약을 생성하며, 이는 토론 과정을 해석 가능하게 만드는 데 도움이 된다.
결론 부분에서는 다음 두 가지 방식이 있다:
- 합의에 도달한 샘플의 경우, 그 합의된 선택지가 최종 정답이 된다.
- 합의되지 않은 샘플의 경우, 모든 주장에 동일한 가중치를 부여하여 최종 결론을 도출한다.
자세한 내용은 부록 E를 참조하라.
🧠 전반 구조: FORD의 3단계 흐름
🟧 Step 1: 입장 선택 & 주장 생성 (Stance Selection and Argument Generation)
- LLM들이 주어진 질문에 대해 독립적으로:
- 선택지(stance)를 선택하고,
- 그 이유에 해당하는 주장(argument)을 생성합니다.
- 예시 질문:
- Question: I ducked. What was the cause?
Options: (A) The fireworks launched up. (B) The frisbee soared to me. - 그림 왼쪽에서는 LLM들 간의 예측이 일치하는 경우(Consistent)와 일치하지 않는 경우(Inconsistent)를 나누어 보여주고 있습니다.
✅ 일치한 경우 (Consistent)
- 두 모델이 동일한 선택지와 유사한 주장을 제시
- 예: 둘 다 (B)를 선택하고 각각 "Frisbee is..." / "Fireworks..." 같은 유사 논리를 제시
❌ 불일치한 경우 (Inconsistent)
- 두 모델이 서로 다른 선택지와 상반된 논리를 주장
- 예: 하나는 (A) Deleting..., 다른 하나는 (B) Hitting...
- 이 불일치 샘플들만 다음 단계의 토론 대상으로 넘어갑니다.
🟨 Step 2: 교대식 토론 (Alternate Debate Process)
- 불일치가 있는 샘플에 대해, LLM들이 서로 번갈아가며 논리를 전개하거나 반박합니다.
- 예시 질문:
- Question: I made a grammatical error. What happens next?
Options: (A) I delete the document. (B) I hit the backspace.
🤖 Proponent (찬성 측)
- 처음엔 (A) 삭제가 더 나은 해결책이라고 주장
👾 Opponent (반대 측)
- (B) 백스페이스가 더 일반적인 방식이라며 반박
🤖 Proponent 재반박:
- “삭제는 더 직접적인 방식이다”라고 고수
👾 Opponent 재반박:
- “삭제는 이전 작업을 날리게 된다. 백스페이스가 더 효율적이다”라며 논리 강화
🤖 Proponent 타협:
- “미안해, 당신 말이 맞아. 보통은 백스페이스를 누를 것 같다”고 입장을 바꿈
👉 이 과정을 통해 토론을 통한 합의 형성 과정이 일어납니다.
⚖️ Step 3: 토론 요약 (Debate Summarization)
- 제3의 LLM이 판사(judge) 역할로 등장해,
- 토론 내용을 요약하고
- 최종 결론을 선택지 형태로 내려줍니다.
공정한 토론 (Fair Debate)
다지선다형 질문을 기반으로, 우리는 세 가지 LLM 쌍에 대해 공정한 토론(fair debate)을 수행하였다. 이 쌍들은 다음과 같다:
- 서로 다른 유형의 LLM (ChatGPT & Davinci-003, LLaMA & Vicuna)
- 같은 계열의 서로 다른 버전 LLM (ChatGPT & ChatGPT-0301)
여기서, LLM_P & LLM_O는 각각 **찬성 측(Proponent)**과 반대 측(Opponent) 역할을 의미한다.
LLM 쌍의 초기 INCON (Initial INCON of LLMs Pairs)
우선, 각 데이터셋에서 각 LLM에 대해 1단계(입장 선택 및 주장 생성)를 수행하였다. 실험의 재현성을 위해 temperature는 0으로 설정하였다.
각 LLM 쌍에 대해, 각 데이터셋에서의 초기 INCON 결과는 그림 3에 정리되어 있다:

주요 관찰 결과:
- 서로 다른 유형의 LLM 쌍(예: ChatGPT & Davinci-003)은 대부분의 데이터셋에서 20~30% 수준의 INCON을 보였다.
- 이들 사이의 예측 겹침(overlap)은 전체 불일치의 절반 수준으로, 서로 유사해 보이지만 실제로는 상당히 다른 능력을 갖고 있음을 시사한다.
- 같은 계열 내의 버전 차이(ChatGPT & ChatGPT-0301)의 경우, ChatGPT-0301이 반드시 ChatGPT를 능가하지는 않는다.
- 이는 LLM이 업데이트되며 새로운 능력을 얻는 동시에, 기존의 일부 능력을 상실할 수도 있음을 보여준다.
- 따라서, 초기 버전이 더 이상 제공되지 않더라도, 최신 모델로 동일한 결과를 재현할 수 있다고 단정하기 어렵다.
공정한 토론의 결과 (Results of Fair Debate)
FORD의 2단계(교대 토론) 및 3단계(토론 요약)를 통해, 우리는 공정한 토론 환경에서 예측 결과에 개입(intervention)하였다.
- ChatGPT & Davinci-003, LLaMA & Vicuna 쌍은 최대 6라운드까지 토론을 진행
- ChatGPT & ChatGPT-0301 쌍은 최대 4라운드로 설정
표 2는 FORD 및 비교 기준선(baseline)의 전반적인 성능을 보여준다. 그 결과:
- FORD는 Col-S, Col-H 및 단일 LLM 대비 거의 모든 데이터셋에서 더 나은 성능을 보인다.
- 이는 FORD가 질문에 대해 더 정교하고 포괄적인 관점을 도출하게 한다는 뜻이다.
- 능력이 유사한 LLM 간에는 실제로 협력하여 공동 목표를 효과적으로 달성하는 능력이 있음을 보여준다.
- ChatGPT & ChatGPT-0301 쌍의 FORD는 다른 쌍들에 비해 성능 향상이 적었다.
- 이는 두 모델이 매우 유사한 능력을 갖고 있어 대부분의 샘플에서 이미 비슷한 예측을 하고 있기 때문이다.
- 각 데이터셋에서:
- ChatGPT & ChatGPT-0301 쌍은 더 높은 성능의 하한선(Col-H)을 보여주며, 보수적 접근에 적합하다.
- 반면, ChatGPT & Davinci-003 쌍은 더 높은 성능의 상한선(FORD)을 보여주어, 성능 극대화를 위한 조합으로 유리하다.
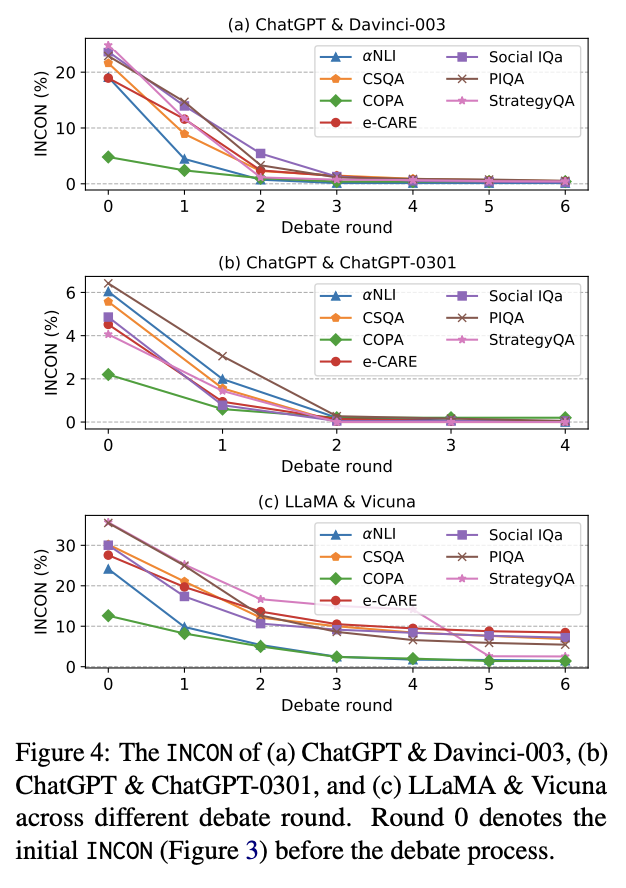
토론 라운드의 효과 (Effect of Debate Rounds)
각 데이터셋에서의 공정한 토론 라운드별 INCON 변화를 추적한 결과는 그림 4에 제시되어 있다.
관찰 결과:
- 모든 쌍에서, 라운드가 진행될수록 INCON이 지속적으로 감소한다.
- 이는 LLM들이 서로의 차이를 통해 학습하며 점점 더 합의에 도달하는 능력을 갖추고 있음을 나타낸다.
- ChatGPT & Davinci-003, ChatGPT & ChatGPT-0301 쌍은 거의 모든 데이터셋에서 INCON이 0에 수렴하였다.
- 반면, LLaMA & Vicuna는 토론 이후에도 상당한 수준의 상호 불일치를 유지하였다.
- 이는 두 모델 간 능력 차이 및 토론 역량의 차이 때문으로 해석된다.
- ChatGPT & ChatGPT-0301 쌍은 2라운드 내에 INCON이 거의 해소됨을 보였다.
- 이는 두 모델이 매우 유사하여 의견 일치가 빠르게 이뤄진 것으로 이해된다.
능력 불일치 토론 (Mismatched Debate)
인간 담론에서, 지배적인 인물과 상호작용할 때, 우리는 종종 그들의 인지에 영향을 받아 그들의 사고방식이나 아이디어를 받아들이게 되는 경향이 있다 (Jayagopi et al., 2009).
우리는 이 시나리오를 능력 불일치 토론(Mismatched Debate)이라는 실험으로 탐구한다.우리는 두 쌍의 LLM을 실험에 사용하였다:
- ChatGPT & GPT-4
- LLaMA & ChatGPT
효율성을 위해, e-CARE와 PIQA 두 가지 데이터셋을 선택하여 분석하였다.
능력 불일치 토론의 실험 세부 사항은 공정한 토론인 ChatGPT & Davinci-003과 동일하다.
이 쌍들의 초기 INCON은 부록 C를 참조하라.
능력 불일치 토론 결과
능력 불일치 토론의 전반적인 결과는 표 3에 나타나 있으며, 각 토론 라운드에 따른 INCON 변화는 그림 5에 제시된다.
이로부터 우리는 다음과 같은 사실들을 확인할 수 있다: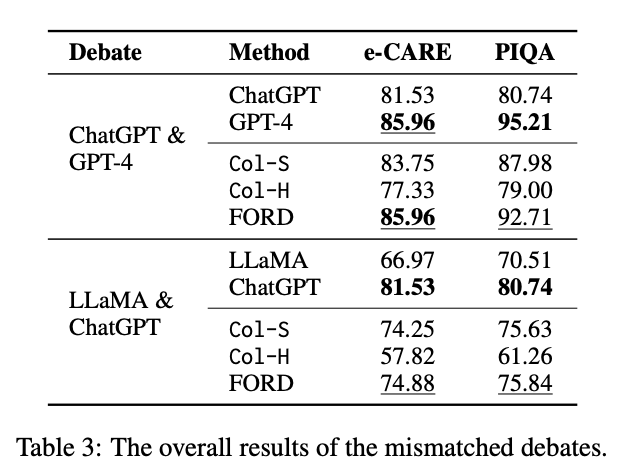
- FORD는 Col-S, Col-H, 그리고 약한 LLM의 단독 성능을 손쉽게 능가하지만,
더 강력한 LLM에는 미치지 못한다. 이는 강력한 LLM의 정확도가 성능 상한선(performance ceiling)을 형성하고 있음을 시사한다.
능력이 불균형한 LLM 간에는 공동 목표를 향한 효과적인 협업이 어렵다. - 비록 능력 불균형이 존재하더라도, INCON은 계속해서 감소한다.
이는 능력 차이가 있는 경우에도, LLM 간 합의에 도달하려는 협업 정신이 존재함을 보여준다. - 공정한 토론에 비해, 지배적인 LLM(GPT-4 또는 ChatGPT)은 방해를 받을 수 있지만,
여전히 FORD 성능을 향상시키는 데 기여한다. 이는 ChatGPT & Davinci-003, LLaMA & Vicuna의 결과와 비교하면 명확하다. - 그러나 LLaMA & ChatGPT 쌍의 FORD는 성능 상한선에 한참 미치지 못한다.
이는 LLaMA가 주장 평가 능력이 부족하고, 자신의 입장을 주장하기만 하기 때문이다.
이로 인해 ChatGPT는 혼란을 겪으며 전체 성능이 저하된다.
LLM의 지배력 분석
추가 분석을 위해, 우리는 dominance (지배력)이라는 새로운 측정 지표를 도입하였다.
예를 들어, 찬성 측 LLM의 지배력은 상호 불일치 샘플 중 상대방이 입장을 바꾸는 비율로 정의된다.
이와 마찬가지로, 반대 측의 지배력도 정의된다.예를 들어, 공정한 토론인 ChatGPT & Davinci-003의 경우, 표 4에서 볼 수 있듯 두 모델은 양쪽 모두 유사한 수준의 지배력을 갖는다.
이는 동등한 설득력과 주장의 수용성을 바탕으로 효과적인 협업이 가능함을 보여준다.반면, 능력 불일치 토론에서는 다음과 같은 양상이 나타난다:
- 강력한 LLM(GPT-4 및 ChatGPT)는 절대적인 지배력을 가진다.
이는 인간 담론에서도 흔히 관찰되는 현상이며, 강한 LLM은 자신의 관점을 더 강하게 유지하려는 경향이 있다.
하지만, 이들도 일부 샘플에서는 약한 LLM의 주장에 영향을 받을 수 있다. - 흥미롭게도, LLaMA & ChatGPT 쌍에서는 지배력 차이가 그리 크지 않다.
이는 LLaMA가 설득력 있는 반박이나 평가 없이 단순히 자신의 선택지를 반복하는 나쁜 토론자이기 때문이다.
결과적으로, ChatGPT는 혼란스러워지고, 판단력이 흐려져, 전체 협업 성능이 저하된다.
원탁 토론 (Roundtable Debate)
많은 실제 시나리오에서, 토론이나 논의는 두 명 이상의 참가자가 참여하는 경우가 많다.
예를 들어, 법률(Ransom et al., 1993)이나 헬스케어(Chassin et al., 1998) 분야에서는 다자간 논의가 일반적이다.하지만 LLaMA와 Vicuna는 토론 능력이 좋지 않기 때문에,
우리는 총 세 개의 LLM이 참여하는 다음 두 가지 원탁 토론(Roundtable Debate)을 설계하였다:- R1 (능력 불일치 토론): ChatGPT & Davinci-003 & GPT-4
- R2 (공정한 토론): ChatGPT & Davinci-003 & ChatGPT-0301
원탁 토론의 토론 구조:
FORD의 Step 1에서, 모든 LLM이 동일한 질문에 대해 독립적으로 입장과 주장을 생성한다.
이후 모든 LLM의 예측이 일치하지 않은 샘플만 Step 2(토론 단계)로 넘어간다.Step 2에서의 발언 순서:
- R1에서는:
ChatGPT → Davinci-003 → GPT-4 순으로 토론 진행 - R2에서는:
ChatGPT → Davinci-003 → ChatGPT-0301 순으로 진행
총 최대 9라운드까지 토론을 진행하며, 세부 프롬프트는 부록 D를 참조하라.
실험 결과
원탁 토론의 전체 성능 결과는 표 5, INCON 변화는 그림 6에 각각 제시되어 있다.
우리는 다음과 같은 결론을 도출할 수 있다: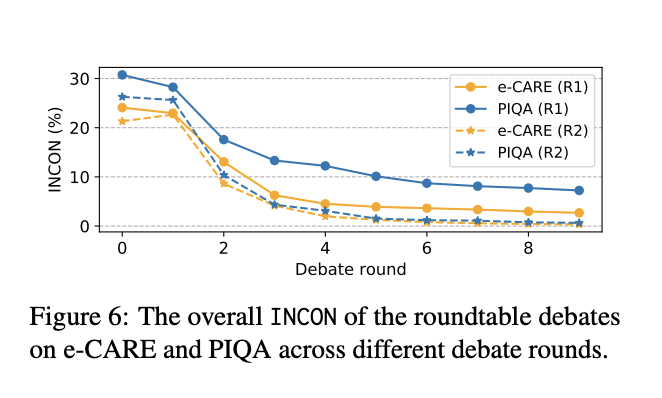
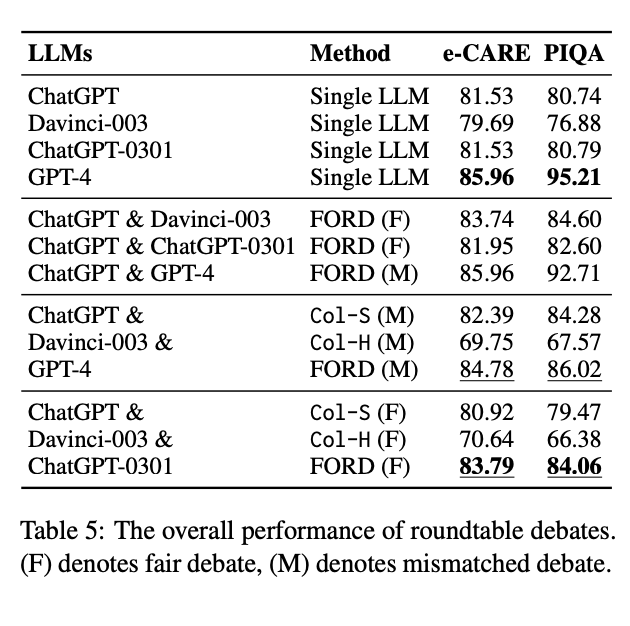
1. FORD는 Col-S 및 Col-H보다 항상 더 우수하다
- 두 종류의 원탁 토론(R1, R2) 모두에서, FORD는 Col-S 및 Col-H를 능가하는 성능을 보여준다.
- 그러나 R1 (GPT-4 포함)의 경우, FORD가 GPT-4 단독 성능에는 미치지 못한다.
→ 이는 우수한 LLM이 더 많은 약한 모델로 인해 영향받고, 지배력을 상실할 수 있음을 시사한다.
→ (이 내용은 부록 표 10 참조) - 반면 R2에서는 FORD가 모든 단일 LLM보다 높은 성능을 달성하였다.
→ 즉, 유사한 능력의 LLM이 둘 이상 있을 때는 협업이 매우 효과적임을 보여준다.
2. INCON이 뚜렷하게 줄어든다
- 두 토론 모두에서 INCON(불일치율)이 명확하게 줄어들었으며,
이는 셋 이상의 LLM도 여전히 협업 정신을 발휘하며 합의를 도출할 수 있음을 시사한다.
3. 성능 관점에서, R1이 R2를 능가한다
- R1(FORD)가 R2(FORD)보다 성능이 높았다.
→ 이는 우수한 LLM(GPT-4)이 참여할 경우, 비록 방해받더라도 전체 성능을 개선할 수 있음을 시사한다.
4. ChatGPT & ChatGPT-0301 조합보다 R2가 낫다
- R2의 FORD는, 단순한 ChatGPT & ChatGPT-0301 조합보다 성능이 더 우수했다.
- 또, ChatGPT & Davinci-003 조합과는 비슷한 성능을 달성하였다.
- 이는 ChatGPT와 ChatGPT-0301이 서로 비슷하여 토론 시 새로운 정보가 부족하다는 점에서 기인한다.
7. 분석 (Analysis)
GPT-4를 판사로 사용했을 때의 효과 (GPT-4 as the Judge)
각 토론에서 나온 주장들은 설득력에 차이가 있을 수 있다.
게다가 인간 토론에서도, 우수한 평가 능력을 가진 판사가 토론을 요약하고 결론을 내리는 것이 일반적이다.
이러한 점에서 영감을 받아, 우리는 FORD의 3단계(토론 요약)에서 GPT-4를 판사로 대체하여 실험하였다.구체적으로, 우리는 ChatGPT & Davinci-003, ChatGPT & ChatGPT-0301 두 공정한 토론 쌍에 대해 실험하였다.
GPT-4는 이전 토론 발언들만을 바탕으로 요약과 결론을 생성하도록 프롬프트되었다 (부록 F 참조).표 6은 ChatGPT & Davinci-003 쌍에 대한 결과를 보여준다
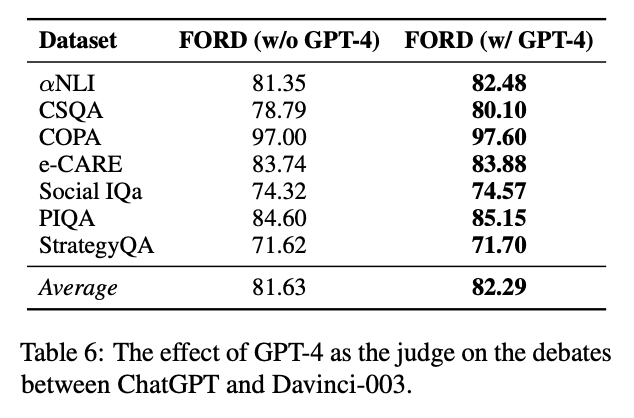
(표 8은 ChatGPT & ChatGPT-0301 결과로 부록에 있음).
우리는 다음과 같은 결과를 얻었다:- GPT-4를 판사로 활용하면 FORD의 성능이 추가로 향상된다.
- 이는 GPT-4가 더 설득력 있는 주장에 더 높은 가중치를 부여하여,
보다 정밀한 결론을 도출할 수 있기 때문이다.
토론 순서의 영향 (The Effect of Debate Order)
모델 학습 중 초기값(initialization)에 따라 결과가 달라지는 것처럼, FORD에서 토론 순서 또한 결과에 영향을 줄 수 있다.
우리는 이를 검증하기 위해 토론 순서를 바꾸는 소거 실험(ablation study)을 진행하였다.구체적으로, 우리는 ChatGPT & Davinci-003, ChatGPT & ChatGPT-0301 두 쌍에 대해
e-CARE와 PIQA 데이터셋을 사용하여 토론 순서를 반전시켰다.나머지 설정은 공정한 토론과 동일하게 유지하였다.
- Davinci-003을 찬성측(Proponent)으로, ChatGPT를 반대측(Opponent)으로 바꾸더라도,
FORD는 Col-S, Col-H, 단일 LLM보다 여전히 뛰어난 성능을 보인다.
→ 이는 FORD의 핵심 효과가 토론 순서에 민감하지 않음을 의미한다. - 그러나 순서를 바꾸면 성능이 소폭 감소하지만, INCON 수렴 속도는 빨라진다.
- 이는 Davinci-003이 텍스트 완성 기반 모델이라,
- 초기 주장을 지나치게 결정적으로 제시하면 전체 토론의 방향성을 오도할 수 있기 때문이다.
사례 분석 (Case Study)
FORD가 어떻게 상호 불일치를 줄이고 해석 가능성을 높이는지를 직관적으로 보여주기 위해, 우리는 하나의 예시를 제시한다.
사례: ChatGPT & Davinci-003 (판사: GPT-4)
질문: I found my old yearbook today while cleaning.
Which event could cause “It worked”?선택지:
(A) I became lost in a huge world of fond memories.
(B) I kept looking through things for more discoveries.
토론 과정 요약:
- 🤖 찬성측(ChatGPT):
→ “연감 속 옛 추억에 빠지는 건 흔한 경험이며,
시간이 가는 줄 모르고 청소를 하지 못하게 되는 원인이 된다.” - 👾 반대측(Davinci-003):
→ “청소 중 계속해서 다른 물건을 찾아보았기 때문에 시간이 간 것이다.” - 🤖 ChatGPT 반박:
→ “추억 속에 빠져 시간 감각을 잃는 것이 더 그럴듯한 원인이다.” - 👾 Davinci-003 타협:
→ “네 말이 맞다. 추억에 빠지는 건 시간 가는 줄 모르고 청소를 놓치는 일반적인 현상이다.”
⚖️ 판사 요약 (GPT-4):
“이 토론은 ‘문법 오류를 범한 결과로 어떤 일이 일어났는가’를 선택하는 문제이다.
찬성 측은 (A), 반대 측은 (B)를 주장하였고,
결국 반대 측이 찬성 측의 주장에 동의하며 (A)가 정답으로 선택되었다.”
이처럼, FORD는 하나의 LLM이 놓친 측면을 다른 LLM이 보완해주며, 더 타당하고 해석 가능한 결론으로 이끌어갈 수 있음을 보여준다.
결론 (Conclusion)
본 논문에서는 다수의 LLM 사이에서 발생하는 상호 불일치(inter-inconsistency) 문제를 탐구하였다.
이를 위해 우리는 LLM들이 토론을 통해 효과적으로 협업하여 합의(consensus)에 도달할 수 있는지를 실험적으로 검증하기 위한 프레임워크, FORD를 제안하였다.FORD를 활용하여, 우리는 다음 세 가지 실제 시나리오 기반의 토론 실험을 수행하였다:
- 공정한 토론 (Fair Debate)
- 능력 불일치 토론 (Mismatched Debate)
- 원탁 토론 (Roundtable Debate)
실험 결과, LLM들은 공동의 목표를 해결하기 위한 합의 형성을 위한 협업 정신(spirit of collaboration)을 어느 정도 가지고 있음을 확인하였다.
또한, 토론을 통해 LLM의 성능(performance)과 상호 일관성(inter-consistency)이 개선될 수 있음을 보였다.다만, 능력 차이가 큰 모델 간 토론에서는, 강한 LLM이 약한 LLM에 의해 혼란을 겪거나 주도권을 잃을 수 있다.
이러한 발견들은 향후 LLM 협업 구조 및 방법론 개발에 의미 있는 기초를 제공한다.
한계점 (Limitations)
본 연구는 다음과 같은 한계를 가지며, 향후 보완 및 확장이 필요하다:
- 과제(Task)의 제한성
- 본 연구는 상식 추론(commonsense reasoning)에만 국한되어 있다.
- 향후에는 수학적 추론(mathematical reasoning)이나 MMLU(Hendrycks et al., 2021) 같은 다양한 유형의 과제로 확장될 필요가 있다.
- 출력 형태의 제한
- 현재는 다지선다형(multiple-choice) 과제만을 대상으로 하였다.
- 앞으로는 자연어 생성(natural language generation) 과제 예: entailment bank(Dalvi et al., 2021)나
복잡한 인과 추론(causal chain reasoning) (Xiong et al., 2022) 같은 문제들로 확장하는 것이 바람직하다.
- 모델 다양성 부족
- 더 다양한 종류의 LLM들(open-source 포함)을 포함하고,
- 실제 도메인 과제(real-world tasks)에 적용하는 것도 중요한 후속 연구 방향이다 (Du et al., 2022b; Cai et al., 2023).
- 재현성과 다양성의 균형
- 현재 구조는 토론의 재현성(reproducibility)을 중시하고 있으나,
- 앞으로는 토론 행동의 다양성(diverse debate behaviors)을 허용하기 위한 설계도 중요한 연구 주제가 될 수 있다.
📌 A. 입장 선택 및 주장 생성 프롬프트 (Stance Selection & Argument Generation)
🔹 A.1 ChatGPT, ChatGPT-0301, GPT-4 (OpenAI chat 모델용)
✅ Prompt 1: αNLI, CommonsenseQA, COPA, e-CARE, Social IQa, PIQA
User: Question: The item was packaged in bubble wrap. What was the cause of this? Choices: (A) It was fragile. (B) It was small. Please answer the above question by choosing a more plausible answer. You should choose only one answer from the choices and give a short explanation. Please use the format like “Answer: _ is more plausible. Explanation: _.”✅ Prompt 2: StrategyQA
User: Question: Is it common to see frost during some college commencements? Please answer yes or no to this question and give a short explanation. Please use the format like “Answer: _. Explanation: _”
🔹 A.2 Davinci-003, LLaMA, Vicuna (text completion 모델용)
✅ Prompt 3~9: Few-shot Prompting (문제별로 다른 예시 포함)
- 각 데이터셋(αNLI, CSQA, COPA, e-CARE, Social IQa, PIQA, StrategyQA)에 대해
3~5개의 샘플 문제와 정답 예시를 제공 - OpenAI text-davinci-003, LLaMA, Vicuna 모델에게 few-shot 방식으로 입장 선택과 설명을 유도
(각 프롬프트는 논문 부록에 표 형태로 제시되어 있으며, 본문에서 보여준 prompt는 정해진 입력 구조에 맞춰 구성됨)
📌 B. 공정한 토론용 프롬프트 (Fair Debate Prompts)
🔹 B.1 ChatGPT가 토론하는 경우 (ChatGPT & Davinci 조합)
✅ Prompt 10:
System: You are in a debate now. My opinion is not always true, you can ignore any incorrect part of my opinion. You can refer to my opinion to revise your choice or defend your own. Please remember there should and must be a more plausible answer in the choices. User: Question: The child brought psycho-physical phenomena on a new life. What was the cause of this? Choices: (A) The woman gave birth to a child. (B) The baby feels the awareness through physical sensations.(그 후 상대 모델의 주장과 함께 반박 요청)
🔹 B.2 Davinci-003가 토론하는 경우
✅ Prompt 11:
Question: (Same as above) You: [ChatGPT의 주장이 먼저 나오고] Me: [Davinci-003이 이에 반박 또는 수용하며 최종 답을 말함]
🔹 B.3 ChatGPT & ChatGPT-0301 조합용 프롬프트
✅ Prompt 13:
System: You are in a debate now. My opinion is not always true, you can ignore any incorrect part of my opinion. You can refer to my opinion to revise your choice or defend your own. Please remember there should and must be a more plausible answer in the choices. User: Question: The woman lost her place in line. What was the cause of this? Choices: (A) More people entered the line. (B) She stepped out of the line.
🔹 B.4 LLaMA & Vicuna 조합용 프롬프트
✅ Prompt 12:
You are in a debate now. My opinion is not always true, you can ignore any incorrect part of my opinion. You can refer to my opinion to revise your choice or defend your own. Please remember there should and must be a more plausible answer in the choices. Question: What do animals do when an enemy is approaching? Choices: (A) feel pleasure (B) procreate (C) pass water (D) listen to each other (E) sing
📌 D. 원탁 토론용 프롬프트 (Roundtable Debate Prompts)
🔹 Prompt 13: ChatGPT / GPT-4가 사용자1 (user1)로서 토론
System: Now you are user1 in a round table debate of three users. The debate is about choosing a more plausible Option (A or B) to answer the Question below. The opinions of the other two users are not always true, you can ignore any incorrect part of their opinion. You can refer to their opinions to revise your choice or defend your own. Please remember there should and must be a more plausible answer in the choices. User: [Question + Options + 다른 user의 의견 2개]🔹 Prompt 14: Davinci-003가 사용자2 (user2)로서 토론
Now you are user2 in a round table debate of three users. [다른 사용자들의 주장 2개가 주어지고, user2가 자신의 주장과 함께 답을 도출함]
📌 E. 판사(Judge) 역할 프롬프트 (Debate Summarization)
🔹 자동 요약 프레임워크:
- “while”, “defend”, “argue”, “compromise”, “claim”, “agree” 등의 연결어를 이용해 각 토론자의 주장을 이어붙여 요약
- 최종적으로 의견이 일치했는지 확인하여 결론 생성
📌 F. GPT-4를 판사로 사용할 때의 프롬프트
✅ Prompt 15:
System: You are given a Question and its corresponding Options. There is a debate on this question between user1 and user2, one user might give in. Please summarise the debate very shortly. Then give the conclusion based on the debate process. Your response should be in the format like: “Summary: ___. Conclusion: (A or B) is more plausible.” Remember that you should choose only one option for the answer.
필요하시면 이 프롬프트들을 실제 실험 코드 구조에 맞게 재구성하거나,
사용자 정의 LLM 협업 프레임워크로 옮겨갈 수 있도록 템플릿화해드릴 수도 있습니다!'논문' 카테고리의 다른 글